 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenAVS: Training-Free Open-Vocabulary Audio Visual Segmentation with Foundational Models
Apr 30, 2025Audio-visual segmentation aims to separate sounding objects from videos by predicting pixel-level masks based on audio signals. Existing methods primarily concentrate on closed-set scenarios and direct audio-visual alignment and fusion, which limits their capability to generalize to new, unseen situations. In this paper, we propose OpenAVS, a novel training-free language-based approach that, for the first time, effectively aligns audio and visual modalities using text as a proxy for open-vocabulary Audio-Visual Segmentation (AVS). Equipped with multimedia foundation models, OpenAVS directly infers masks through 1) audio-to-text prompt generation, 2) LLM-guided prompt translation, and 3) text-to-visual sounding object segmentation. The objective of OpenAVS is to establish a simple yet flexible architecture that relies on the most appropriate foundation models by fully leveraging their capabilities to enable more effective knowledge transfer to the downstream AVS task. Moreover, we present a model-agnostic framework OpenAVS-ST that enables the integration of OpenAVS with any advanced supervised AVS model via pseudo-label based self-training. This approach enhances performance by effectively utilizing large-scale unlabeled data when available. Comprehensive experiments on three benchmark datasets demonstrate the superior performance of OpenAVS. It surpasses existing unsupervised, zero-shot, and few-shot AVS methods by a significant margin, achieving absolute performance gains of approximately 9.4% and 10.9% in mIoU and F-score, respectively, in challenging scenarios.
Manifold-Aware Local Feature Modeling for Semi-Supervised Medical Image Segmentation
Oct 14, 2024Achieving precise medical image segmentation is vital for effective treatment planning and accurate disease diagnosis. Traditional fully-supervised deep learning methods, though highly precise, are heavily reliant on large volumes of labeled data, which are often difficult to obtain due to the expertise required for medical annotations. This has led to the rise of semi-supervised learning approaches that utilize both labeled and unlabeled data to mitigate the label scarcity issue. In this paper, we introduce the Manifold-Aware Local Feature Modeling Network (MANet), which enhances the U-Net architecture by incorporating manifold supervision signals. This approach focuses on improving boundary accuracy, which is crucial for reliable medical diagnosis. To further extend the versatility of our method, we propose two variants: MA-Sobel and MA-Canny. The MA-Sobel variant employs the Sobel operator, which is effective for both 2D and 3D data, while the MA-Canny variant utilizes the Canny operator, specifically designed for 2D images, to refine boundary detection. These variants allow our method to adapt to various medical image modalities and dimensionalities, ensuring broader applicability. Our extensive experiments on datasets such as ACDC, LA, and Pancreas-NIH demonstrate that MANet consistently surpasses state-of-the-art methods in performance metrics like Dice and Jaccard scores. The proposed method also shows improved generalization across various semi-supervised segmentation networks, highlighting its robustness and effectiveness. Visual analysis of segmentation results confirms that MANet offers clearer and more accurate class boundaries, underscoring the value of manifold information in medical image segmentation.
