 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMoVE: Mixture of Value Embeddings -- A New Axis for Scaling Parametric Memory in Autoregressive Models
Jan 30, 2026Autoregressive sequence modeling stands as the cornerstone of modern Generative AI, powering results across diverse modalities ranging from text generation to image generation. However, a fundamental limitation of this paradigm is the rigid structural coupling of model capacity to computational cost: expanding a model's parametric memory -- its repository of factual knowledge or visual patterns -- traditionally requires deepening or widening the network, which incurs a proportional rise in active FLOPs. In this work, we introduce $\textbf{MoVE (Mixture of Value Embeddings)}$, a mechanism that breaks this coupling and establishes a new axis for scaling capacity. MoVE decouples memory from compute by introducing a global bank of learnable value embeddings shared across all attention layers. For every step in the sequence, the model employs a differentiable soft gating mechanism to dynamically mix retrieved concepts from this bank into the standard value projection. This architecture allows parametric memory to be scaled independently of network depth by simply increasing the number of embedding slots. We validate MoVE through strictly controlled experiments on two representative applications of autoregressive modeling: Text Generation and Image Generation. In both domains, MoVE yields consistent performance improvements over standard and layer-wise memory baselines, enabling the construction of "memory-dense" models that achieve lower perplexity and higher fidelity than their dense counterparts at comparable compute budgets.
From Orbit to Ground: Generative City Photogrammetry from Extreme Off-Nadir Satellite Images
Dec 09, 2025City-scale 3D reconstruction from satellite imagery presents the challenge of extreme viewpoint extrapolation, where our goal is to synthesize ground-level novel views from sparse orbital images with minimal parallax. This requires inferring nearly $90^\circ$ viewpoint gaps from image sources with severely foreshortened facades and flawed textures, causing state-of-the-art reconstruction engines such as NeRF and 3DGS to fail. To address this problem, we propose two design choices tailored for city structures and satellite inputs. First, we model city geometry as a 2.5D height map, implemented as a Z-monotonic signed distance field (SDF) that matches urban building layouts from top-down viewpoints. This stabilizes geometry optimization under sparse, off-nadir satellite views and yields a watertight mesh with crisp roofs and clean, vertically extruded facades. Second, we paint the mesh appearance from satellite images via differentiable rendering techniques. While the satellite inputs may contain long-range, blurry captures, we further train a generative texture restoration network to enhance the appearance, recovering high-frequency, plausible texture details from degraded inputs. Our method's scalability and robustness are demonstrated through extensive experiments on large-scale urban reconstruction. For example, in our teaser figure, we reconstruct a $4\,\mathrm{km}^2$ real-world region from only a few satellite images, achieving state-of-the-art performance in synthesizing photorealistic ground views. The resulting models are not only visually compelling but also serve as high-fidelity, application-ready assets for downstream tasks like urban planning and simulation. Project page can be found at https://pku-vcl-geometry.github.io/Orbit2Ground/.
