 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiSkill3: GPU Parallelized Robotics Simulation and Rendering for Generalizable Embodied AI
Oct 01, 2024



Simulation has enabled unprecedented compute-scalable approaches to robot learning. However, many existing simulation frameworks typically support a narrow range of scenes/tasks and lack features critical for scaling generalizable robotics and sim2real. We introduce and open source ManiSkill3, the fastest state-visual GPU parallelized robotics simulator with contact-rich physics targeting generalizable manipulation. ManiSkill3 supports GPU parallelization of many aspects including simulation+rendering, heterogeneous simulation, pointclouds/voxels visual input, and more. Simulation with rendering on ManiSkill3 can run 10-1000x faster with 2-3x less GPU memory usage than other platforms, achieving up to 30,000+ FPS in benchmarked environments due to minimal python/pytorch overhead in the system, simulation on the GPU, and the use of the SAPIEN parallel rendering system. Tasks that used to take hours to train can now take minutes. We further provide the most comprehensive range of GPU parallelized environments/tasks spanning 12 distinct domains including but not limited to mobile manipulation for tasks such as drawing, humanoids, and dextrous manipulation in realistic scenes designed by artists or real-world digital twins. In addition, millions of demonstration frames are provided from motion planning, RL, and teleoperation. ManiSkill3 also provides a comprehensive set of baselines that span popular RL and learning-from-demonstrations algorithms.
Point-SAM: Promptable 3D Segmentation Model for Point Clouds
Jun 25, 2024The development of 2D foundation models for image segmentation has been significantly advanced by the Segment Anything Model (SAM). However, achieving similar success in 3D models remains a challenge due to issues such as non-unified data formats, lightweight models, and the scarcity of labeled data with diverse masks. To this end, we propose a 3D promptable segmentation model (Point-SAM) focusing on point clouds. Our approach utilizes a transformer-based method, extending SAM to the 3D domain. We leverage part-level and object-level annotations and introduce a data engine to generate pseudo labels from SAM, thereby distilling 2D knowledge into our 3D model. Our model outperforms state-of-the-art models on several indoor and outdoor benchmarks and demonstrates a variety of applications, such as 3D annotation. Codes and demo can be found at https://github.com/zyc00/Point-SAM.
Part-Guided 3D RL for Sim2Real Articulated Object Manipulation
Apr 26, 2024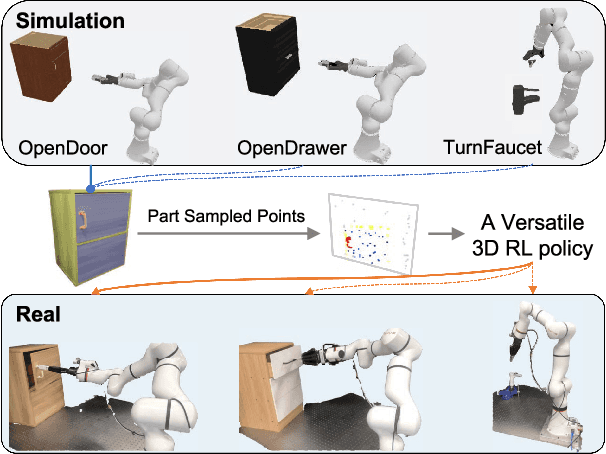

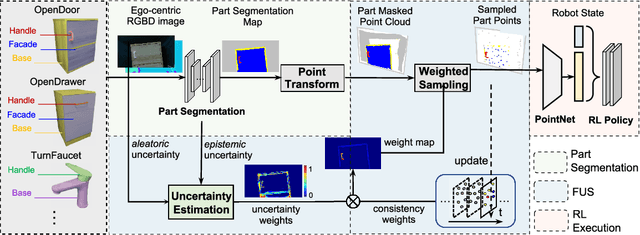

Manipulating unseen articulated objects through visual feedback is a critical but challenging task for real robots. Existing learning-based solutions mainly focus on visual affordance learning or other pre-trained visual models to guide manipulation policies, which face challenges for novel instances in real-world scenarios. In this paper, we propose a novel part-guided 3D RL framework, which can learn to manipulate articulated objects without demonstrations. We combine the strengths of 2D segmentation and 3D RL to improve the efficiency of RL policy training. To improve the stability of the policy on real robots, we design a Frame-consistent Uncertainty-aware Sampling (FUS) strategy to get a condensed and hierarchical 3D representation. In addition, a single versatile RL policy can be trained on multiple articulated object manipulation tasks simultaneously in simulation and shows great generalizability to novel categories and instances. Experimental results demonstrate the effectiveness of our framework in both simulation and real-world settings. Our code is available at https://github.com/THU-VCLab/Part-Guided-3D-RL-for-Sim2Real-Articulated-Object-Manipulation.
