 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLocal Search for Integer Quadratic Programming
Sep 29, 2024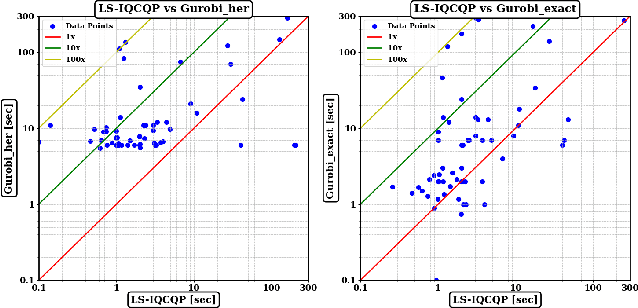
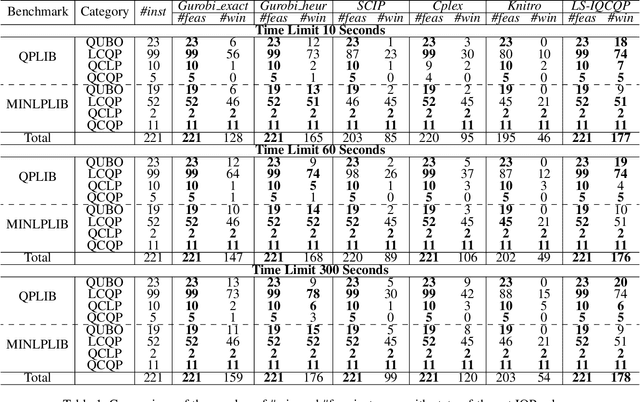

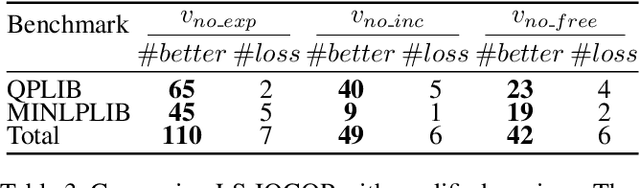
Integer Quadratic Programming (IQP) is an important problem in operations research. Local search is a powerful method for solving hard problems, but the research on local search algorithms for IQP solving is still on its early stage. This paper develops an efficient local search solver for solving general IQP, called LS-IQCQP. We propose four new local search operators for IQP that can handle quadratic terms in the objective function, constraints or both. Furthermore, a two-mode local search algorithm is introduced, utilizing newly designed scoring functions to enhance the search process. Experiments are conducted on standard IQP benchmarks QPLIB and MINLPLIB, comparing LS-IQCQP with several state-of-the-art IQP solvers. Experimental results demonstrate that LS-IQCQP is competitive with the most powerful commercial solver Gurobi and outperforms other state-of-the-art solvers. Moreover, LS-IQCQP has established 6 new records for QPLIB and MINLPLIB open instances.
ParLS-PBO: A Parallel Local Search Solver for Pseudo Boolean Optimization
Jul 31, 2024As a broadly applied technique in numerous optimization problems, recently, local search has been employed to solve Pseudo-Boolean Optimization (PBO) problem. A representative local search solver for PBO is LSPBO. In this paper, firstly, we improve LSPBO by a dynamic scoring mechanism, which dynamically strikes a balance between score on hard constraints and score on the objective function. Moreover, on top of this improved LSPBO , we develop the first parallel local search PBO solver. The main idea is to share good solutions among different threads to guide the search, by maintaining a pool of feasible solutions. For evaluating solutions when updating the pool, we propose a function that considers both the solution quality and the diversity of the pool. Furthermore, we calculate the polarity density in the pool to enhance the scoring function of local search. Our empirical experiments show clear benefits of the proposed parallel approach, making it competitive with the parallel version of the famous commercial solver Gurobi.
