 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSimCast: Enhancing Precipitation Nowcasting with Short-to-Long Term Knowledge Distillation
Oct 09, 2025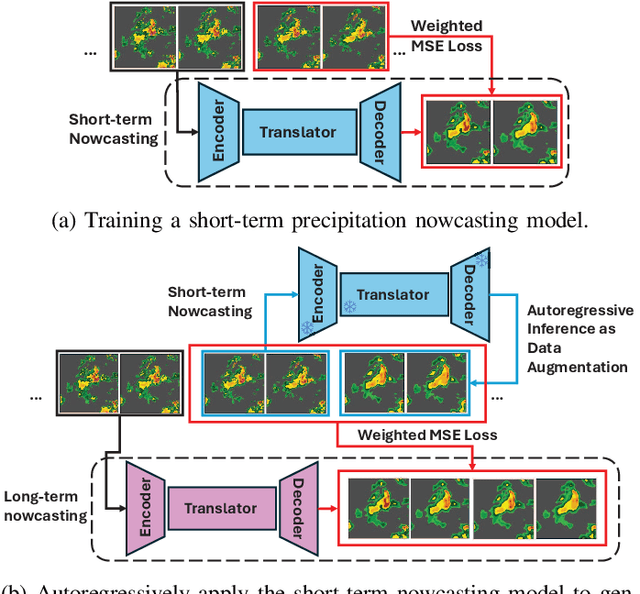
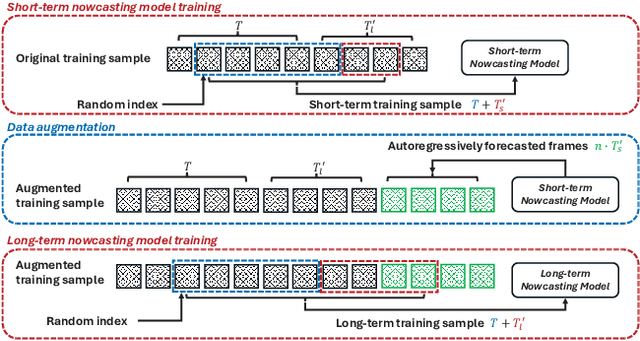
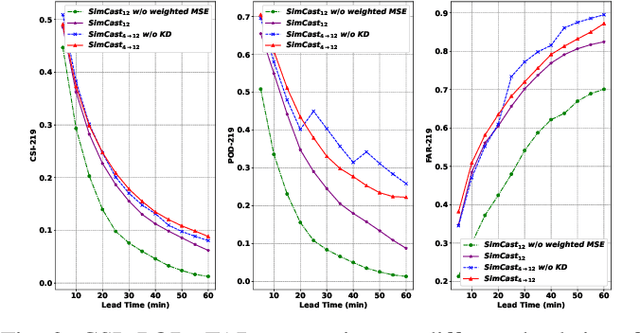
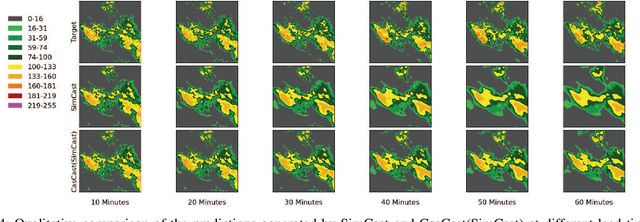
Precipitation nowcasting predicts future radar sequences based on current observations, which is a highly challenging task driven by the inherent complexity of the Earth system. Accurate nowcasting is of utmost importance for addressing various societal needs, including disaster management, agriculture, transportation, and energy optimization. As a complementary to existing non-autoregressive nowcasting approaches, we investigate the impact of prediction horizons on nowcasting models and propose SimCast, a novel training pipeline featuring a short-to-long term knowledge distillation technique coupled with a weighted MSE loss to prioritize heavy rainfall regions. Improved nowcasting predictions can be obtained without introducing additional overhead during inference. As SimCast generates deterministic predictions, we further integrate it into a diffusion-based framework named CasCast, leveraging the strengths from probabilistic models to overcome limitations such as blurriness and distribution shift in deterministic outputs. Extensive experimental results on three benchmark datasets validate the effectiveness of the proposed framework, achieving mean CSI scores of 0.452 on SEVIR, 0.474 on HKO-7, and 0.361 on MeteoNet, which outperforms existing approaches by a significant margin.