Robo360: A 3D Omnispective Multi-Material Robotic Manipulation Dataset
Dec 09, 2023
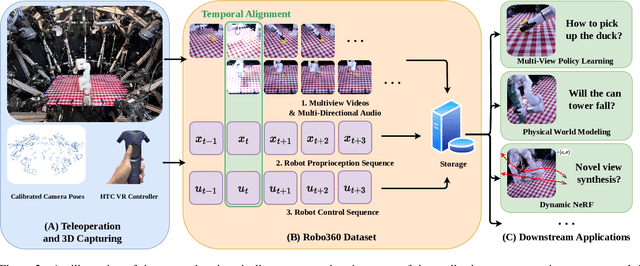
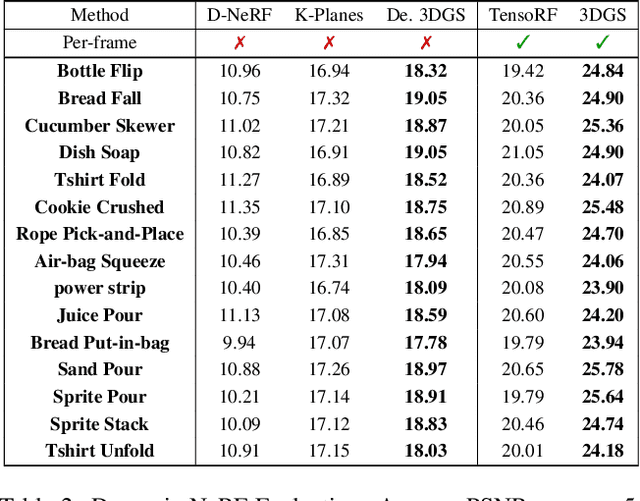

Building robots that can automate labor-intensive tasks has long been the core motivation behind the advancements in computer vision and the robotics community. Recent interest in leveraging 3D algorithms, particularly neural fields, has led to advancements in robot perception and physical understanding in manipulation scenarios. However, the real world's complexity poses significant challenges. To tackle these challenges, we present Robo360, a dataset that features robotic manipulation with a dense view coverage, which enables high-quality 3D neural representation learning, and a diverse set of objects with various physical and optical properties and facilitates research in various object manipulation and physical world modeling tasks. We confirm the effectiveness of our dataset using existing dynamic NeRF and evaluate its potential in learning multi-view policies. We hope that Robo360 can open new research directions yet to be explored at the intersection of understanding the physical world in 3D and robot control.