The Less You Depend, The More You Learn: Synthesizing Novel Views from Sparse, Unposed Images without Any 3D Knowledge
Jun 11, 2025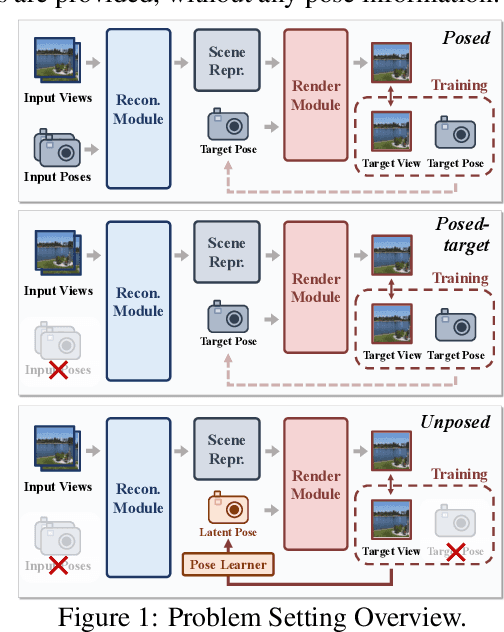
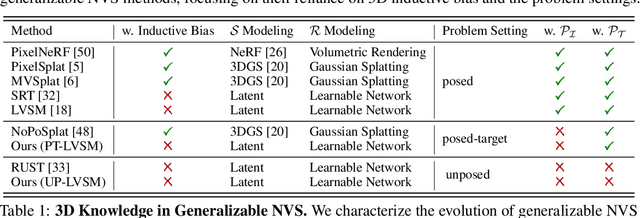
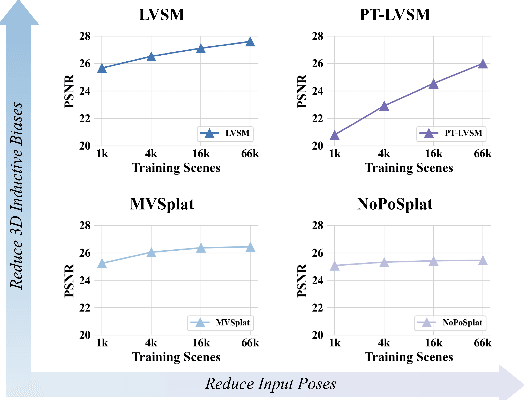
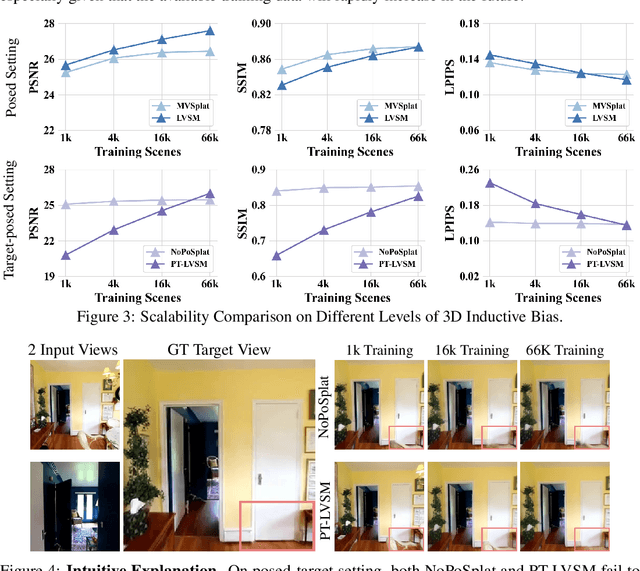
We consider the problem of generalizable novel view synthesis (NVS), which aims to generate photorealistic novel views from sparse or even unposed 2D images without per-scene optimization. This task remains fundamentally challenging, as it requires inferring 3D structure from incomplete and ambiguous 2D observations. Early approaches typically rely on strong 3D knowledge, including architectural 3D inductive biases (e.g., embedding explicit 3D representations, such as NeRF or 3DGS, into network design) and ground-truth camera poses for both input and target views. While recent efforts have sought to reduce the 3D inductive bias or the dependence on known camera poses of input views, critical questions regarding the role of 3D knowledge and the necessity of circumventing its use remain under-explored. In this work, we conduct a systematic analysis on the 3D knowledge and uncover a critical trend: the performance of methods that requires less 3D knowledge accelerates more as data scales, eventually achieving performance on par with their 3D knowledge-driven counterparts, which highlights the increasing importance of reducing dependence on 3D knowledge in the era of large-scale data. Motivated by and following this trend, we propose a novel NVS framework that minimizes 3D inductive bias and pose dependence for both input and target views. By eliminating this 3D knowledge, our method fully leverages data scaling and learns implicit 3D awareness directly from sparse 2D images, without any 3D inductive bias or pose annotation during training. Extensive experiments demonstrate that our model generates photorealistic and 3D-consistent novel views, achieving even comparable performance with methods that rely on posed inputs, thereby validating the feasibility and effectiveness of our data-centric paradigm. Project page: https://pku-vcl-geometry.github.io/Less3Depend/ .
