 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCovo-Audio Technical Report
Feb 10, 2026In this work, we present Covo-Audio, a 7B-parameter end-to-end LALM that directly processes continuous audio inputs and generates audio outputs within a single unified architecture. Through large-scale curated pretraining and targeted post-training, Covo-Audio achieves state-of-the-art or competitive performance among models of comparable scale across a broad spectrum of tasks, including speech-text modeling, spoken dialogue, speech understanding, audio understanding, and full-duplex voice interaction. Extensive evaluations demonstrate that the pretrained foundation model exhibits strong speech-text comprehension and semantic reasoning capabilities on multiple benchmarks, outperforming representative open-source models of comparable scale. Furthermore, Covo-Audio-Chat, the dialogue-oriented variant, demonstrates strong spoken conversational abilities, including understanding, contextual reasoning, instruction following, and generating contextually appropriate and empathetic responses, validating its applicability to real-world conversational assistant scenarios. Covo-Audio-Chat-FD, the evolved full-duplex model, achieves substantially superior performance on both spoken dialogue capabilities and full-duplex interaction behaviors, demonstrating its competence in practical robustness. To mitigate the high cost of deploying end-to-end LALMs for natural conversational systems, we propose an intelligence-speaker decoupling strategy that separates dialogue intelligence from voice rendering, enabling flexible voice customization with minimal text-to-speech (TTS) data while preserving dialogue performance. Overall, our results highlight the strong potential of 7B-scale models to integrate sophisticated audio intelligence with high-level semantic reasoning, and suggest a scalable path toward more capable and versatile LALMs.
Plug-and-Play Parameter-Efficient Tuning of Embeddings for Federated Recommendation
Dec 14, 2025With the rise of cloud-edge collaboration, recommendation services are increasingly trained in distributed environments. Federated Recommendation (FR) enables such multi-end collaborative training while preserving privacy by sharing model parameters instead of raw data. However, the large number of parameters, primarily due to the massive item embeddings, significantly hampers communication efficiency. While existing studies mainly focus on improving the efficiency of FR models, they largely overlook the issue of embedding parameter overhead. To address this gap, we propose a FR training framework with Parameter-Efficient Fine-Tuning (PEFT) based embedding designed to reduce the volume of embedding parameters that need to be transmitted. Our approach offers a lightweight, plugin-style solution that can be seamlessly integrated into existing FR methods. In addition to incorporating common PEFT techniques such as LoRA and Hash-based encoding, we explore the use of Residual Quantized Variational Autoencoders (RQ-VAE) as a novel PEFT strategy within our framework. Extensive experiments across various FR model backbones and datasets demonstrate that our framework significantly reduces communication overhead while improving accuracy. The source code is available at https://github.com/young1010/FedPEFT.
PandaGuard: Systematic Evaluation of LLM Safety against Jailbreaking Attacks
May 22, 2025



Large language models (LLMs) have achieved remarkable capabilities but remain vulnerable to adversarial prompts known as jailbreaks, which can bypass safety alignment and elicit harmful outputs. Despite growing efforts in LLM safety research, existing evaluations are often fragmented, focused on isolated attack or defense techniques, and lack systematic, reproducible analysis. In this work, we introduce PandaGuard, a unified and modular framework that models LLM jailbreak safety as a multi-agent system comprising attackers, defenders, and judges. Our framework implements 19 attack methods and 12 defense mechanisms, along with multiple judgment strategies, all within a flexible plugin architecture supporting diverse LLM interfaces, multiple interaction modes, and configuration-driven experimentation that enhances reproducibility and practical deployment. Built on this framework, we develop PandaBench, a comprehensive benchmark that evaluates the interactions between these attack/defense methods across 49 LLMs and various judgment approaches, requiring over 3 billion tokens to execute. Our extensive evaluation reveals key insights into model vulnerabilities, defense cost-performance trade-offs, and judge consistency. We find that no single defense is optimal across all dimensions and that judge disagreement introduces nontrivial variance in safety assessments. We release the code, configurations, and evaluation results to support transparent and reproducible research in LLM safety.
Incorporating brain-inspired mechanisms for multimodal learning in artificial intelligence
May 15, 2025Multimodal learning enhances the perceptual capabilities of cognitive systems by integrating information from different sensory modalities. However, existing multimodal fusion research typically assumes static integration, not fully incorporating key dynamic mechanisms found in the brain. Specifically, the brain exhibits an inverse effectiveness phenomenon, wherein weaker unimodal cues yield stronger multisensory integration benefits; conversely, when individual modal cues are stronger, the effect of fusion is diminished. This mechanism enables biological systems to achieve robust cognition even with scarce or noisy perceptual cues. Inspired by this biological mechanism, we explore the relationship between multimodal output and information from individual modalities, proposing an inverse effectiveness driven multimodal fusion (IEMF) strategy. By incorporating this strategy into neural networks, we achieve more efficient integration with improved model performance and computational efficiency, demonstrating up to 50% reduction in computational cost across diverse fusion methods. We conduct experiments on audio-visual classification, continual learning, and question answering tasks to validate our method. Results consistently demonstrate that our method performs excellently in these tasks. To verify universality and generalization, we also conduct experiments on Artificial Neural Networks (ANN) and Spiking Neural Networks (SNN), with results showing good adaptability to both network types. Our research emphasizes the potential of incorporating biologically inspired mechanisms into multimodal networks and provides promising directions for the future development of multimodal artificial intelligence. The code is available at https://github.com/Brain-Cog-Lab/IEMF.
Enhancing Audio-Visual Spiking Neural Networks through Semantic-Alignment and Cross-Modal Residual Learning
Feb 18, 2025