* accepted by ICME 2025
Unlocking Location Intelligence: A Survey from Deep Learning to The LLM Era
May 13, 2025Location Intelligence (LI), the science of transforming location-centric geospatial data into actionable knowledge, has become a cornerstone of modern spatial decision-making. The rapid evolution of Geospatial Representation Learning is fundamentally reshaping LI development through two successive technological revolutions: the deep learning breakthrough and the emerging large language model (LLM) paradigm. While deep neural networks (DNNs) have demonstrated remarkable success in automated feature extraction from structured geospatial data (e.g., satellite imagery, GPS trajectories), the recent integration of LLMs introduces transformative capabilities for cross-modal geospatial reasoning and unstructured geo-textual data processing. This survey presents a comprehensive review of geospatial representation learning across both technological eras, organizing them into a structured taxonomy based on the complete pipeline comprising: (1) data perspective, (2) methodological perspective and (3) application perspective. We also highlight current advancements, discuss existing limitations, and propose potential future research directions in the LLM era. This work offers a thorough exploration of the field and providing a roadmap for further innovation in LI. The summary of the up-to-date paper list can be found in https://github.com/CityMind-Lab/Awesome-Location-Intelligence and will undergo continuous updates.
OpenAVS: Training-Free Open-Vocabulary Audio Visual Segmentation with Foundational Models
Apr 30, 2025Audio-visual segmentation aims to separate sounding objects from videos by predicting pixel-level masks based on audio signals. Existing methods primarily concentrate on closed-set scenarios and direct audio-visual alignment and fusion, which limits their capability to generalize to new, unseen situations. In this paper, we propose OpenAVS, a novel training-free language-based approach that, for the first time, effectively aligns audio and visual modalities using text as a proxy for open-vocabulary Audio-Visual Segmentation (AVS). Equipped with multimedia foundation models, OpenAVS directly infers masks through 1) audio-to-text prompt generation, 2) LLM-guided prompt translation, and 3) text-to-visual sounding object segmentation. The objective of OpenAVS is to establish a simple yet flexible architecture that relies on the most appropriate foundation models by fully leveraging their capabilities to enable more effective knowledge transfer to the downstream AVS task. Moreover, we present a model-agnostic framework OpenAVS-ST that enables the integration of OpenAVS with any advanced supervised AVS model via pseudo-label based self-training. This approach enhances performance by effectively utilizing large-scale unlabeled data when available. Comprehensive experiments on three benchmark datasets demonstrate the superior performance of OpenAVS. It surpasses existing unsupervised, zero-shot, and few-shot AVS methods by a significant margin, achieving absolute performance gains of approximately 9.4% and 10.9% in mIoU and F-score, respectively, in challenging scenarios.
TAIL: Text-Audio Incremental Learning
Mar 06, 2025



Many studies combine text and audio to capture multi-modal information but they overlook the model's generalization ability on new datasets. Introducing new datasets may affect the feature space of the original dataset, leading to catastrophic forgetting. Meanwhile, large model parameters can significantly impact training performance. To address these limitations, we introduce a novel task called Text-Audio Incremental Learning (TAIL) task for text-audio retrieval, and propose a new method, PTAT, Prompt Tuning for Audio-Text incremental learning. This method utilizes prompt tuning to optimize the model parameters while incorporating an audio-text similarity and feature distillation module to effectively mitigate catastrophic forgetting. We benchmark our method and previous incremental learning methods on AudioCaps, Clotho, BBC Sound Effects and Audioset datasets, and our method outperforms previous methods significantly, particularly demonstrating stronger resistance to forgetting on older datasets. Compared to the full-parameters Finetune (Sequential) method, our model only requires 2.42\% of its parameters, achieving 4.46\% higher performance.