Dynamic neural network with memristive CIM and CAM for 2D and 3D vision
Jul 12, 2024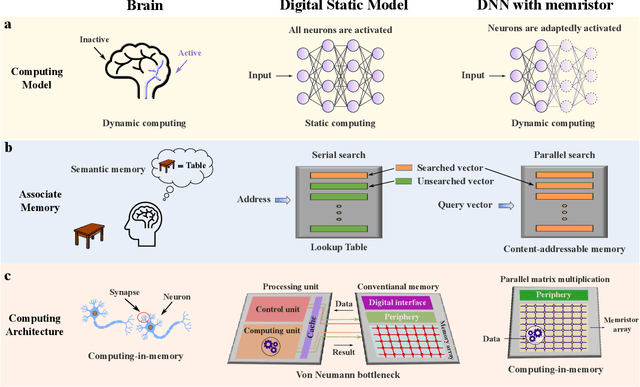
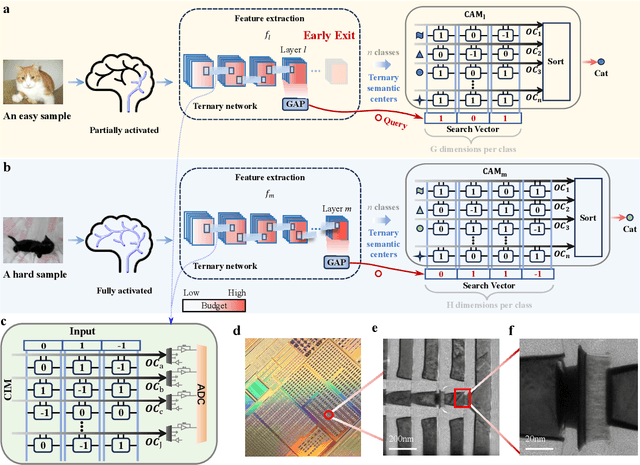
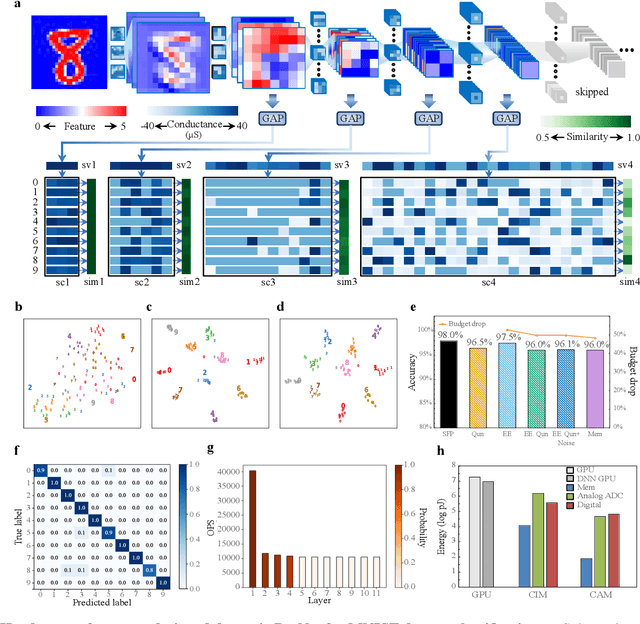
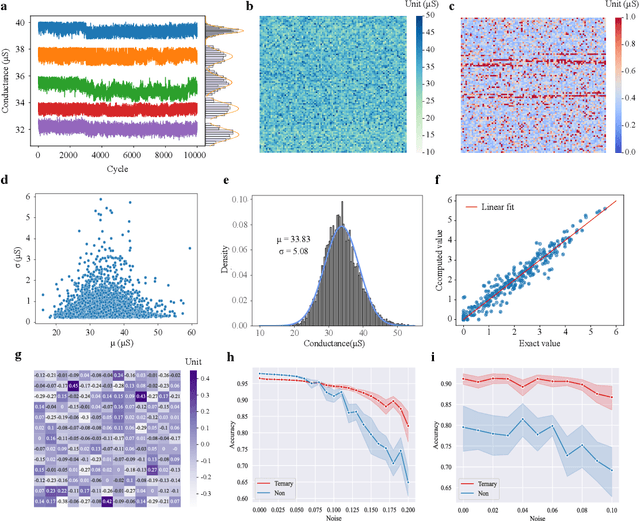
The brain is dynamic, associative and efficient. It reconfigures by associating the inputs with past experiences, with fused memory and processing. In contrast, AI models are static, unable to associate inputs with past experiences, and run on digital computers with physically separated memory and processing. We propose a hardware-software co-design, a semantic memory-based dynamic neural network (DNN) using memristor. The network associates incoming data with the past experience stored as semantic vectors. The network and the semantic memory are physically implemented on noise-robust ternary memristor-based Computing-In-Memory (CIM) and Content-Addressable Memory (CAM) circuits, respectively. We validate our co-designs, using a 40nm memristor macro, on ResNet and PointNet++ for classifying images and 3D points from the MNIST and ModelNet datasets, which not only achieves accuracy on par with software but also a 48.1% and 15.9% reduction in computational budget. Moreover, it delivers a 77.6% and 93.3% reduction in energy consumption.