ShapeMoiré: Channel-Wise Shape-Guided Network for Image Demoiréing
Apr 28, 2024
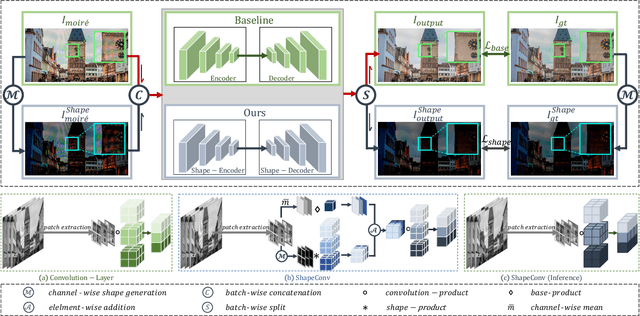

Photographing optoelectronic displays often introduces unwanted moir\'e patterns due to analog signal interference between the pixel grids of the display and the camera sensor arrays. This work identifies two problems that are largely ignored by existing image demoir\'eing approaches: 1) moir\'e patterns vary across different channels (RGB); 2) repetitive patterns are constantly observed. However, employing conventional convolutional (CNN) layers cannot address these problems. Instead, this paper presents the use of our recently proposed Shape concept. It was originally employed to model consistent features from fragmented regions, particularly when identical or similar objects coexist in an RGB-D image. Interestingly, we find that the Shape information effectively captures the moir\'e patterns in artifact images. Motivated by this discovery, we propose a ShapeMoir\'e method to aid in image demoir\'eing. Beyond modeling shape features at the patch-level, we further extend this to the global image-level and design a novel Shape-Architecture. Consequently, our proposed method, equipped with both ShapeConv and Shape-Architecture, can be seamlessly integrated into existing approaches without introducing additional parameters or computation overhead during inference. We conduct extensive experiments on four widely used datasets, and the results demonstrate that our ShapeMoir\'e achieves state-of-the-art performance, particularly in terms of the PSNR metric. We then apply our method across four popular architectures to showcase its generalization capabilities. Moreover, our ShapeMoir\'e is robust and viable under real-world demoir\'eing scenarios involving smartphone photographs.
Frame Mining: a Free Lunch for Learning Robotic Manipulation from 3D Point Clouds
Oct 14, 2022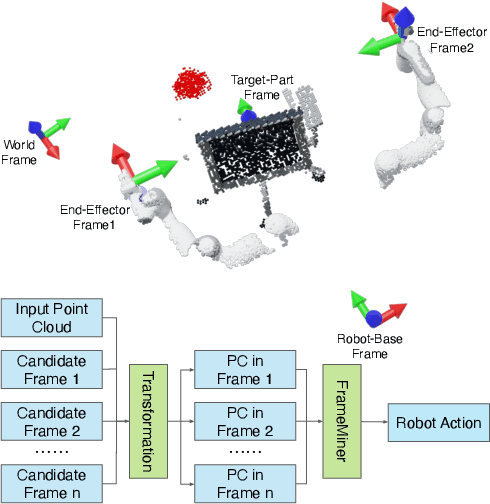
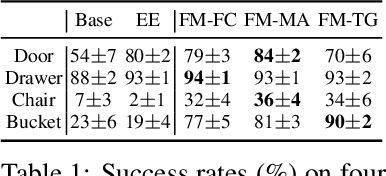


We study how choices of input point cloud coordinate frames impact learning of manipulation skills from 3D point clouds. There exist a variety of coordinate frame choices to normalize captured robot-object-interaction point clouds. We find that different frames have a profound effect on agent learning performance, and the trend is similar across 3D backbone networks. In particular, the end-effector frame and the target-part frame achieve higher training efficiency than the commonly used world frame and robot-base frame in many tasks, intuitively because they provide helpful alignments among point clouds across time steps and thus can simplify visual module learning. Moreover, the well-performing frames vary across tasks, and some tasks may benefit from multiple frame candidates. We thus propose FrameMiners to adaptively select candidate frames and fuse their merits in a task-agnostic manner. Experimentally, FrameMiners achieves on-par or significantly higher performance than the best single-frame version on five fully physical manipulation tasks adapted from ManiSkill and OCRTOC. Without changing existing camera placements or adding extra cameras, point cloud frame mining can serve as a free lunch to improve 3D manipulation learning.