HVIS: A Human-like Vision and Inference System for Human Motion Prediction
Feb 24, 2025Grasping the intricacies of human motion, which involve perceiving spatio-temporal dependence and multi-scale effects, is essential for predicting human motion. While humans inherently possess the requisite skills to navigate this issue, it proves to be markedly more challenging for machines to emulate. To bridge the gap, we propose the Human-like Vision and Inference System (HVIS) for human motion prediction, which is designed to emulate human observation and forecast future movements. HVIS comprises two components: the human-like vision encode (HVE) module and the human-like motion inference (HMI) module. The HVE module mimics and refines the human visual process, incorporating a retina-analog component that captures spatiotemporal information separately to avoid unnecessary crosstalk. Additionally, a visual cortex-analogy component is designed to hierarchically extract and treat complex motion features, focusing on both global and local features of human poses. The HMI is employed to simulate the multi-stage learning model of the human brain. The spontaneous learning network simulates the neuronal fracture generation process for the adversarial generation of future motions. Subsequently, the deliberate learning network is optimized for hard-to-train joints to prevent misleading learning. Experimental results demonstrate that our method achieves new state-of-the-art performance, significantly outperforming existing methods by 19.8% on Human3.6M, 15.7% on CMU Mocap, and 11.1% on G3D.
Causal-Inspired Multitask Learning for Video-Based Human Pose Estimation
Jan 24, 2025Video-based human pose estimation has long been a fundamental yet challenging problem in computer vision. Previous studies focus on spatio-temporal modeling through the enhancement of architecture design and optimization strategies. However, they overlook the causal relationships in the joints, leading to models that may be overly tailored and thus estimate poorly to challenging scenes. Therefore, adequate causal reasoning capability, coupled with good interpretability of model, are both indispensable and prerequisite for achieving reliable results. In this paper, we pioneer a causal perspective on pose estimation and introduce a causal-inspired multitask learning framework, consisting of two stages. \textit{In the first stage}, we try to endow the model with causal spatio-temporal modeling ability by introducing two self-supervision auxiliary tasks. Specifically, these auxiliary tasks enable the network to infer challenging keypoints based on observed keypoint information, thereby imbuing causal reasoning capabilities into the model and making it robust to challenging scenes. \textit{In the second stage}, we argue that not all feature tokens contribute equally to pose estimation. Prioritizing causal (keypoint-relevant) tokens is crucial to achieve reliable results, which could improve the interpretability of the model. To this end, we propose a Token Causal Importance Selection module to identify the causal tokens and non-causal tokens (\textit{e.g.}, background and objects). Additionally, non-causal tokens could provide potentially beneficial cues but may be redundant. We further introduce a non-causal tokens clustering module to merge the similar non-causal tokens. Extensive experiments show that our method outperforms state-of-the-art methods on three large-scale benchmark datasets.
Manifold-Aware Local Feature Modeling for Semi-Supervised Medical Image Segmentation
Oct 14, 2024Achieving precise medical image segmentation is vital for effective treatment planning and accurate disease diagnosis. Traditional fully-supervised deep learning methods, though highly precise, are heavily reliant on large volumes of labeled data, which are often difficult to obtain due to the expertise required for medical annotations. This has led to the rise of semi-supervised learning approaches that utilize both labeled and unlabeled data to mitigate the label scarcity issue. In this paper, we introduce the Manifold-Aware Local Feature Modeling Network (MANet), which enhances the U-Net architecture by incorporating manifold supervision signals. This approach focuses on improving boundary accuracy, which is crucial for reliable medical diagnosis. To further extend the versatility of our method, we propose two variants: MA-Sobel and MA-Canny. The MA-Sobel variant employs the Sobel operator, which is effective for both 2D and 3D data, while the MA-Canny variant utilizes the Canny operator, specifically designed for 2D images, to refine boundary detection. These variants allow our method to adapt to various medical image modalities and dimensionalities, ensuring broader applicability. Our extensive experiments on datasets such as ACDC, LA, and Pancreas-NIH demonstrate that MANet consistently surpasses state-of-the-art methods in performance metrics like Dice and Jaccard scores. The proposed method also shows improved generalization across various semi-supervised segmentation networks, highlighting its robustness and effectiveness. Visual analysis of segmentation results confirms that MANet offers clearer and more accurate class boundaries, underscoring the value of manifold information in medical image segmentation.