Infrared Polarization Imaging-based Non-destructive Thermography Inspection
May 06, 2024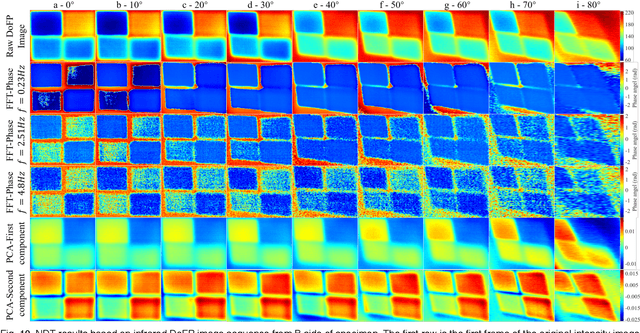
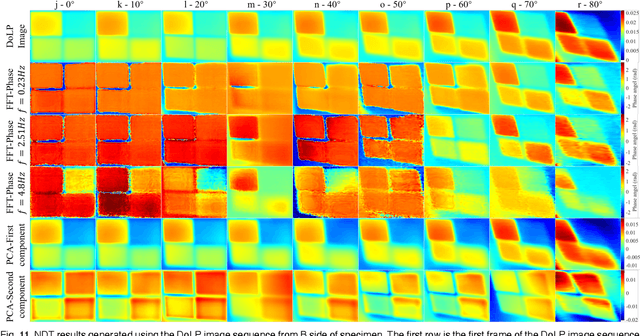
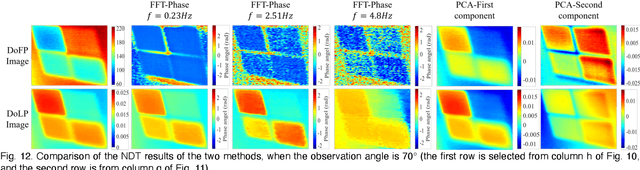
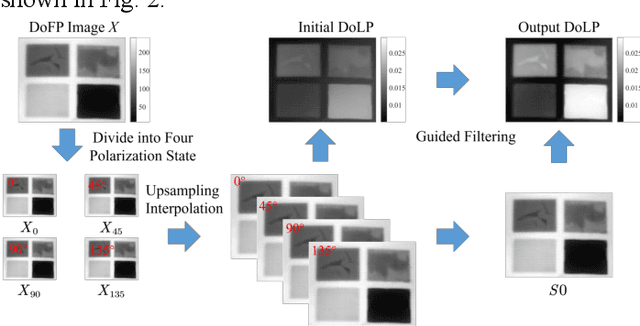
Infrared pulse thermography non-destructive testing (NDT) method is developed based on the difference in the infrared radiation intensity emitted by defective and non-defective areas of an object. However, when the radiation intensity of the defective target is similar to that of the non-defective area of the object, the detection results are poor. To address this issue, this study investigated the polarization characteristics of the infrared radiation of different materials. Simulation results showed that the degree of infrared polarization of the object surface changed regularly with changes in thermal environment radiation. An infrared polarization imaging-based NDT method was proposed and demonstrated using specimens with four different simulated defective areas, which were designed and fabricated using four different materials. The experimental results were consistent with the simulation results, thereby proving the effectiveness of the proposed method. Compared with the infrared-radiation-intensity-based NDT method, the proposed method improved the image detail presentation and detection accuracy.
