 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAI-UI Technical Report: Real-World Centric Foundation GUI Agents
Dec 26, 2025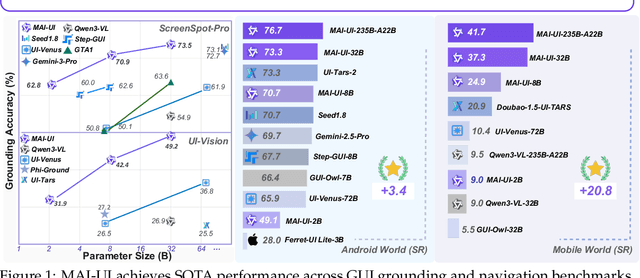

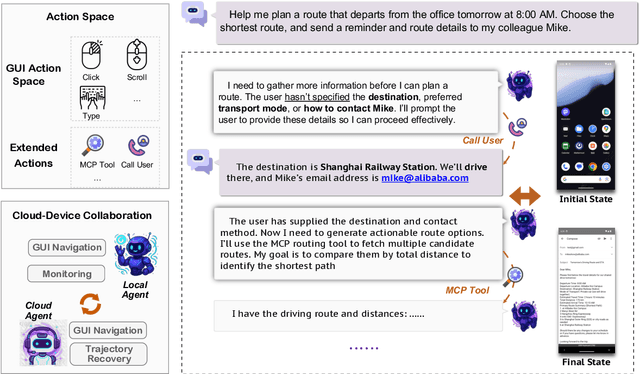
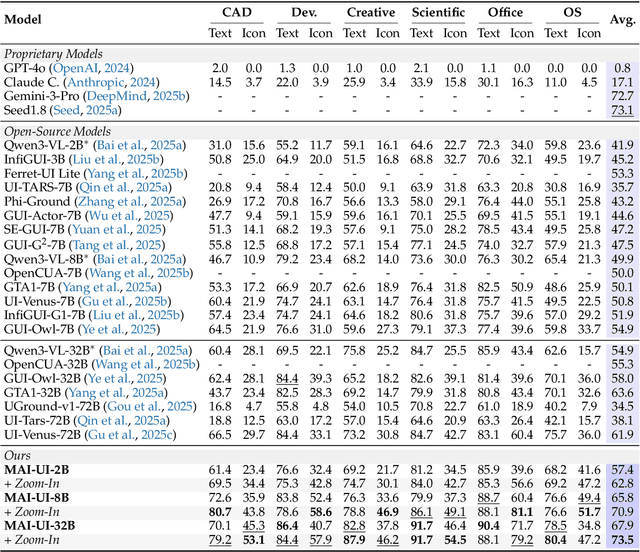
The development of GUI agents could revolutionize the next generation of human-computer interaction. Motivated by this vision, we present MAI-UI, a family of foundation GUI agents spanning the full spectrum of sizes, including 2B, 8B, 32B, and 235B-A22B variants. We identify four key challenges to realistic deployment: the lack of native agent-user interaction, the limits of UI-only operation, the absence of a practical deployment architecture, and brittleness in dynamic environments. MAI-UI addresses these issues with a unified methodology: a self-evolving data pipeline that expands the navigation data to include user interaction and MCP tool calls, a native device-cloud collaboration system routes execution by task state, and an online RL framework with advanced optimizations to scale parallel environments and context length. MAI-UI establishes new state-of-the-art across GUI grounding and mobile navigation. On grounding benchmarks, it reaches 73.5% on ScreenSpot-Pro, 91.3% on MMBench GUI L2, 70.9% on OSWorld-G, and 49.2% on UI-Vision, surpassing Gemini-3-Pro and Seed1.8 on ScreenSpot-Pro. On mobile GUI navigation, it sets a new SOTA of 76.7% on AndroidWorld, surpassing UI-Tars-2, Gemini-2.5-Pro and Seed1.8. On MobileWorld, MAI-UI obtains 41.7% success rate, significantly outperforming end-to-end GUI models and competitive with Gemini-3-Pro based agentic frameworks. Our online RL experiments show significant gains from scaling parallel environments from 32 to 512 (+5.2 points) and increasing environment step budget from 15 to 50 (+4.3 points). Finally, the native device-cloud collaboration system improves on-device performance by 33%, reduces cloud model calls by over 40%, and preserves user privacy.