Humans interpret and perceive the world by integrating sensory information from multiple modalities, such as vision and hearing. Spiking Neural Networks (SNNs), as brain-inspired computational models, exhibit unique advantages in emulating the brain's information processing mechanisms. However, existing SNN models primarily focus on unimodal processing and lack efficient cross-modal information fusion, thereby limiting their effectiveness in real-world multimodal scenarios. To address this challenge, we propose a semantic-alignment cross-modal residual learning (S-CMRL) framework, a Transformer-based multimodal SNN architecture designed for effective audio-visual integration. S-CMRL leverages a spatiotemporal spiking attention mechanism to extract complementary features across modalities, and incorporates a cross-modal residual learning strategy to enhance feature integration. Additionally, a semantic alignment optimization mechanism is introduced to align cross-modal features within a shared semantic space, improving their consistency and complementarity. Extensive experiments on three benchmark datasets CREMA-D, UrbanSound8K-AV, and MNISTDVS-NTIDIGITS demonstrate that S-CMRL significantly outperforms existing multimodal SNN methods, achieving the state-of-the-art performance. The code is publicly available at https://github.com/Brain-Cog-Lab/S-CMRL.
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.
Harnessing Task Overload for Scalable Jailbreak Attacks on Large Language Models
Oct 05, 2024



Large Language Models (LLMs) remain vulnerable to jailbreak attacks that bypass their safety mechanisms. Existing attack methods are fixed or specifically tailored for certain models and cannot flexibly adjust attack strength, which is critical for generalization when attacking models of various sizes. We introduce a novel scalable jailbreak attack that preempts the activation of an LLM's safety policies by occupying its computational resources. Our method involves engaging the LLM in a resource-intensive preliminary task - a Character Map lookup and decoding process - before presenting the target instruction. By saturating the model's processing capacity, we prevent the activation of safety protocols when processing the subsequent instruction. Extensive experiments on state-of-the-art LLMs demonstrate that our method achieves a high success rate in bypassing safety measures without requiring gradient access, manual prompt engineering. We verified our approach offers a scalable attack that quantifies attack strength and adapts to different model scales at the optimal strength. We shows safety policies of LLMs might be more susceptible to resource constraints. Our findings reveal a critical vulnerability in current LLM safety designs, highlighting the need for more robust defense strategies that account for resource-intense condition.
Jailbreak Antidote: Runtime Safety-Utility Balance via Sparse Representation Adjustment in Large Language Models
Oct 03, 2024



