 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight Alignment Improves LLM Safety via Model Self-Reflection with a Single Neuron
Feb 02, 2026The safety of large language models (LLMs) has increasingly emerged as a fundamental aspect of their development. Existing safety alignment for LLMs is predominantly achieved through post-training methods, which are computationally expensive and often fail to generalize well across different models. A small number of lightweight alignment approaches either rely heavily on prior-computed safety injections or depend excessively on the model's own capabilities, resulting in limited generalization and degraded efficiency and usability during generation. In this work, we propose a safety-aware decoding method that requires only low-cost training of an expert model and employs a single neuron as a gating mechanism. By effectively balancing the model's intrinsic capabilities with external guidance, our approach simultaneously preserves utility and enhances output safety. It demonstrates clear advantages in training overhead and generalization across model scales, offering a new perspective on lightweight alignment for the safe and practical deployment of large language models. Code: https://github.com/Beijing-AISI/NGSD.
TEFormer: Structured Bidirectional Temporal Enhancement Modeling in Spiking Transformers
Jan 26, 2026In recent years, Spiking Neural Networks (SNNs) have achieved remarkable progress, with Spiking Transformers emerging as a promising architecture for energy-efficient sequence modeling. However, existing Spiking Transformers still lack a principled mechanism for effective temporal fusion, limiting their ability to fully exploit spatiotemporal dependencies. Inspired by feedforward-feedback modulation in the human visual pathway, we propose TEFormer, the first Spiking Transformer framework that achieves bidirectional temporal fusion by decoupling temporal modeling across its core components. Specifically, TEFormer employs a lightweight and hyperparameter-free forward temporal fusion mechanism in the attention module, enabling fully parallel computation, while incorporating a backward gated recurrent structure in the MLP to aggregate temporal information in reverse order and reinforce temporal consistency. Extensive experiments across a wide range of benchmarks demonstrate that TEFormer consistently and significantly outperforms strong SNN and Spiking Transformer baselines under diverse datasets. Moreover, through the first systematic evaluation of Spiking Transformers under different neural encoding schemes, we show that the performance gains of TEFormer remain stable across encoding choices, indicating that the improved temporal modeling directly translates into reliable accuracy improvements across varied spiking representations. These results collectively establish TEFormer as an effective and general framework for temporal modeling in Spiking Transformers.
PandaGuard: Systematic Evaluation of LLM Safety against Jailbreaking Attacks
May 22, 2025



Large language models (LLMs) have achieved remarkable capabilities but remain vulnerable to adversarial prompts known as jailbreaks, which can bypass safety alignment and elicit harmful outputs. Despite growing efforts in LLM safety research, existing evaluations are often fragmented, focused on isolated attack or defense techniques, and lack systematic, reproducible analysis. In this work, we introduce PandaGuard, a unified and modular framework that models LLM jailbreak safety as a multi-agent system comprising attackers, defenders, and judges. Our framework implements 19 attack methods and 12 defense mechanisms, along with multiple judgment strategies, all within a flexible plugin architecture supporting diverse LLM interfaces, multiple interaction modes, and configuration-driven experimentation that enhances reproducibility and practical deployment. Built on this framework, we develop PandaBench, a comprehensive benchmark that evaluates the interactions between these attack/defense methods across 49 LLMs and various judgment approaches, requiring over 3 billion tokens to execute. Our extensive evaluation reveals key insights into model vulnerabilities, defense cost-performance trade-offs, and judge consistency. We find that no single defense is optimal across all dimensions and that judge disagreement introduces nontrivial variance in safety assessments. We release the code, configurations, and evaluation results to support transparent and reproducible research in LLM safety.