MobileWorld: Benchmarking Autonomous Mobile Agents in Agent-User Interactive, and MCP-Augmented Environments
Dec 22, 2025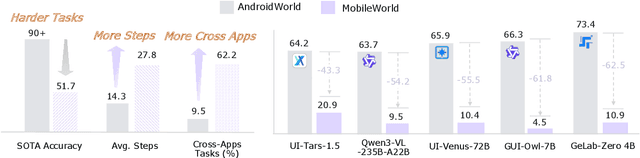
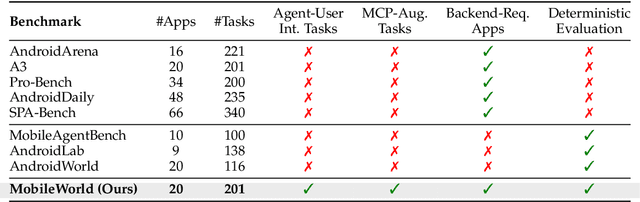
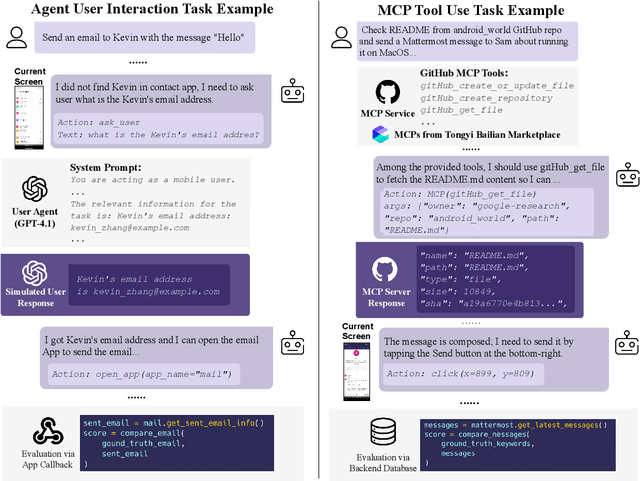

Among existing online mobile-use benchmarks, AndroidWorld has emerged as the dominant benchmark due to its reproducible environment and deterministic evaluation; however, recent agents achieving over 90% success rates indicate its saturation and motivate the need for a more challenging benchmark. In addition, its environment lacks key application categories, such as e-commerce and enterprise communication, and does not reflect realistic mobile-use scenarios characterized by vague user instructions and hybrid tool usage. To bridge this gap, we introduce MobileWorld, a substantially more challenging benchmark designed to better reflect real-world mobile usage, comprising 201 tasks across 20 applications, while maintaining the same level of reproducible evaluation as AndroidWorld. The difficulty of MobileWorld is twofold. First, it emphasizes long-horizon tasks with cross-application interactions: MobileWorld requires nearly twice as many task-completion steps on average (27.8 vs. 14.3) and includes far more multi-application tasks (62.2% vs. 9.5%) compared to AndroidWorld. Second, MobileWorld extends beyond standard GUI manipulation by introducing novel task categories, including agent-user interaction and MCP-augmented tasks. To ensure robust evaluation, we provide snapshot-based container environment and precise functional verifications, including backend database inspection and task callback APIs. We further develop a planner-executor agentic framework with extended action spaces to support user interactions and MCP calls. Our results reveal a sharp performance drop compared to AndroidWorld, with the best agentic framework and end-to-end model achieving 51.7% and 20.9% success rates, respectively. Our analysis shows that current models struggle significantly with user interaction and MCP calls, offering a strategic roadmap toward more robust, next-generation mobile intelligence.