FG-NeRF: Flow-GAN based Probabilistic Neural Radiance Field for Independence-Assumption-Free Uncertainty Estimation
Oct 04, 2023
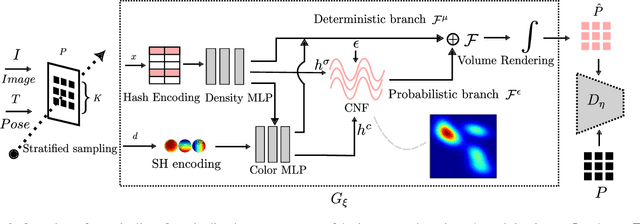


Neural radiance fields with stochasticity have garnered significant interest by enabling the sampling of plausible radiance fields and quantifying uncertainty for downstream tasks. Existing works rely on the independence assumption of points in the radiance field or the pixels in input views to obtain tractable forms of the probability density function. However, this assumption inadvertently impacts performance when dealing with intricate geometry and texture. In this work, we propose an independence-assumption-free probabilistic neural radiance field based on Flow-GAN. By combining the generative capability of adversarial learning and the powerful expressivity of normalizing flow, our method explicitly models the density-radiance distribution of the whole scene. We represent our probabilistic NeRF as a mean-shifted probabilistic residual neural model. Our model is trained without an explicit likelihood function, thereby avoiding the independence assumption. Specifically, We downsample the training images with different strides and centers to form fixed-size patches which are used to train the generator with patch-based adversarial learning. Through extensive experiments, our method demonstrates state-of-the-art performance by predicting lower rendering errors and more reliable uncertainty on both synthetic and real-world datasets.
NeuManifold: Neural Watertight Manifold Reconstruction with Efficient and High-Quality Rendering Support
May 26, 2023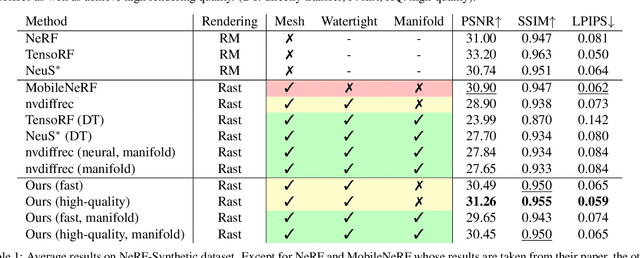
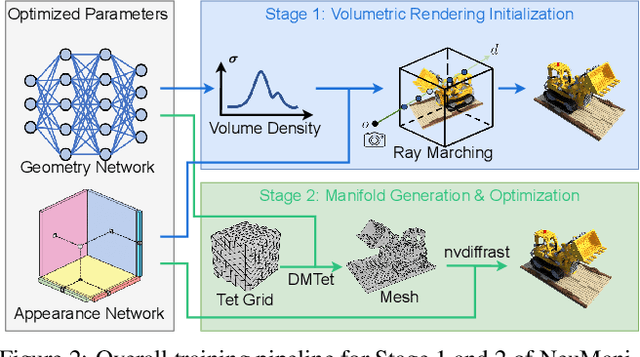


We present a method for generating high-quality watertight manifold meshes from multi-view input images. Existing volumetric rendering methods are robust in optimization but tend to generate noisy meshes with poor topology. Differentiable rasterization-based methods can generate high-quality meshes but are sensitive to initialization. Our method combines the benefits of both worlds; we take the geometry initialization obtained from neural volumetric fields, and further optimize the geometry as well as a compact neural texture representation with differentiable rasterizers. Through extensive experiments, we demonstrate that our method can generate accurate mesh reconstructions with faithful appearance that are comparable to previous volume rendering methods while being an order of magnitude faster in rendering. We also show that our generated mesh and neural texture reconstruction is compatible with existing graphics pipelines and enables downstream 3D applications such as simulation. Project page: https://sarahweiii.github.io/neumanifold/
ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills
Feb 09, 2023Generalizable manipulation skills, which can be composed to tackle long-horizon and complex daily chores, are one of the cornerstones of Embodied AI. However, existing benchmarks, mostly composed of a suite of simulatable environments, are insufficient to push cutting-edge research works because they lack object-level topological and geometric variations, are not based on fully dynamic simulation, or are short of native support for multiple types of manipulation tasks. To this end, we present ManiSkill2, the next generation of the SAPIEN ManiSkill benchmark, to address critical pain points often encountered by researchers when using benchmarks for generalizable manipulation skills. ManiSkill2 includes 20 manipulation task families with 2000+ object models and 4M+ demonstration frames, which cover stationary/mobile-base, single/dual-arm, and rigid/soft-body manipulation tasks with 2D/3D-input data simulated by fully dynamic engines. It defines a unified interface and evaluation protocol to support a wide range of algorithms (e.g., classic sense-plan-act, RL, IL), visual observations (point cloud, RGBD), and controllers (e.g., action type and parameterization). Moreover, it empowers fast visual input learning algorithms so that a CNN-based policy can collect samples at about 2000 FPS with 1 GPU and 16 processes on a regular workstation. It implements a render server infrastructure to allow sharing rendering resources across all environments, thereby significantly reducing memory usage. We open-source all codes of our benchmark (simulator, environments, and baselines) and host an online challenge open to interdisciplinary researchers.