STEP: A Unified Spiking Transformer Evaluation Platform for Fair and Reproducible Benchmarking
May 16, 2025Spiking Transformers have recently emerged as promising architectures for combining the efficiency of spiking neural networks with the representational power of self-attention. However, the lack of standardized implementations, evaluation pipelines, and consistent design choices has hindered fair comparison and principled analysis. In this paper, we introduce \textbf{STEP}, a unified benchmark framework for Spiking Transformers that supports a wide range of tasks, including classification, segmentation, and detection across static, event-based, and sequential datasets. STEP provides modular support for diverse components such as spiking neurons, input encodings, surrogate gradients, and multiple backends (e.g., SpikingJelly, BrainCog). Using STEP, we reproduce and evaluate several representative models, and conduct systematic ablation studies on attention design, neuron types, encoding schemes, and temporal modeling capabilities. We also propose a unified analytical model for energy estimation, accounting for spike sparsity, bitwidth, and memory access, and show that quantized ANNs may offer comparable or better energy efficiency. Our results suggest that current Spiking Transformers rely heavily on convolutional frontends and lack strong temporal modeling, underscoring the need for spike-native architectural innovations. The full code is available at: https://github.com/Fancyssc/STEP
Biologically Inspired Spiking Diffusion Model with Adaptive Lateral Selection Mechanism
Mar 31, 2025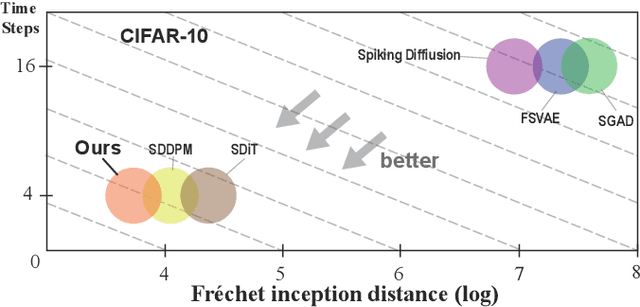

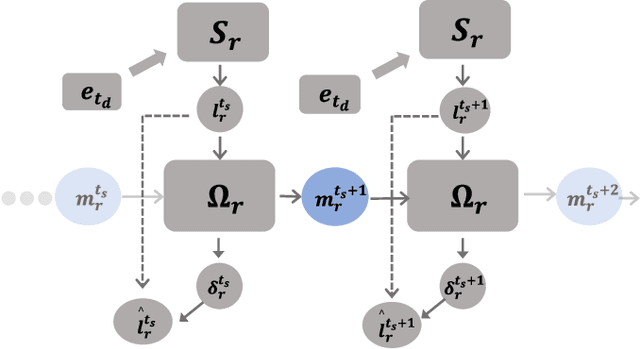

Lateral connection is a fundamental feature of biological neural circuits, facilitating local information processing and adaptive learning. In this work, we integrate lateral connections with a substructure selection network to develop a novel diffusion model based on spiking neural networks (SNNs). Unlike conventional artificial neural networks, SNNs employ an intrinsic spiking inner loop to process sequential binary spikes. We leverage this spiking inner loop alongside a lateral connection mechanism to iteratively refine the substructure selection network, enhancing model adaptability and expressivity. Specifically, we design a lateral connection framework comprising a learnable lateral matrix and a lateral mapping function, both implemented using spiking neurons, to dynamically update lateral connections. Through mathematical modeling, we establish that the proposed lateral update mechanism, under a well-defined local objective, aligns with biologically plausible synaptic plasticity principles. Extensive experiments validate the effectiveness of our approach, analyzing the role of substructure selection and lateral connection during training. Furthermore, quantitative comparisons demonstrate that our model consistently surpasses state-of-the-art SNN-based generative models across multiple benchmark datasets.