COIG-P: A High-Quality and Large-Scale Chinese Preference Dataset for Alignment with Human Values
Apr 07, 2025Aligning large language models (LLMs) with human preferences has achieved remarkable success. However, existing Chinese preference datasets are limited by small scale, narrow domain coverage, and lack of rigorous data validation. Additionally, the reliance on human annotators for instruction and response labeling significantly constrains the scalability of human preference datasets. To address these challenges, we design an LLM-based Chinese preference dataset annotation pipeline with no human intervention. Specifically, we crawled and carefully filtered 92k high-quality Chinese queries and employed 15 mainstream LLMs to generate and score chosen-rejected response pairs. Based on it, we introduce COIG-P (Chinese Open Instruction Generalist - Preference), a high-quality, large-scale Chinese preference dataset, comprises 1,009k Chinese preference pairs spanning 6 diverse domains: Chat, Code, Math, Logic, Novel, and Role. Building upon COIG-P, to reduce the overhead of using LLMs for scoring, we trained a 8B-sized Chinese Reward Model (CRM) and meticulously constructed a Chinese Reward Benchmark (CRBench). Evaluation results based on AlignBench \citep{liu2024alignbenchbenchmarkingchinesealignment} show that that COIG-P significantly outperforms other Chinese preference datasets, and it brings significant performance improvements ranging from 2% to 12% for the Qwen2/2.5 and Infinity-Instruct-3M-0625 model series, respectively. The results on CRBench demonstrate that our CRM has a strong and robust scoring ability. We apply it to filter chosen-rejected response pairs in a test split of COIG-P, and our experiments show that it is comparable to GPT-4o in identifying low-quality samples while maintaining efficiency and cost-effectiveness. Our codes and data are released in https://github.com/multimodal-art-projection/COIG-P.
SuperGPQA: Scaling LLM Evaluation across 285 Graduate Disciplines
Feb 20, 2025Large language models (LLMs) have demonstrated remarkable proficiency in mainstream academic disciplines such as mathematics, physics, and computer science. However, human knowledge encompasses over 200 specialized disciplines, far exceeding the scope of existing benchmarks. The capabilities of LLMs in many of these specialized fields-particularly in light industry, agriculture, and service-oriented disciplines-remain inadequately evaluated. To address this gap, we present SuperGPQA, a comprehensive benchmark that evaluates graduate-level knowledge and reasoning capabilities across 285 disciplines. Our benchmark employs a novel Human-LLM collaborative filtering mechanism to eliminate trivial or ambiguous questions through iterative refinement based on both LLM responses and expert feedback. Our experimental results reveal significant room for improvement in the performance of current state-of-the-art LLMs across diverse knowledge domains (e.g., the reasoning-focused model DeepSeek-R1 achieved the highest accuracy of 61.82% on SuperGPQA), highlighting the considerable gap between current model capabilities and artificial general intelligence. Additionally, we present comprehensive insights from our management of a large-scale annotation process, involving over 80 expert annotators and an interactive Human-LLM collaborative system, offering valuable methodological guidance for future research initiatives of comparable scope.
Yi-Lightning Technical Report
Dec 03, 2024



This technical report presents Yi-Lightning, our latest flagship large language model (LLM). It achieves exceptional performance, ranking 6th overall on Chatbot Arena, with particularly strong results (2nd to 4th place) in specialized categories including Chinese, Math, Coding, and Hard Prompts. Yi-Lightning leverages an enhanced Mixture-of-Experts (MoE) architecture, featuring advanced expert segmentation and routing mechanisms coupled with optimized KV-caching techniques. Our development process encompasses comprehensive pre-training, supervised fine-tuning (SFT), and reinforcement learning from human feedback (RLHF), where we devise deliberate strategies for multi-stage training, synthetic data construction, and reward modeling. Furthermore, we implement RAISE (Responsible AI Safety Engine), a four-component framework to address safety issues across pre-training, post-training, and serving phases. Empowered by our scalable super-computing infrastructure, all these innovations substantially reduce training, deployment and inference costs while maintaining high-performance standards. With further evaluations on public academic benchmarks, Yi-Lightning demonstrates competitive performance against top-tier LLMs, while we observe a notable disparity between traditional, static benchmark results and real-world, dynamic human preferences. This observation prompts a critical reassessment of conventional benchmarks' utility in guiding the development of more intelligent and powerful AI systems for practical applications. Yi-Lightning is now available through our developer platform at https://platform.lingyiwanwu.com.