 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeManiSkill: Learning-from-Demonstrations Benchmark for Generalizable Manipulation Skills
Aug 09, 2021
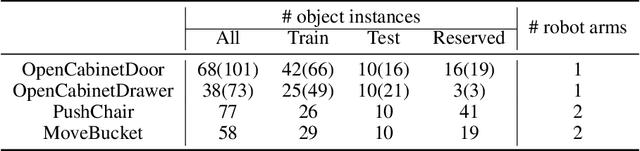
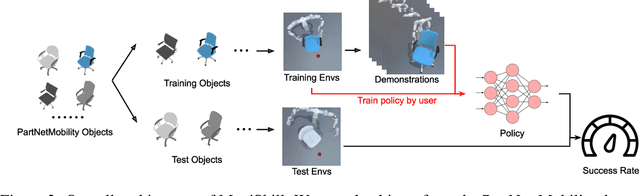

Learning generalizable manipulation skills is central for robots to achieve task automation in environments with endless scene and object variations. However, existing robot learning environments are limited in both scale and diversity of 3D assets (especially of articulated objects), making it difficult to train and evaluate the generalization ability of agents over novel objects. In this work, we focus on object-level generalization and propose SAPIEN Manipulation Skill Benchmark (abbreviated as ManiSkill), a large-scale learning-from-demonstrations benchmark for articulated object manipulation with 3D visual input (point cloud and RGB-D image). ManiSkill supports object-level variations by utilizing a rich and diverse set of articulated objects, and each task is carefully designed for learning manipulations on a single category of objects. We equip ManiSkill with a large number of high-quality demonstrations to facilitate learning-from-demonstrations approaches and perform evaluations on baseline algorithms. We believe that ManiSkill can encourage the robot learning community to explore more on learning generalizable object manipulation skills.
Fully Parameterized Quantile Function for Distributional Reinforcement Learning
Nov 16, 2019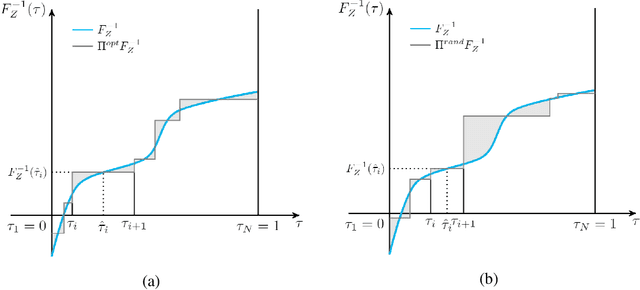
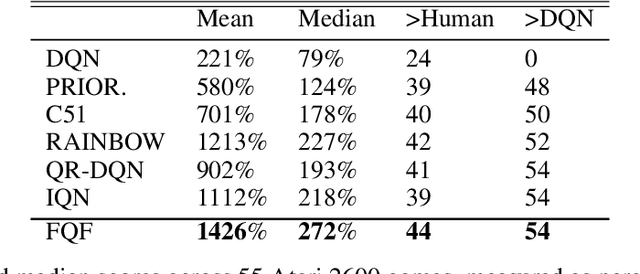
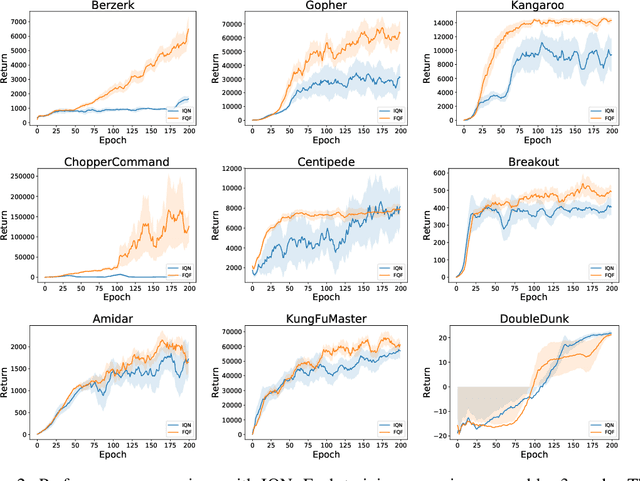

Distributional Reinforcement Learning (RL) differs from traditional RL in that, rather than the expectation of total returns, it estimates distributions and has achieved state-of-the-art performance on Atari Games. The key challenge in practical distributional RL algorithms lies in how to parameterize estimated distributions so as to better approximate the true continuous distribution. Existing distributional RL algorithms parameterize either the probability side or the return value side of the distribution function, leaving the other side uniformly fixed as in C51, QR-DQN or randomly sampled as in IQN. In this paper, we propose fully parameterized quantile function that parameterizes both the quantile fraction axis (i.e., the x-axis) and the value axis (i.e., y-axis) for distributional RL. Our algorithm contains a fraction proposal network that generates a discrete set of quantile fractions and a quantile value network that gives corresponding quantile values. The two networks are jointly trained to find the best approximation of the true distribution. Experiments on 55 Atari Games show that our algorithm significantly outperforms existing distributional RL algorithms and creates a new record for the Atari Learning Environment for non-distributed agents.
