 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeORIC: Benchmarking Object Recognition in Incongruous Context for Large Vision-Language Models
Sep 19, 2025Large Vision-Language Models (LVLMs) have made significant strides in image caption, visual question answering, and robotics by integrating visual and textual information. However, they remain prone to errors in incongruous contexts, where objects appear unexpectedly or are absent when contextually expected. This leads to two key recognition failures: object misidentification and hallucination. To systematically examine this issue, we introduce the Object Recognition in Incongruous Context Benchmark (ORIC), a novel benchmark that evaluates LVLMs in scenarios where object-context relationships deviate from expectations. ORIC employs two key strategies: (1) LLM-guided sampling, which identifies objects that are present but contextually incongruous, and (2) CLIP-guided sampling, which detects plausible yet nonexistent objects that are likely to be hallucinated, thereby creating an incongruous context. Evaluating 18 LVLMs and two open-vocabulary detection models, our results reveal significant recognition gaps, underscoring the challenges posed by contextual incongruity. This work provides critical insights into LVLMs' limitations and encourages further research on context-aware object recognition.
LongReason: A Synthetic Long-Context Reasoning Benchmark via Context Expansion
Jan 25, 2025



Large language models (LLMs) have demonstrated remarkable progress in understanding long-context inputs. However, benchmarks for evaluating the long-context reasoning abilities of LLMs fall behind the pace. Existing benchmarks often focus on a narrow range of tasks or those that do not demand complex reasoning. To address this gap and enable a more comprehensive evaluation of the long-context reasoning capabilities of current LLMs, we propose a new synthetic benchmark, LongReason, which is constructed by synthesizing long-context reasoning questions from a varied set of short-context reasoning questions through context expansion. LongReason consists of 794 multiple-choice reasoning questions with diverse reasoning patterns across three task categories: reading comprehension, logical inference, and mathematical word problems. We evaluate 21 LLMs on LongReason, revealing that most models experience significant performance drops as context length increases. Our further analysis shows that even state-of-the-art LLMs still have significant room for improvement in providing robust reasoning across different tasks. We will open-source LongReason to support the comprehensive evaluation of LLMs' long-context reasoning capabilities.
ActPlan-1K: Benchmarking the Procedural Planning Ability of Visual Language Models in Household Activities
Oct 04, 2024



Large language models~(LLMs) have been adopted to process textual task description and accomplish procedural planning in embodied AI tasks because of their powerful reasoning ability. However, there is still lack of study on how vision language models~(VLMs) behave when multi-modal task inputs are considered. Counterfactual planning that evaluates the model's reasoning ability over alternative task situations are also under exploited. In order to evaluate the planning ability of both multi-modal and counterfactual aspects, we propose ActPlan-1K. ActPlan-1K is a multi-modal planning benchmark constructed based on ChatGPT and household activity simulator iGibson2. The benchmark consists of 153 activities and 1,187 instances. Each instance describing one activity has a natural language task description and multiple environment images from the simulator. The gold plan of each instance is action sequences over the objects in provided scenes. Both the correctness and commonsense satisfaction are evaluated on typical VLMs. It turns out that current VLMs are still struggling at generating human-level procedural plans for both normal activities and counterfactual activities. We further provide automatic evaluation metrics by finetuning over BLEURT model to facilitate future research on our benchmark.
Unleashing the Creative Mind: Language Model As Hierarchical Policy For Improved Exploration on Challenging Problem Solving
Nov 01, 2023



Large Language Models (LLMs) have achieved tremendous progress, yet they still often struggle with challenging reasoning problems. Current approaches address this challenge by sampling or searching detailed and low-level reasoning chains. However, these methods are still limited in their exploration capabilities, making it challenging for correct solutions to stand out in the huge solution space. In this work, we unleash LLMs' creative potential for exploring multiple diverse problem solving strategies by framing an LLM as a hierarchical policy via in-context learning. This policy comprises of a visionary leader that proposes multiple diverse high-level problem-solving tactics as hints, accompanied by a follower that executes detailed problem-solving processes following each of the high-level instruction. The follower uses each of the leader's directives as a guide and samples multiple reasoning chains to tackle the problem, generating a solution group for each leader proposal. Additionally, we propose an effective and efficient tournament-based approach to select among these explored solution groups to reach the final answer. Our approach produces meaningful and inspiring hints, enhances problem-solving strategy exploration, and improves the final answer accuracy on challenging problems in the MATH dataset. Code will be released at https://github.com/lz1oceani/LLM-As-Hierarchical-Policy.
Reparameterized Policy Learning for Multimodal Trajectory Optimization
Jul 20, 2023