Manifold-Aware Local Feature Modeling for Semi-Supervised Medical Image Segmentation
Oct 14, 2024Achieving precise medical image segmentation is vital for effective treatment planning and accurate disease diagnosis. Traditional fully-supervised deep learning methods, though highly precise, are heavily reliant on large volumes of labeled data, which are often difficult to obtain due to the expertise required for medical annotations. This has led to the rise of semi-supervised learning approaches that utilize both labeled and unlabeled data to mitigate the label scarcity issue. In this paper, we introduce the Manifold-Aware Local Feature Modeling Network (MANet), which enhances the U-Net architecture by incorporating manifold supervision signals. This approach focuses on improving boundary accuracy, which is crucial for reliable medical diagnosis. To further extend the versatility of our method, we propose two variants: MA-Sobel and MA-Canny. The MA-Sobel variant employs the Sobel operator, which is effective for both 2D and 3D data, while the MA-Canny variant utilizes the Canny operator, specifically designed for 2D images, to refine boundary detection. These variants allow our method to adapt to various medical image modalities and dimensionalities, ensuring broader applicability. Our extensive experiments on datasets such as ACDC, LA, and Pancreas-NIH demonstrate that MANet consistently surpasses state-of-the-art methods in performance metrics like Dice and Jaccard scores. The proposed method also shows improved generalization across various semi-supervised segmentation networks, highlighting its robustness and effectiveness. Visual analysis of segmentation results confirms that MANet offers clearer and more accurate class boundaries, underscoring the value of manifold information in medical image segmentation.
Time Cell Inspired Temporal Codebook in Spiking Neural Networks for Enhanced Image Generation
May 23, 2024



This paper presents a novel approach leveraging Spiking Neural Networks (SNNs) to construct a Variational Quantized Autoencoder (VQ-VAE) with a temporal codebook inspired by hippocampal time cells. This design captures and utilizes temporal dependencies, significantly enhancing the generative capabilities of SNNs. Neuroscientific research has identified hippocampal "time cells" that fire sequentially during temporally structured experiences. Our temporal codebook emulates this behavior by triggering the activation of time cell populations based on similarity measures as input stimuli pass through it. We conducted extensive experiments on standard benchmark datasets, including MNIST, FashionMNIST, CIFAR10, CelebA, and downsampled LSUN Bedroom, to validate our model's performance. Furthermore, we evaluated the effectiveness of the temporal codebook on neuromorphic datasets NMNIST and DVS-CIFAR10, and demonstrated the model's capability with high-resolution datasets such as CelebA-HQ, LSUN Bedroom, and LSUN Church. The experimental results indicate that our method consistently outperforms existing SNN-based generative models across multiple datasets, achieving state-of-the-art performance. Notably, our approach excels in generating high-resolution and temporally consistent data, underscoring the crucial role of temporal information in SNN-based generative modeling.
ShapeMoiré: Channel-Wise Shape-Guided Network for Image Demoiréing
Apr 28, 2024
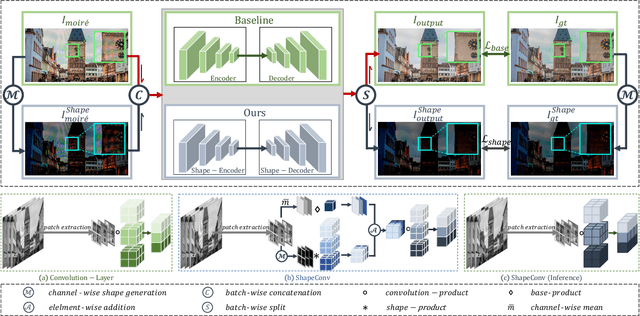
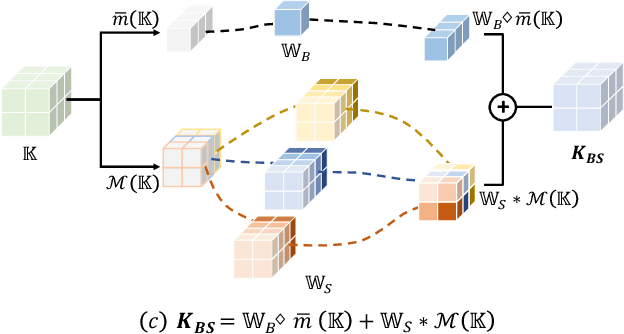

Photographing optoelectronic displays often introduces unwanted moir\'e patterns due to analog signal interference between the pixel grids of the display and the camera sensor arrays. This work identifies two problems that are largely ignored by existing image demoir\'eing approaches: 1) moir\'e patterns vary across different channels (RGB); 2) repetitive patterns are constantly observed. However, employing conventional convolutional (CNN) layers cannot address these problems. Instead, this paper presents the use of our recently proposed Shape concept. It was originally employed to model consistent features from fragmented regions, particularly when identical or similar objects coexist in an RGB-D image. Interestingly, we find that the Shape information effectively captures the moir\'e patterns in artifact images. Motivated by this discovery, we propose a ShapeMoir\'e method to aid in image demoir\'eing. Beyond modeling shape features at the patch-level, we further extend this to the global image-level and design a novel Shape-Architecture. Consequently, our proposed method, equipped with both ShapeConv and Shape-Architecture, can be seamlessly integrated into existing approaches without introducing additional parameters or computation overhead during inference. We conduct extensive experiments on four widely used datasets, and the results demonstrate that our ShapeMoir\'e achieves state-of-the-art performance, particularly in terms of the PSNR metric. We then apply our method across four popular architectures to showcase its generalization capabilities. Moreover, our ShapeMoir\'e is robust and viable under real-world demoir\'eing scenarios involving smartphone photographs.