Distributional Reward Decomposition for Reinforcement Learning
Nov 06, 2019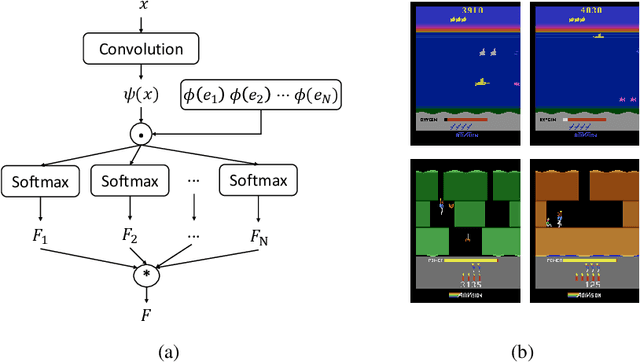
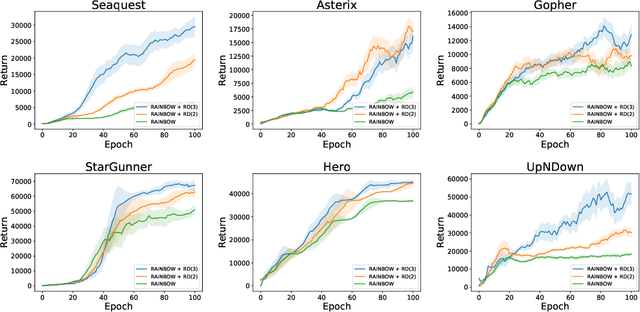
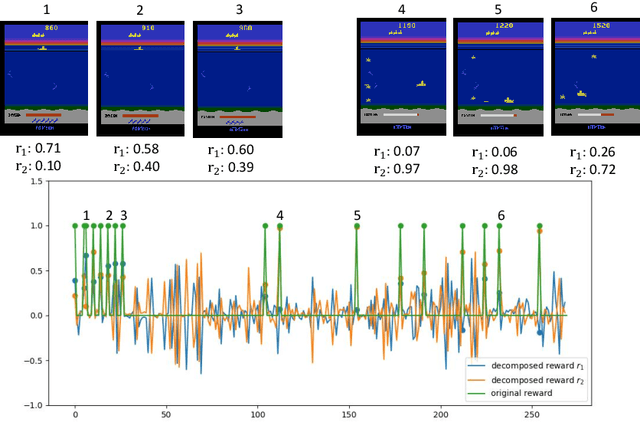
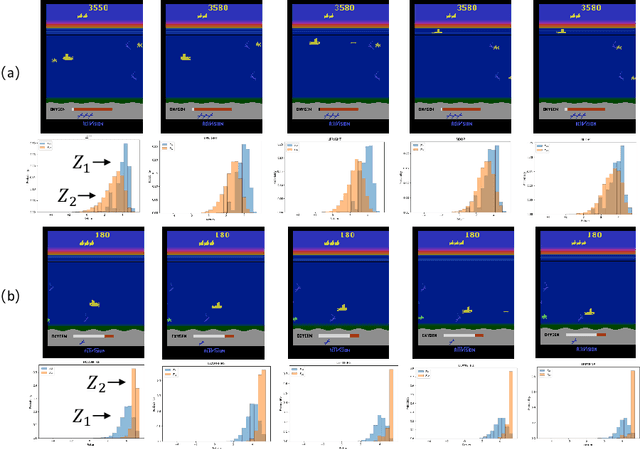
Many reinforcement learning (RL) tasks have specific properties that can be leveraged to modify existing RL algorithms to adapt to those tasks and further improve performance, and a general class of such properties is the multiple reward channel. In those environments the full reward can be decomposed into sub-rewards obtained from different channels. Existing work on reward decomposition either requires prior knowledge of the environment to decompose the full reward, or decomposes reward without prior knowledge but with degraded performance. In this paper, we propose Distributional Reward Decomposition for Reinforcement Learning (DRDRL), a novel reward decomposition algorithm which captures the multiple reward channel structure under distributional setting. Empirically, our method captures the multi-channel structure and discovers meaningful reward decomposition, without any requirements on prior knowledge. Consequently, our agent achieves better performance than existing methods on environments with multiple reward channels.