We investigate the challenge of parametrizing policies for reinforcement learning (RL) in high-dimensional continuous action spaces. Our objective is to develop a multimodal policy that overcomes limitations inherent in the commonly-used Gaussian parameterization. To achieve this, we propose a principled framework that models the continuous RL policy as a generative model of optimal trajectories. By conditioning the policy on a latent variable, we derive a novel variational bound as the optimization objective, which promotes exploration of the environment. We then present a practical model-based RL method, called Reparameterized Policy Gradient (RPG), which leverages the multimodal policy parameterization and learned world model to achieve strong exploration capabilities and high data efficiency. Empirical results demonstrate that our method can help agents evade local optima in tasks with dense rewards and solve challenging sparse-reward environments by incorporating an object-centric intrinsic reward. Our method consistently outperforms previous approaches across a range of tasks. Code and supplementary materials are available on the project page https://haosulab.github.io/RPG/
Distilling Large Vision-Language Model with Out-of-Distribution Generalizability
Jul 19, 2023Large vision-language models have achieved outstanding performance, but their size and computational requirements make their deployment on resource-constrained devices and time-sensitive tasks impractical. Model distillation, the process of creating smaller, faster models that maintain the performance of larger models, is a promising direction towards the solution. This paper investigates the distillation of visual representations in large teacher vision-language models into lightweight student models using a small- or mid-scale dataset. Notably, this study focuses on open-vocabulary out-of-distribution (OOD) generalization, a challenging problem that has been overlooked in previous model distillation literature. We propose two principles from vision and language modality perspectives to enhance student's OOD generalization: (1) by better imitating teacher's visual representation space, and carefully promoting better coherence in vision-language alignment with the teacher; (2) by enriching the teacher's language representations with informative and finegrained semantic attributes to effectively distinguish between different labels. We propose several metrics and conduct extensive experiments to investigate their techniques. The results demonstrate significant improvements in zero-shot and few-shot student performance on open-vocabulary out-of-distribution classification, highlighting the effectiveness of our proposed approaches. Code released at https://github.com/xuanlinli17/large_vlm_distillation_ood
On the Efficacy of 3D Point Cloud Reinforcement Learning
Jun 11, 2023



Recent studies on visual reinforcement learning (visual RL) have explored the use of 3D visual representations. However, none of these work has systematically compared the efficacy of 3D representations with 2D representations across different tasks, nor have they analyzed 3D representations from the perspective of agent-object / object-object relationship reasoning. In this work, we seek answers to the question of when and how do 3D neural networks that learn features in the 3D-native space provide a beneficial inductive bias for visual RL. We specifically focus on 3D point clouds, one of the most common forms of 3D representations. We systematically investigate design choices for 3D point cloud RL, leading to the development of a robust algorithm for various robotic manipulation and control tasks. Furthermore, through comparisons between 2D image vs 3D point cloud RL methods on both minimalist synthetic tasks and complex robotic manipulation tasks, we find that 3D point cloud RL can significantly outperform the 2D counterpart when agent-object / object-object relationship encoding is a key factor.
Deductive Verification of Chain-of-Thought Reasoning
Jun 07, 2023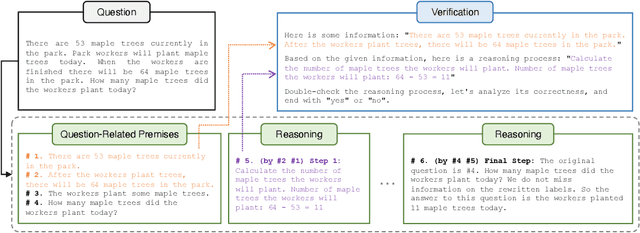
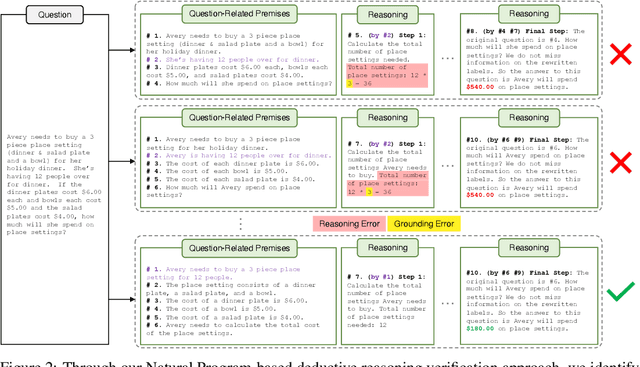
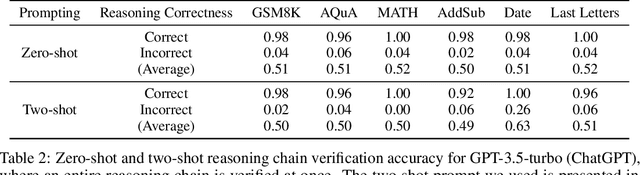