ShapeConv: Shape-aware Convolutional Layer for Indoor RGB-D Semantic Segmentation
Aug 24, 2021
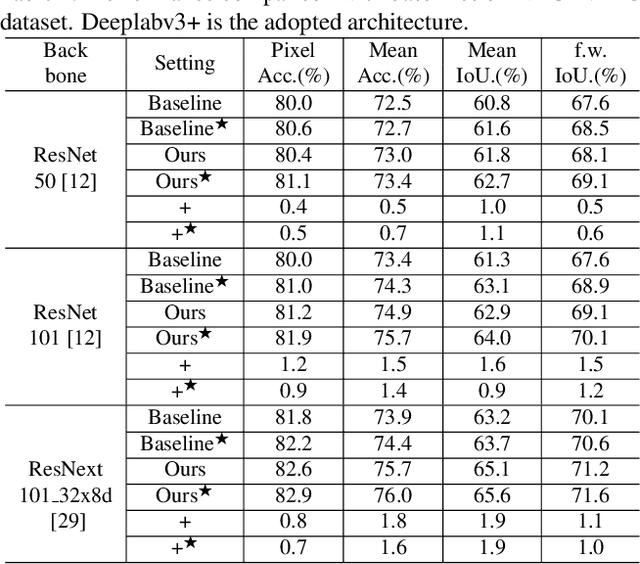
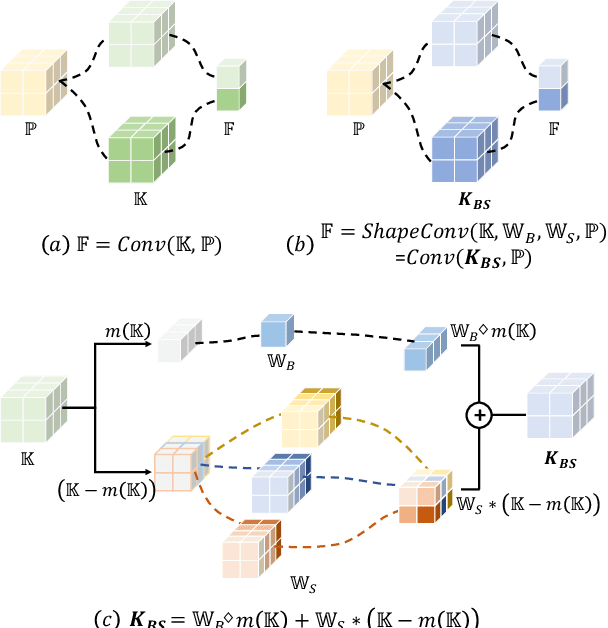
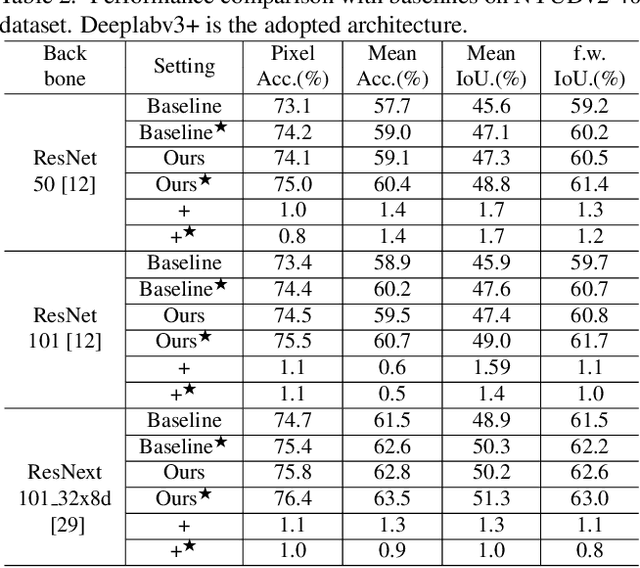
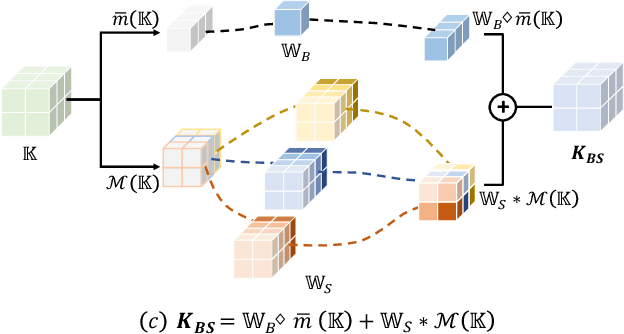
RGB-D semantic segmentation has attracted increasing attention over the past few years. Existing methods mostly employ homogeneous convolution operators to consume the RGB and depth features, ignoring their intrinsic differences. In fact, the RGB values capture the photometric appearance properties in the projected image space, while the depth feature encodes both the shape of a local geometry as well as the base (whereabout) of it in a larger context. Compared with the base, the shape probably is more inherent and has a stronger connection to the semantics, and thus is more critical for segmentation accuracy. Inspired by this observation, we introduce a Shape-aware Convolutional layer (ShapeConv) for processing the depth feature, where the depth feature is firstly decomposed into a shape-component and a base-component, next two learnable weights are introduced to cooperate with them independently, and finally a convolution is applied on the re-weighted combination of these two components. ShapeConv is model-agnostic and can be easily integrated into most CNNs to replace vanilla convolutional layers for semantic segmentation. Extensive experiments on three challenging indoor RGB-D semantic segmentation benchmarks, i.e., NYU-Dv2(-13,-40), SUN RGB-D, and SID, demonstrate the effectiveness of our ShapeConv when employing it over five popular architectures. Moreover, the performance of CNNs with ShapeConv is boosted without introducing any computation and memory increase in the inference phase. The reason is that the learnt weights for balancing the importance between the shape and base components in ShapeConv become constants in the inference phase, and thus can be fused into the following convolution, resulting in a network that is identical to one with vanilla convolutional layers.