TIM: An Efficient Temporal Interaction Module for Spiking Transformer
Jan 23, 2024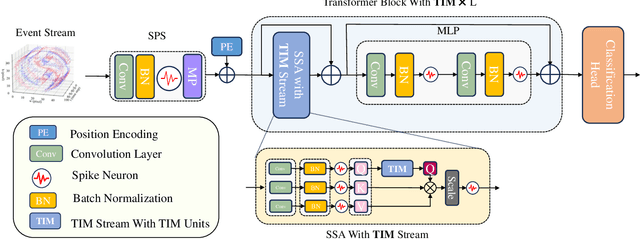
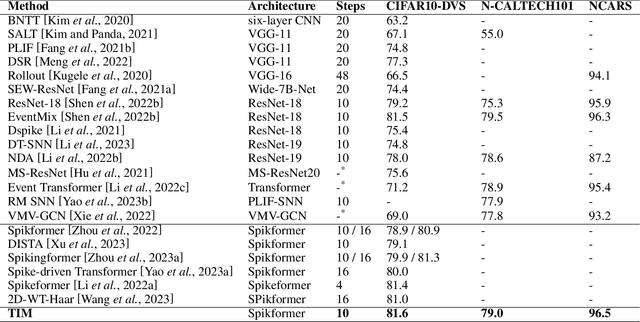
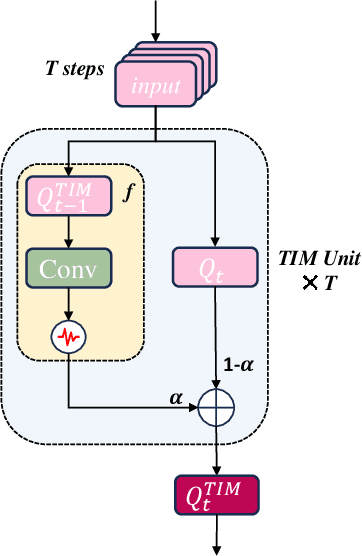

Spiking Neural Networks (SNNs), as the third generation of neural networks, have gained prominence for their biological plausibility and computational efficiency, especially in processing diverse datasets. The integration of attention mechanisms, inspired by advancements in neural network architectures, has led to the development of Spiking Transformers. These have shown promise in enhancing SNNs' capabilities, particularly in the realms of both static and neuromorphic datasets. Despite their progress, a discernible gap exists in these systems, specifically in the Spiking Self Attention (SSA) mechanism's effectiveness in leveraging the temporal processing potential of SNNs. To address this, we introduce the Temporal Interaction Module (TIM), a novel, convolution-based enhancement designed to augment the temporal data processing abilities within SNN architectures. TIM's integration into existing SNN frameworks is seamless and efficient, requiring minimal additional parameters while significantly boosting their temporal information handling capabilities. Through rigorous experimentation, TIM has demonstrated its effectiveness in exploiting temporal information, leading to state-of-the-art performance across various neuromorphic datasets.