Large Language Models (LLMs) significantly benefit from Chain-of-Thought (CoT) prompting in performing various reasoning tasks. While CoT allows models to produce more comprehensive reasoning processes, its emphasis on intermediate reasoning steps can inadvertently introduce hallucinations and accumulated errors, thereby limiting models' ability to solve complex reasoning tasks. Inspired by how humans engage in careful and meticulous deductive logical reasoning processes to solve tasks, we seek to enable language models to perform explicit and rigorous deductive reasoning, and also ensure the trustworthiness of their reasoning process through self-verification. However, directly verifying the validity of an entire deductive reasoning process is challenging, even with advanced models like ChatGPT. In light of this, we propose to decompose a reasoning verification process into a series of step-by-step subprocesses, each only receiving their necessary context and premises. To facilitate this procedure, we propose Natural Program, a natural language-based deductive reasoning format. Our approach enables models to generate precise reasoning steps where subsequent steps are more rigorously grounded on prior steps. It also empowers language models to carry out reasoning self-verification in a step-by-step manner. By integrating this verification process into each deductive reasoning stage, we significantly enhance the rigor and trustfulness of generated reasoning steps. Along this process, we also improve the answer correctness on complex reasoning tasks. Code will be released at https://github.com/lz1oceani/verify_cot.
ManiSkill2: A Unified Benchmark for Generalizable Manipulation Skills
Feb 09, 2023Generalizable manipulation skills, which can be composed to tackle long-horizon and complex daily chores, are one of the cornerstones of Embodied AI. However, existing benchmarks, mostly composed of a suite of simulatable environments, are insufficient to push cutting-edge research works because they lack object-level topological and geometric variations, are not based on fully dynamic simulation, or are short of native support for multiple types of manipulation tasks. To this end, we present ManiSkill2, the next generation of the SAPIEN ManiSkill benchmark, to address critical pain points often encountered by researchers when using benchmarks for generalizable manipulation skills. ManiSkill2 includes 20 manipulation task families with 2000+ object models and 4M+ demonstration frames, which cover stationary/mobile-base, single/dual-arm, and rigid/soft-body manipulation tasks with 2D/3D-input data simulated by fully dynamic engines. It defines a unified interface and evaluation protocol to support a wide range of algorithms (e.g., classic sense-plan-act, RL, IL), visual observations (point cloud, RGBD), and controllers (e.g., action type and parameterization). Moreover, it empowers fast visual input learning algorithms so that a CNN-based policy can collect samples at about 2000 FPS with 1 GPU and 16 processes on a regular workstation. It implements a render server infrastructure to allow sharing rendering resources across all environments, thereby significantly reducing memory usage. We open-source all codes of our benchmark (simulator, environments, and baselines) and host an online challenge open to interdisciplinary researchers.
PartSLIP: Low-Shot Part Segmentation for 3D Point Clouds via Pretrained Image-Language Models
Dec 03, 2022



Generalizable 3D part segmentation is important but challenging in vision and robotics. Training deep models via conventional supervised methods requires large-scale 3D datasets with fine-grained part annotations, which are costly to collect. This paper explores an alternative way for low-shot part segmentation of 3D point clouds by leveraging a pretrained image-language model, GLIP, which achieves superior performance on open-vocabulary 2D detection. We transfer the rich knowledge from 2D to 3D through GLIP-based part detection on point cloud rendering and a novel 2D-to-3D label lifting algorithm. We also utilize multi-view 3D priors and few-shot prompt tuning to boost performance significantly. Extensive evaluation on PartNet and PartNet-Mobility datasets shows that our method enables excellent zero-shot 3D part segmentation. Our few-shot version not only outperforms existing few-shot approaches by a large margin but also achieves highly competitive results compared to the fully supervised counterpart. Furthermore, we demonstrate that our method can be directly applied to iPhone-scanned point clouds without significant domain gaps.