GSTO: Gated Scale-Transfer Operation for Multi-Scale Feature Learning in Pixel Labeling
Jun 28, 2020


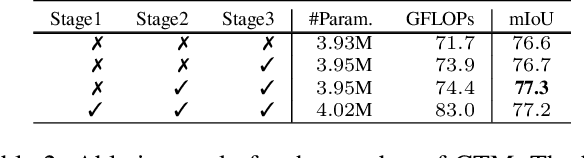
Existing CNN-based methods for pixel labeling heavily depend on multi-scale features to meet the requirements of both semantic comprehension and detail preservation. State-of-the-art pixel labeling neural networks widely exploit conventional scale-transfer operations, i.e., up-sampling and down-sampling to learn multi-scale features. In this work, we find that these operations lead to scale-confused features and suboptimal performance because they are spatial-invariant and directly transit all feature information cross scales without spatial selection. To address this issue, we propose the Gated Scale-Transfer Operation (GSTO) to properly transit spatial-filtered features to another scale. Specifically, GSTO can work either with or without extra supervision. Unsupervised GSTO is learned from the feature itself while the supervised one is guided by the supervised probability matrix. Both forms of GSTO are lightweight and plug-and-play, which can be flexibly integrated into networks or modules for learning better multi-scale features. In particular, by plugging GSTO into HRNet, we get a more powerful backbone (namely GSTO-HRNet) for pixel labeling, and it achieves new state-of-the-art results on the COCO benchmark for human pose estimation and other benchmarks for semantic segmentation including Cityscapes, LIP and Pascal Context, with negligible extra computational cost. Moreover, experiment results demonstrate that GSTO can also significantly boost the performance of multi-scale feature aggregation modules like PPM and ASPP. Code will be made available at https://github.com/VDIGPKU/GSTO.