As large language models (LLMs) become integral to various applications, ensuring both their safety and utility is paramount. Jailbreak attacks, which manipulate LLMs into generating harmful content, pose significant challenges to this balance. Existing defenses, such as prompt engineering and safety fine-tuning, often introduce computational overhead, increase inference latency, and lack runtime flexibility. Moreover, overly restrictive safety measures can degrade model utility by causing refusals of benign queries. In this paper, we introduce Jailbreak Antidote, a method that enables real-time adjustment of LLM safety preferences by manipulating a sparse subset of the model's internal states during inference. By shifting the model's hidden representations along a safety direction with varying strengths, we achieve flexible control over the safety-utility balance without additional token overhead or inference delays. Our analysis reveals that safety-related information in LLMs is sparsely distributed; adjusting approximately 5% of the internal state is as effective as modifying the entire state. Extensive experiments on nine LLMs (ranging from 2 billion to 72 billion parameters), evaluated against ten jailbreak attack methods and compared with six defense strategies, validate the effectiveness and efficiency of our approach. By directly manipulating internal states during reasoning, Jailbreak Antidote offers a lightweight, scalable solution that enhances LLM safety while preserving utility, opening new possibilities for real-time safety mechanisms in widely-deployed AI systems.
Local Search for Integer Quadratic Programming
Sep 29, 2024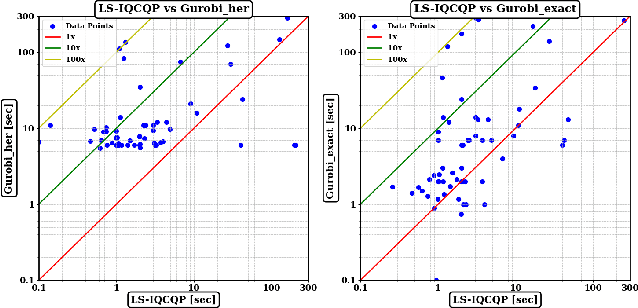
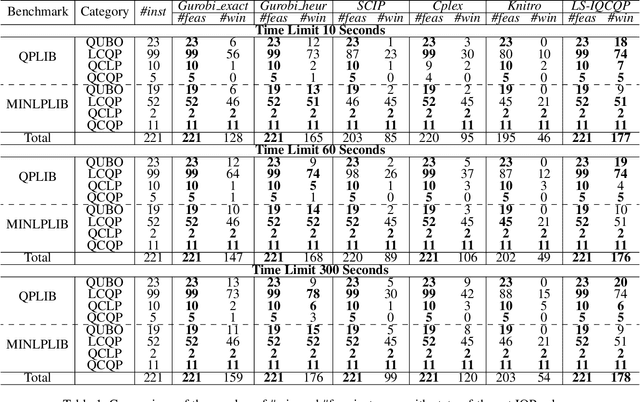

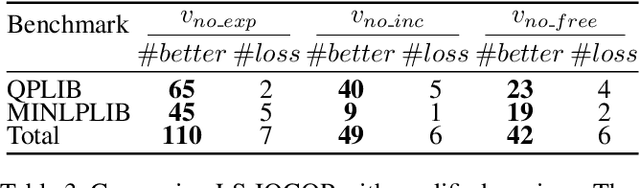
Integer Quadratic Programming (IQP) is an important problem in operations research. Local search is a powerful method for solving hard problems, but the research on local search algorithms for IQP solving is still on its early stage. This paper develops an efficient local search solver for solving general IQP, called LS-IQCQP. We propose four new local search operators for IQP that can handle quadratic terms in the objective function, constraints or both. Furthermore, a two-mode local search algorithm is introduced, utilizing newly designed scoring functions to enhance the search process. Experiments are conducted on standard IQP benchmarks QPLIB and MINLPLIB, comparing LS-IQCQP with several state-of-the-art IQP solvers. Experimental results demonstrate that LS-IQCQP is competitive with the most powerful commercial solver Gurobi and outperforms other state-of-the-art solvers. Moreover, LS-IQCQP has established 6 new records for QPLIB and MINLPLIB open instances.
CACE-Net: Co-guidance Attention and Contrastive Enhancement for Effective Audio-Visual Event Localization
Aug 04, 2024

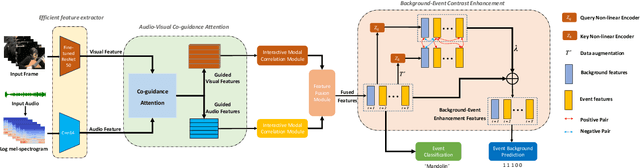
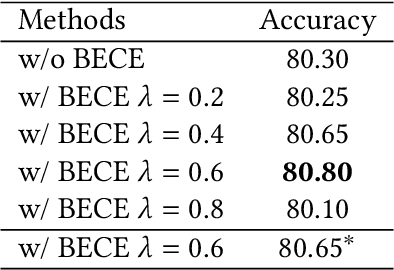
The audio-visual event localization task requires identifying concurrent visual and auditory events from unconstrained videos within a network model, locating them, and classifying their category. The efficient extraction and integration of audio and visual modal information have always been challenging in this field. In this paper, we introduce CACE-Net, which differs from most existing methods that solely use audio signals to guide visual information. We propose an audio-visual co-guidance attention mechanism that allows for adaptive bi-directional cross-modal attentional guidance between audio and visual information, thus reducing inconsistencies between modalities. Moreover, we have observed that existing methods have difficulty distinguishing between similar background and event and lack the fine-grained features for event classification. Consequently, we employ background-event contrast enhancement to increase the discrimination of fused feature and fine-tuned pre-trained model to extract more refined and discernible features from complex multimodal inputs. Specifically, we have enhanced the model's ability to discern subtle differences between event and background and improved the accuracy of event classification in our model. Experiments on the AVE dataset demonstrate that CACE-Net sets a new benchmark in the audio-visual event localization task, proving the effectiveness of our proposed methods in handling complex multimodal learning and event localization in unconstrained videos. Code is available at https://github.com/Brain-Cog-Lab/CACE-Net.