 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Free Score Distillation
Oct 26, 2023



Score Distillation Sampling (SDS) has emerged as the de facto approach for text-to-content generation in non-image domains. In this paper, we reexamine the SDS process and introduce a straightforward interpretation that demystifies the necessity for large Classifier-Free Guidance (CFG) scales, rooted in the distillation of an undesired noise term. Building upon our interpretation, we propose a novel Noise-Free Score Distillation (NFSD) process, which requires minimal modifications to the original SDS framework. Through this streamlined design, we achieve more effective distillation of pre-trained text-to-image diffusion models while using a nominal CFG scale. This strategic choice allows us to prevent the over-smoothing of results, ensuring that the generated data is both realistic and complies with the desired prompt. To demonstrate the efficacy of NFSD, we provide qualitative examples that compare NFSD and SDS, as well as several other methods.
Shape-Pose Disentanglement using SE(3)-equivariant Vector Neurons
Apr 03, 2022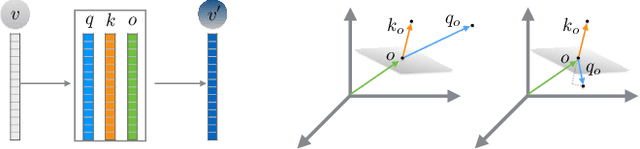
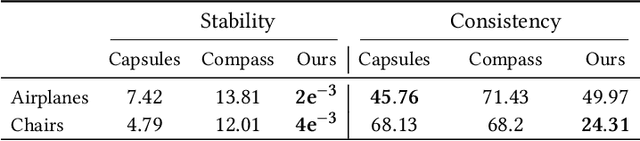
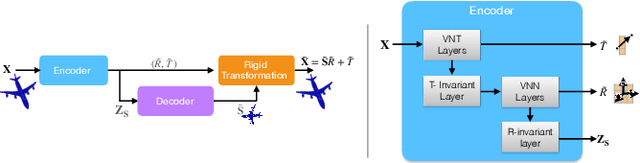
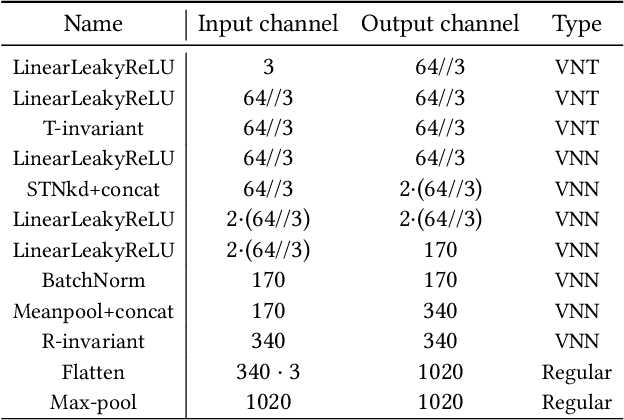
We introduce an unsupervised technique for encoding point clouds into a canonical shape representation, by disentangling shape and pose. Our encoder is stable and consistent, meaning that the shape encoding is purely pose-invariant, while the extracted rotation and translation are able to semantically align different input shapes of the same class to a common canonical pose. Specifically, we design an auto-encoder based on Vector Neuron Networks, a rotation-equivariant neural network, whose layers we extend to provide translation-equivariance in addition to rotation-equivariance only. The resulting encoder produces pose-invariant shape encoding by construction, enabling our approach to focus on learning a consistent canonical pose for a class of objects. Quantitative and qualitative experiments validate the superior stability and consistency of our approach.
Multi-level Latent Space Structuring for Generative Control
Feb 11, 2022



Truncation is widely used in generative models for improving the quality of the generated samples, at the expense of reducing their diversity. We propose to leverage the StyleGAN generative architecture to devise a new truncation technique, based on a decomposition of the latent space into clusters, enabling customized truncation to be performed at multiple semantic levels. We do so by learning to re-generate W-space, the extended intermediate latent space of StyleGAN, using a learnable mixture of Gaussians, while simultaneously training a classifier to identify, for each latent vector, the cluster that it belongs to. The resulting truncation scheme is more faithful to the original untruncated samples and allows a better trade-off between quality and diversity. We compare our method to other truncation approaches for StyleGAN, both qualitatively and quantitatively.
Cross-Domain Cascaded Deep Feature Translation
Jun 04, 2019