DO-Conv: Depthwise Over-parameterized Convolutional Layer
Jun 22, 2020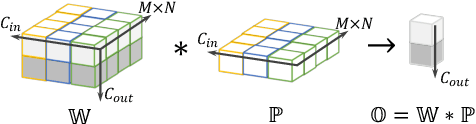
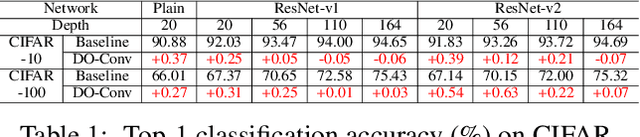

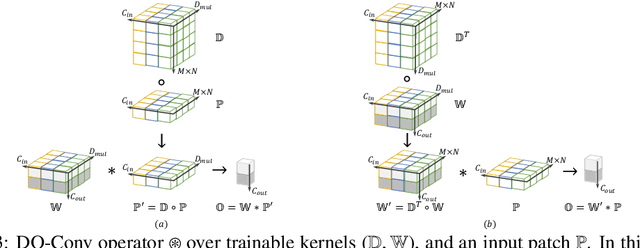
Convolutional layers are the core building blocks of Convolutional Neural Networks (CNNs). In this paper, we propose to augment a convolutional layer with an additional depthwise convolution, where each input channel is convolved with a different 2D kernel. The composition of the two convolutions constitutes an over-parameterization, since it adds learnable parameters, while the resulting linear operation can be expressed by a single convolution layer. We refer to this depthwise over-parameterized convolutional layer as DO-Conv. We show with extensive experiments that the mere replacement of conventional convolutional layers with DO-Conv layers boosts the performance of CNNs on many classical vision tasks, such as image classification, detection, and segmentation. Moreover, in the inference phase, the depthwise convolution is folded into the conventional convolution, reducing the computation to be exactly equivalent to that of a convolutional layer without over-parameterization. As DO-Conv introduces performance gains without incurring any computational complexity increase for inference, we advocate it as an alternative to the conventional convolutional layer. We open-source a reference implementation of DO-Conv in Tensorflow, PyTorch and GluonCV at https://github.com/yangyanli/DO-Conv.
Disentangling in Latent Space by Harnessing a Pretrained Generator
May 15, 2020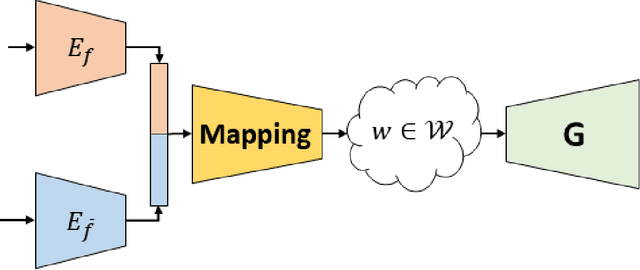


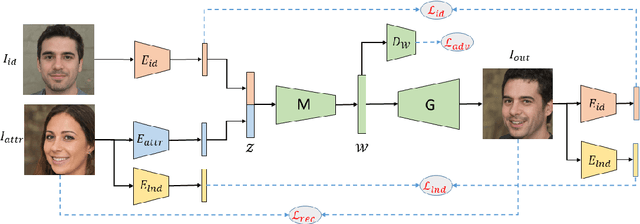
Learning disentangled representations of data is a fundamental problem in artificial intelligence. Specifically, disentangled latent representations allow generative models to control and compose the disentangled factors in the synthesis process. Current methods, however, require extensive supervision and training, or instead, noticeably compromise quality. In this paper, we present a method that learn show to represent data in a disentangled way, with minimal supervision, manifested solely using available pre-trained networks. Our key insight is to decouple the processes of disentanglement and synthesis, by employing a leading pre-trained unconditional image generator, such as StyleGAN. By learning to map into its latent space, we leverage both its state-of-the-art quality generative power, and its rich and expressive latent space, without the burden of training it.We demonstrate our approach on the complex and high dimensional domain of human heads. We evaluate our method qualitatively and quantitatively, and exhibit its success with de-identification operations and with temporal identity coherency in image sequences. Through this extensive experimentation, we show that our method successfully disentangles identity from other facial attributes, surpassing existing methods, even though they require more training and supervision.