Close the Visual Domain Gap by Physics-Grounded Active Stereovision Depth Sensor Simulation
Feb 07, 2022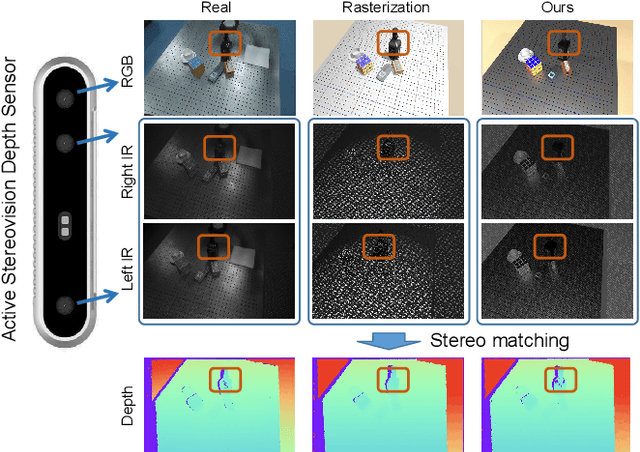
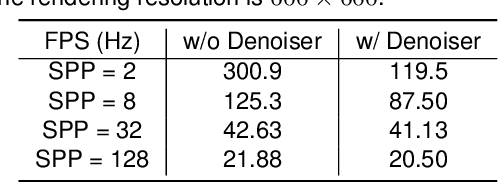
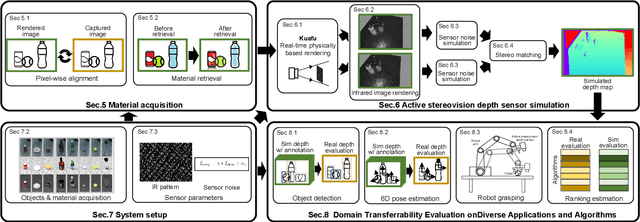
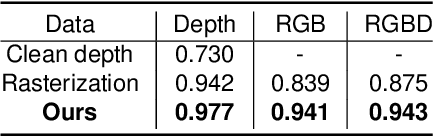
In this paper, we focus on the simulation of active stereovision depth sensors, which are popular in both academic and industry communities. Inspired by the underlying mechanism of the sensors, we designed a fully physics-grounded simulation pipeline, which includes material acquisition, ray tracing based infrared (IR) image rendering, IR noise simulation, and depth estimation. The pipeline is able to generate depth maps with material-dependent error patterns similar to a real depth sensor. We conduct extensive experiments to show that perception algorithms and reinforcement learning policies trained in our simulation platform could transfer well to real world test cases without any fine-tuning. Furthermore, due to the high degree of realism of this simulation, our depth sensor simulator can be used as a convenient testbed to evaluate the algorithm performance in the real world, which will largely reduce the human effort in developing robotic algorithms. The entire pipeline has been integrated into the SAPIEN simulator and is open-sourced to promote the research of vision and robotics communities.