ShapeMoiré: Channel-Wise Shape-Guided Network for Image Demoiréing
Apr 28, 2024
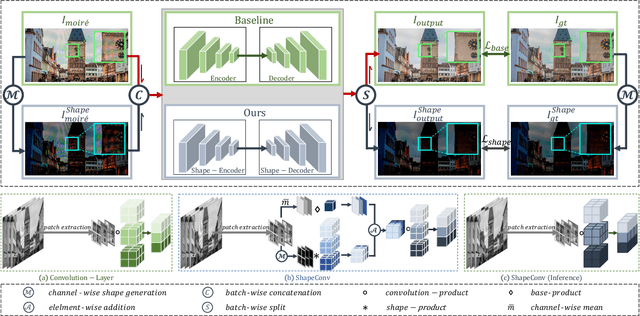
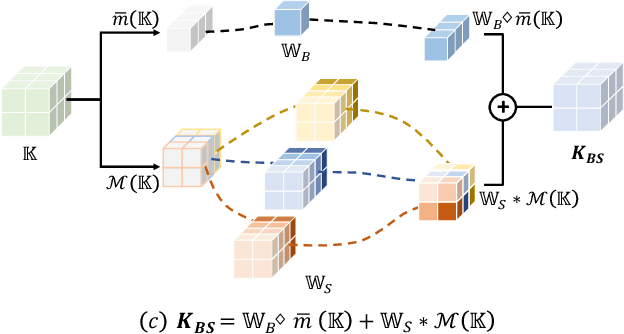

Photographing optoelectronic displays often introduces unwanted moir\'e patterns due to analog signal interference between the pixel grids of the display and the camera sensor arrays. This work identifies two problems that are largely ignored by existing image demoir\'eing approaches: 1) moir\'e patterns vary across different channels (RGB); 2) repetitive patterns are constantly observed. However, employing conventional convolutional (CNN) layers cannot address these problems. Instead, this paper presents the use of our recently proposed Shape concept. It was originally employed to model consistent features from fragmented regions, particularly when identical or similar objects coexist in an RGB-D image. Interestingly, we find that the Shape information effectively captures the moir\'e patterns in artifact images. Motivated by this discovery, we propose a ShapeMoir\'e method to aid in image demoir\'eing. Beyond modeling shape features at the patch-level, we further extend this to the global image-level and design a novel Shape-Architecture. Consequently, our proposed method, equipped with both ShapeConv and Shape-Architecture, can be seamlessly integrated into existing approaches without introducing additional parameters or computation overhead during inference. We conduct extensive experiments on four widely used datasets, and the results demonstrate that our ShapeMoir\'e achieves state-of-the-art performance, particularly in terms of the PSNR metric. We then apply our method across four popular architectures to showcase its generalization capabilities. Moreover, our ShapeMoir\'e is robust and viable under real-world demoir\'eing scenarios involving smartphone photographs.
SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection
Aug 26, 2023In the field of autonomous driving, accurate and comprehensive perception of the 3D environment is crucial. Bird's Eye View (BEV) based methods have emerged as a promising solution for 3D object detection using multi-view images as input. However, existing 3D object detection methods often ignore the physical context in the environment, such as sidewalk and vegetation, resulting in sub-optimal performance. In this paper, we propose a novel approach called SOGDet (Semantic-Occupancy Guided Multi-view 3D Object Detection), that leverages a 3D semantic-occupancy branch to improve the accuracy of 3D object detection. In particular, the physical context modeled by semantic occupancy helps the detector to perceive the scenes in a more holistic view. Our SOGDet is flexible to use and can be seamlessly integrated with most existing BEV-based methods. To evaluate its effectiveness, we apply this approach to several state-of-the-art baselines and conduct extensive experiments on the exclusive nuScenes dataset. Our results show that SOGDet consistently enhance the performance of three baseline methods in terms of nuScenes Detection Score (NDS) and mean Average Precision (mAP). This indicates that the combination of 3D object detection and 3D semantic occupancy leads to a more comprehensive perception of the 3D environment, thereby aiding build more robust autonomous driving systems. The codes are available at: https://github.com/zhouqiu/SOGDet.