MixTConv: Mixed Temporal Convolutional Kernels for Efficient Action Recogntion
Jan 25, 2020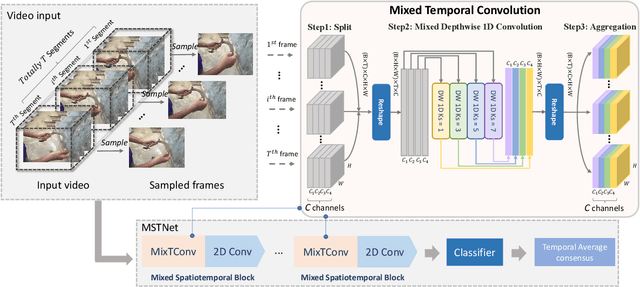
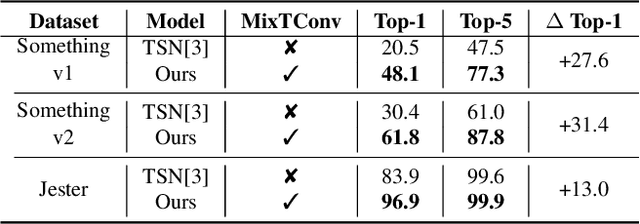
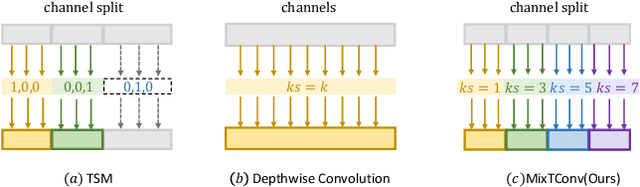
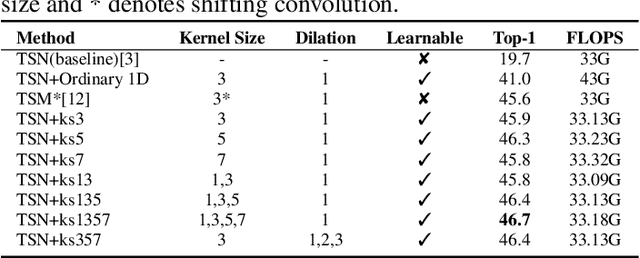
To efficiently extract spatiotemporal features of video for action recognition, most state-of-the-art methods integrate 1D temporal convolution into a conventional 2D CNN backbone. However, they all exploit 1D temporal convolution of fixed kernel size (i.e., 3) in the network building block, thus have suboptimal temporal modeling capability to handle both long-term and short-term actions. To address this problem, we first investigate the impacts of different kernel sizes for the 1D temporal convolutional filters. Then, we propose a simple yet efficient operation called Mixed Temporal Convolution (MixTConv), which consists of multiple depthwise 1D convolutional filters with different kernel sizes. By plugging MixTConv into the conventional 2D CNN backbone ResNet-50, we further propose an efficient and effective network architecture named MSTNet for action recognition, and achieve state-of-the-art results on multiple benchmarks.