 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeShapeMoiré: Channel-Wise Shape-Guided Network for Image Demoiréing
Apr 28, 2024
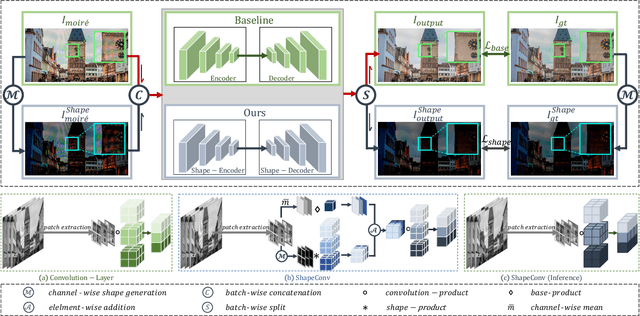
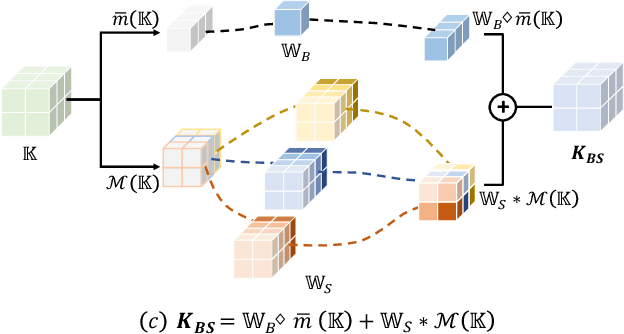

Photographing optoelectronic displays often introduces unwanted moir\'e patterns due to analog signal interference between the pixel grids of the display and the camera sensor arrays. This work identifies two problems that are largely ignored by existing image demoir\'eing approaches: 1) moir\'e patterns vary across different channels (RGB); 2) repetitive patterns are constantly observed. However, employing conventional convolutional (CNN) layers cannot address these problems. Instead, this paper presents the use of our recently proposed Shape concept. It was originally employed to model consistent features from fragmented regions, particularly when identical or similar objects coexist in an RGB-D image. Interestingly, we find that the Shape information effectively captures the moir\'e patterns in artifact images. Motivated by this discovery, we propose a ShapeMoir\'e method to aid in image demoir\'eing. Beyond modeling shape features at the patch-level, we further extend this to the global image-level and design a novel Shape-Architecture. Consequently, our proposed method, equipped with both ShapeConv and Shape-Architecture, can be seamlessly integrated into existing approaches without introducing additional parameters or computation overhead during inference. We conduct extensive experiments on four widely used datasets, and the results demonstrate that our ShapeMoir\'e achieves state-of-the-art performance, particularly in terms of the PSNR metric. We then apply our method across four popular architectures to showcase its generalization capabilities. Moreover, our ShapeMoir\'e is robust and viable under real-world demoir\'eing scenarios involving smartphone photographs.
SOGDet: Semantic-Occupancy Guided Multi-view 3D Object Detection
Aug 26, 2023In the field of autonomous driving, accurate and comprehensive perception of the 3D environment is crucial. Bird's Eye View (BEV) based methods have emerged as a promising solution for 3D object detection using multi-view images as input. However, existing 3D object detection methods often ignore the physical context in the environment, such as sidewalk and vegetation, resulting in sub-optimal performance. In this paper, we propose a novel approach called SOGDet (Semantic-Occupancy Guided Multi-view 3D Object Detection), that leverages a 3D semantic-occupancy branch to improve the accuracy of 3D object detection. In particular, the physical context modeled by semantic occupancy helps the detector to perceive the scenes in a more holistic view. Our SOGDet is flexible to use and can be seamlessly integrated with most existing BEV-based methods. To evaluate its effectiveness, we apply this approach to several state-of-the-art baselines and conduct extensive experiments on the exclusive nuScenes dataset. Our results show that SOGDet consistently enhance the performance of three baseline methods in terms of nuScenes Detection Score (NDS) and mean Average Precision (mAP). This indicates that the combination of 3D object detection and 3D semantic occupancy leads to a more comprehensive perception of the 3D environment, thereby aiding build more robust autonomous driving systems. The codes are available at: https://github.com/zhouqiu/SOGDet.