ShapeConv: Shape-aware Convolutional Layer for Indoor RGB-D Semantic Segmentation
Aug 24, 2021
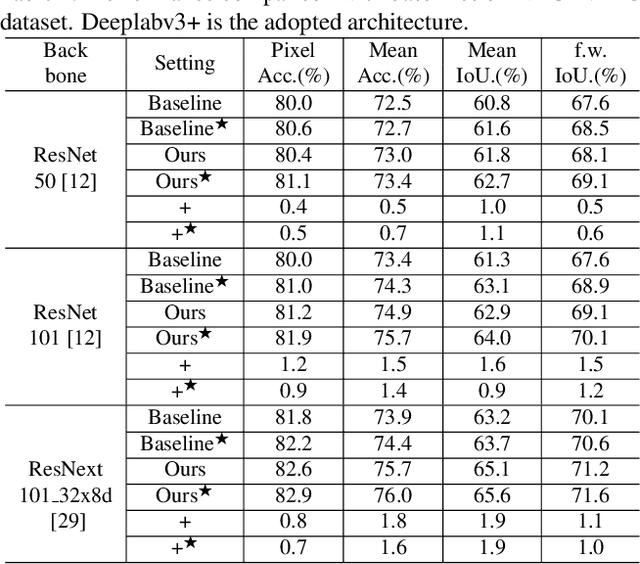
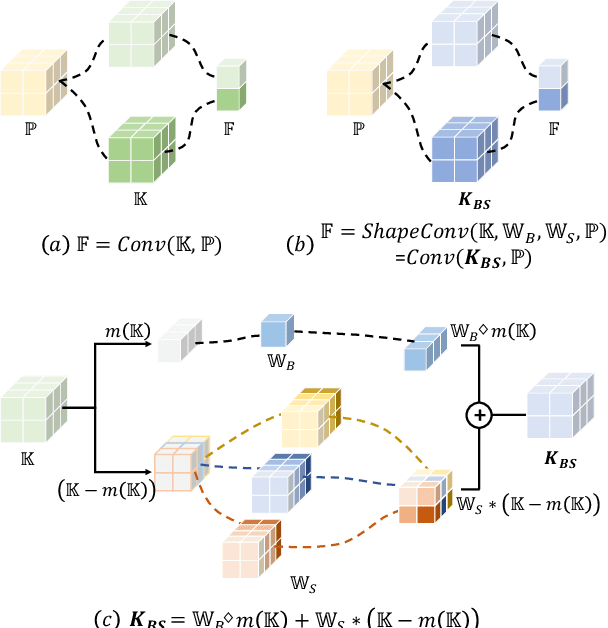
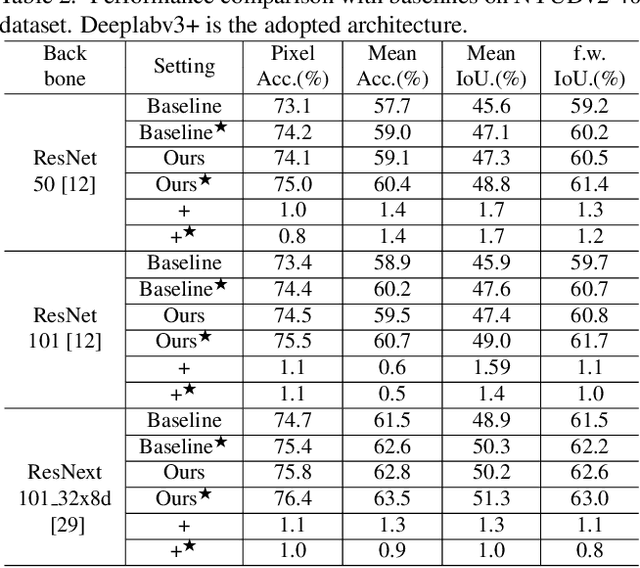
RGB-D semantic segmentation has attracted increasing attention over the past few years. Existing methods mostly employ homogeneous convolution operators to consume the RGB and depth features, ignoring their intrinsic differences. In fact, the RGB values capture the photometric appearance properties in the projected image space, while the depth feature encodes both the shape of a local geometry as well as the base (whereabout) of it in a larger context. Compared with the base, the shape probably is more inherent and has a stronger connection to the semantics, and thus is more critical for segmentation accuracy. Inspired by this observation, we introduce a Shape-aware Convolutional layer (ShapeConv) for processing the depth feature, where the depth feature is firstly decomposed into a shape-component and a base-component, next two learnable weights are introduced to cooperate with them independently, and finally a convolution is applied on the re-weighted combination of these two components. ShapeConv is model-agnostic and can be easily integrated into most CNNs to replace vanilla convolutional layers for semantic segmentation. Extensive experiments on three challenging indoor RGB-D semantic segmentation benchmarks, i.e., NYU-Dv2(-13,-40), SUN RGB-D, and SID, demonstrate the effectiveness of our ShapeConv when employing it over five popular architectures. Moreover, the performance of CNNs with ShapeConv is boosted without introducing any computation and memory increase in the inference phase. The reason is that the learnt weights for balancing the importance between the shape and base components in ShapeConv become constants in the inference phase, and thus can be fused into the following convolution, resulting in a network that is identical to one with vanilla convolutional layers.