Joint-Motion Mutual Learning for Pose Estimation in Videos
Aug 05, 2024Human pose estimation in videos has long been a compelling yet challenging task within the realm of computer vision. Nevertheless, this task remains difficult because of the complex video scenes, such as video defocus and self-occlusion. Recent methods strive to integrate multi-frame visual features generated by a backbone network for pose estimation. However, they often ignore the useful joint information encoded in the initial heatmap, which is a by-product of the backbone generation. Comparatively, methods that attempt to refine the initial heatmap fail to consider any spatio-temporal motion features. As a result, the performance of existing methods for pose estimation falls short due to the lack of ability to leverage both local joint (heatmap) information and global motion (feature) dynamics. To address this problem, we propose a novel joint-motion mutual learning framework for pose estimation, which effectively concentrates on both local joint dependency and global pixel-level motion dynamics. Specifically, we introduce a context-aware joint learner that adaptively leverages initial heatmaps and motion flow to retrieve robust local joint feature. Given that local joint feature and global motion flow are complementary, we further propose a progressive joint-motion mutual learning that synergistically exchanges information and interactively learns between joint feature and motion flow to improve the capability of the model. More importantly, to capture more diverse joint and motion cues, we theoretically analyze and propose an information orthogonality objective to avoid learning redundant information from multi-cues. Empirical experiments show our method outperforms prior arts on three challenging benchmarks.
PetalView: Fine-grained Location and Orientation Extraction of Street-view Images via Cross-view Local Search with Supplementary Materials
Jun 19, 2024



Satellite-based street-view information extraction by cross-view matching refers to a task that extracts the location and orientation information of a given street-view image query by using one or multiple geo-referenced satellite images. Recent work has initiated a new research direction to find accurate information within a local area covered by one satellite image centered at a location prior (e.g., from GPS). It can be used as a standalone solution or complementary step following a large-scale search with multiple satellite candidates. However, these existing works require an accurate initial orientation (angle) prior (e.g., from IMU) and/or do not efficiently search through all possible poses. To allow efficient search and to give accurate prediction regardless of the existence or the accuracy of the angle prior, we present PetalView extractors with multi-scale search. The PetalView extractors give semantically meaningful features that are equivalent across two drastically different views, and the multi-scale search strategy efficiently inspects the satellite image from coarse to fine granularity to provide sub-meter and sub-degree precision extraction. Moreover, when an angle prior is given, we propose a learnable prior angle mixer to utilize this information. Our method obtains the best performance on the VIGOR dataset and successfully improves the performance on KITTI dataset test 1 set with the recall within 1 meter (r@1m) for location estimation to 68.88% and recall within 1 degree (r@1d) 21.10% when no angle prior is available, and with angle prior achieves stable estimations at r@1m and r@1d above 70% and 21%, up to a 40-degree noise level.
* This paper has been accepted by ACM Multimedia 2023. This version contains additional supplementary materials
Prompt-Enhanced Spatio-Temporal Graph Transfer Learning
May 21, 2024Spatio-temporal graph neural networks have demonstrated efficacy in capturing complex dependencies for urban computing tasks such as forecasting and kriging. However, their performance is constrained by the reliance on extensive data for training on specific tasks, which limits their adaptability to new urban domains with varied demands. Although transfer learning has been proposed to address this problem by leveraging knowledge across domains, cross-task generalization remains underexplored in spatio-temporal graph transfer learning methods due to the absence of a unified framework. To bridge this gap, we propose Spatio-Temporal Graph Prompting (STGP), a prompt-enhanced transfer learning framework capable of adapting to diverse tasks in data-scarce domains. Specifically, we first unify different tasks into a single template and introduce a task-agnostic network architecture that aligns with this template. This approach enables the capture of spatio-temporal dependencies shared across tasks. Furthermore, we employ learnable prompts to achieve domain and task transfer in a two-stage prompting pipeline, enabling the prompts to effectively capture domain knowledge and task-specific properties at each stage. Extensive experiments demonstrate that STGP outperforms state-of-the-art baselines in three downstream tasks forecasting, kriging, and extrapolation by a notable margin.