In recent years we have witnessed tremendous progress in unpaired image-to-image translation methods, propelled by the emergence of DNNs and adversarial training strategies. However, most existing methods focus on transfer of style and appearance, rather than on shape translation. The latter task is challenging, due to its intricate non-local nature, which calls for additional supervision. We mitigate this by descending the deep layers of a pre-trained network, where the deep features contain more semantics, and applying the translation from and between these deep features. Specifically, we leverage VGG, which is a classification network, pre-trained with large-scale semantic supervision. Our translation is performed in a cascaded, deep-to-shallow, fashion, along the deep feature hierarchy: we first translate between the deepest layers that encode the higher-level semantic content of the image, proceeding to translate the shallower layers, conditioned on the deeper ones. We show that our method is able to translate between different domains, which exhibit significantly different shapes. We evaluate our method both qualitatively and quantitatively and compare it to state-of-the-art image-to-image translation methods. Our code and trained models will be made available.
Learning to Generate the "Unseen" via Part Synthesis and Composition
Nov 19, 2018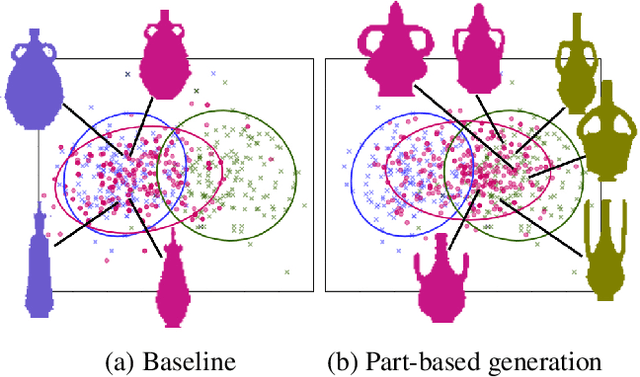
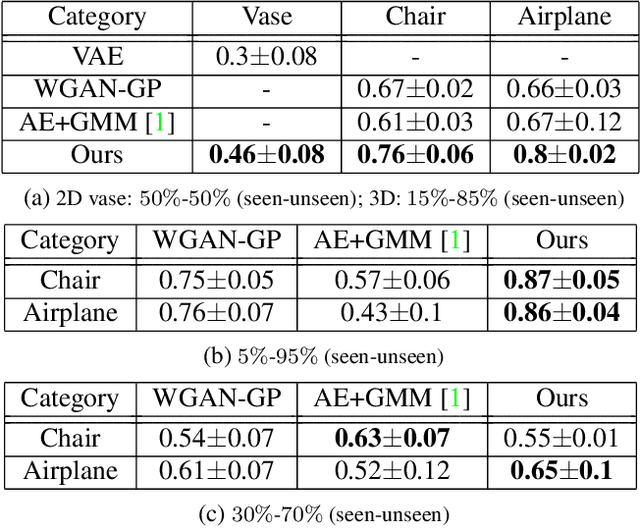
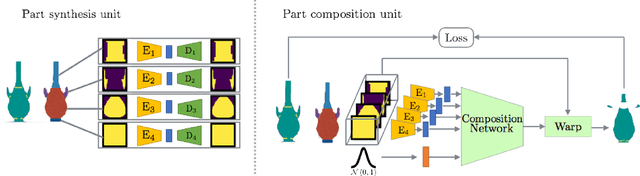

Data-driven generative modeling has made remarkable progress by leveraging the power of deep neural networks. A reoccurring challenge is how to sample a rich variety of data from the entire target distribution, rather than only from the distribution of the training data. In other words, we would like the generative model to go beyond the observed training samples and learn to also generate "unseen" data. In our work, we present a generative neural network for shapes that is based on a part-based prior, where the key idea is for the network to synthesize shapes by varying both the shape parts and their compositions. Treating a shape not as an unstructured whole, but as a (re-)composable set of deformable parts, adds a combinatorial dimension to the generative process to enrich the diversity of the output, encouraging the generator to venture more into the "unseen". We show that our part-based model generates richer variety of feasible shapes compared with a baseline generative model. To this end, we introduce two quantitative metrics to evaluate the ingenuity of the generative model and assess how well generated data covers both the training data and unseen data from the same target distribution.
DiDA: Disentangled Synthesis for Domain Adaptation
May 21, 2018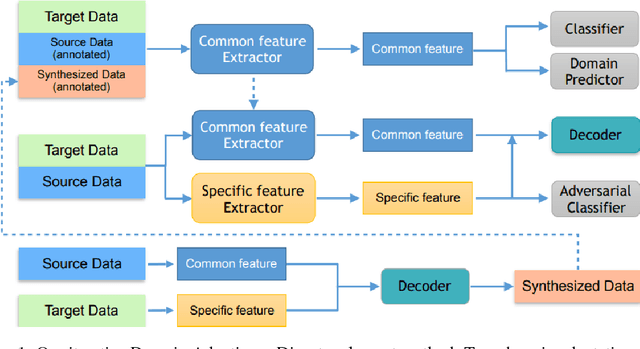
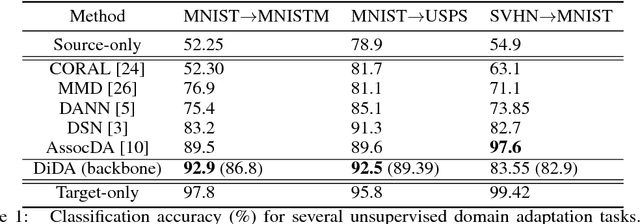


Unsupervised domain adaptation aims at learning a shared model for two related, but not identical, domains by leveraging supervision from a source domain to an unsupervised target domain. A number of effective domain adaptation approaches rely on the ability to extract discriminative, yet domain-invariant, latent factors which are common to both domains. Extracting latent commonality is also useful for disentanglement analysis, enabling separation between the common and the domain-specific features of both domains. In this paper, we present a method for boosting domain adaptation performance by leveraging disentanglement analysis. The key idea is that by learning to separately extract both the common and the domain-specific features, one can synthesize more target domain data with supervision, thereby boosting the domain adaptation performance. Better common feature extraction, in turn, helps further improve the disentanglement analysis and disentangled synthesis. We show that iterating between domain adaptation and disentanglement analysis can consistently improve each other on several unsupervised domain adaptation tasks, for various domain adaptation backbone models.