DO-Conv: Depthwise Over-parameterized Convolutional Layer
Jun 22, 2020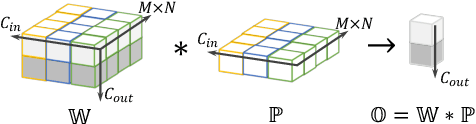
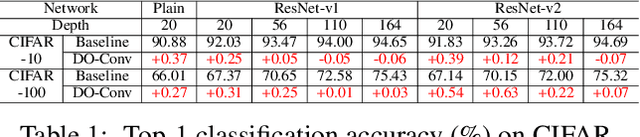

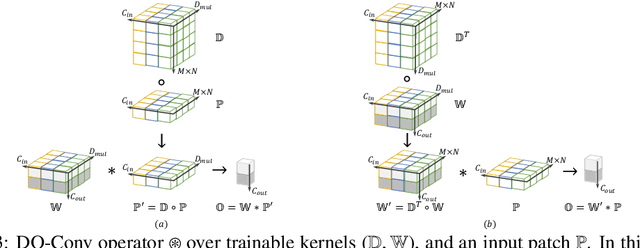
Convolutional layers are the core building blocks of Convolutional Neural Networks (CNNs). In this paper, we propose to augment a convolutional layer with an additional depthwise convolution, where each input channel is convolved with a different 2D kernel. The composition of the two convolutions constitutes an over-parameterization, since it adds learnable parameters, while the resulting linear operation can be expressed by a single convolution layer. We refer to this depthwise over-parameterized convolutional layer as DO-Conv. We show with extensive experiments that the mere replacement of conventional convolutional layers with DO-Conv layers boosts the performance of CNNs on many classical vision tasks, such as image classification, detection, and segmentation. Moreover, in the inference phase, the depthwise convolution is folded into the conventional convolution, reducing the computation to be exactly equivalent to that of a convolutional layer without over-parameterization. As DO-Conv introduces performance gains without incurring any computational complexity increase for inference, we advocate it as an alternative to the conventional convolutional layer. We open-source a reference implementation of DO-Conv in Tensorflow, PyTorch and GluonCV at https://github.com/yangyanli/DO-Conv.
DiDA: Disentangled Synthesis for Domain Adaptation
May 21, 2018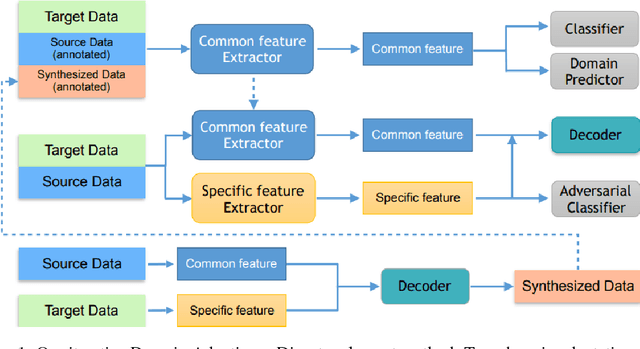
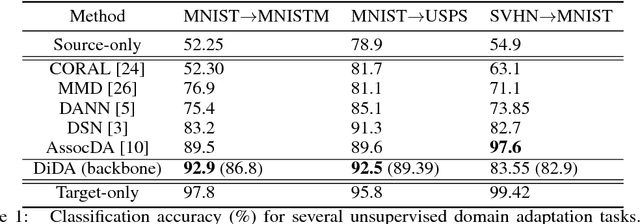


Unsupervised domain adaptation aims at learning a shared model for two related, but not identical, domains by leveraging supervision from a source domain to an unsupervised target domain. A number of effective domain adaptation approaches rely on the ability to extract discriminative, yet domain-invariant, latent factors which are common to both domains. Extracting latent commonality is also useful for disentanglement analysis, enabling separation between the common and the domain-specific features of both domains. In this paper, we present a method for boosting domain adaptation performance by leveraging disentanglement analysis. The key idea is that by learning to separately extract both the common and the domain-specific features, one can synthesize more target domain data with supervision, thereby boosting the domain adaptation performance. Better common feature extraction, in turn, helps further improve the disentanglement analysis and disentangled synthesis. We show that iterating between domain adaptation and disentanglement analysis can consistently improve each other on several unsupervised domain adaptation tasks, for various domain adaptation backbone models.