ManiSkill: Learning-from-Demonstrations Benchmark for Generalizable Manipulation Skills
Aug 09, 2021
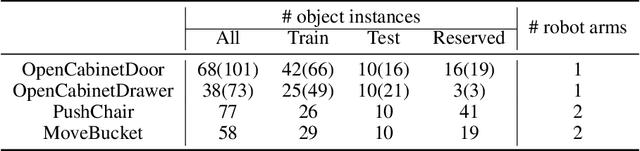
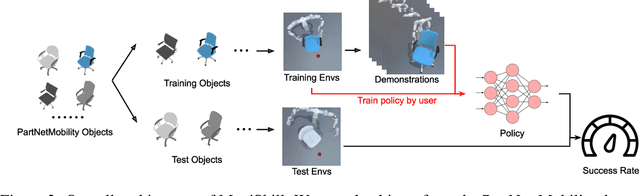

Learning generalizable manipulation skills is central for robots to achieve task automation in environments with endless scene and object variations. However, existing robot learning environments are limited in both scale and diversity of 3D assets (especially of articulated objects), making it difficult to train and evaluate the generalization ability of agents over novel objects. In this work, we focus on object-level generalization and propose SAPIEN Manipulation Skill Benchmark (abbreviated as ManiSkill), a large-scale learning-from-demonstrations benchmark for articulated object manipulation with 3D visual input (point cloud and RGB-D image). ManiSkill supports object-level variations by utilizing a rich and diverse set of articulated objects, and each task is carefully designed for learning manipulations on a single category of objects. We equip ManiSkill with a large number of high-quality demonstrations to facilitate learning-from-demonstrations approaches and perform evaluations on baseline algorithms. We believe that ManiSkill can encourage the robot learning community to explore more on learning generalizable object manipulation skills.
O2O-Afford: Annotation-Free Large-Scale Object-Object Affordance Learning
Jun 29, 2021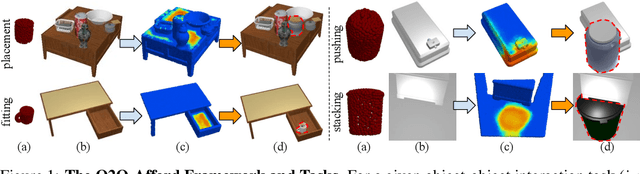
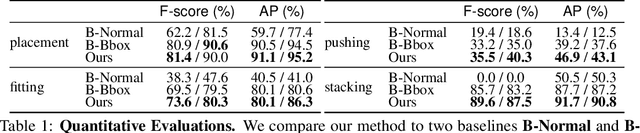
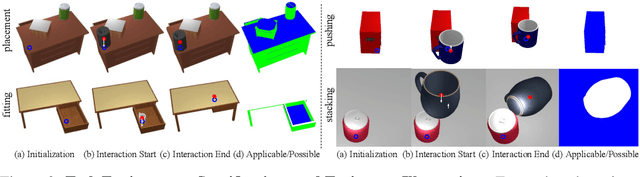

Contrary to the vast literature in modeling, perceiving, and understanding agent-object (e.g., human-object, hand-object, robot-object) interaction in computer vision and robotics, very few past works have studied the task of object-object interaction, which also plays an important role in robotic manipulation and planning tasks. There is a rich space of object-object interaction scenarios in our daily life, such as placing an object on a messy tabletop, fitting an object inside a drawer, pushing an object using a tool, etc. In this paper, we propose a unified affordance learning framework to learn object-object interaction for various tasks. By constructing four object-object interaction task environments using physical simulation (SAPIEN) and thousands of ShapeNet models with rich geometric diversity, we are able to conduct large-scale object-object affordance learning without the need for human annotations or demonstrations. At the core of technical contribution, we propose an object-kernel point convolution network to reason about detailed interaction between two objects. Experiments on large-scale synthetic data and real-world data prove the effectiveness of the proposed approach. Please refer to the project webpage for code, data, video, and more materials: https://cs.stanford.edu/~kaichun/o2oafford