PPM : A Pre-trained Plug-in Model for Click-through Rate Prediction
Mar 15, 2024



Click-through rate (CTR) prediction is a core task in recommender systems. Existing methods (IDRec for short) rely on unique identities to represent distinct users and items that have prevailed for decades. On one hand, IDRec often faces significant performance degradation on cold-start problem; on the other hand, IDRec cannot use longer training data due to constraints imposed by iteration efficiency. Most prior studies alleviate the above problems by introducing pre-trained knowledge(e.g. pre-trained user model or multi-modal embeddings). However, the explosive growth of online latency can be attributed to the huge parameters in the pre-trained model. Therefore, most of them cannot employ the unified model of end-to-end training with IDRec in industrial recommender systems, thus limiting the potential of the pre-trained model. To this end, we propose a $\textbf{P}$re-trained $\textbf{P}$lug-in CTR $\textbf{M}$odel, namely PPM. PPM employs multi-modal features as input and utilizes large-scale data for pre-training. Then, PPM is plugged in IDRec model to enhance unified model's performance and iteration efficiency. Upon incorporating IDRec model, certain intermediate results within the network are cached, with only a subset of the parameters participating in training and serving. Hence, our approach can successfully deploy an end-to-end model without causing huge latency increases. Comprehensive offline experiments and online A/B testing at JD E-commerce demonstrate the efficiency and effectiveness of PPM.
Stacking Factorizing Partitioned Expressions in Hybrid Bayesian Network Models
Feb 23, 2024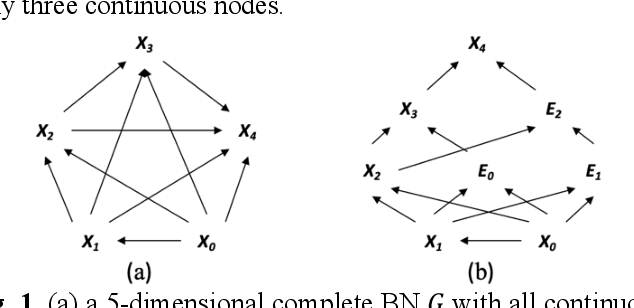
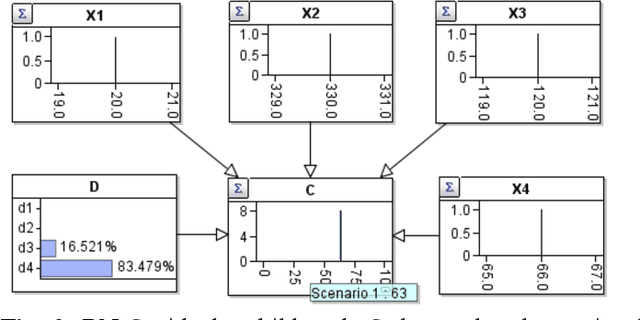
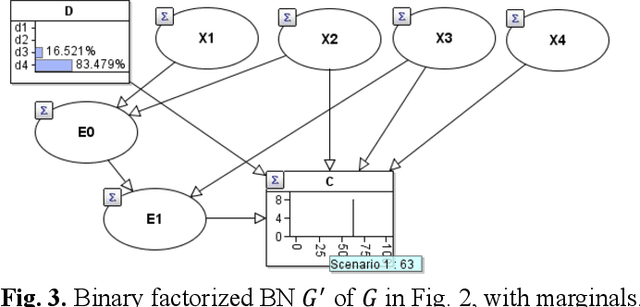
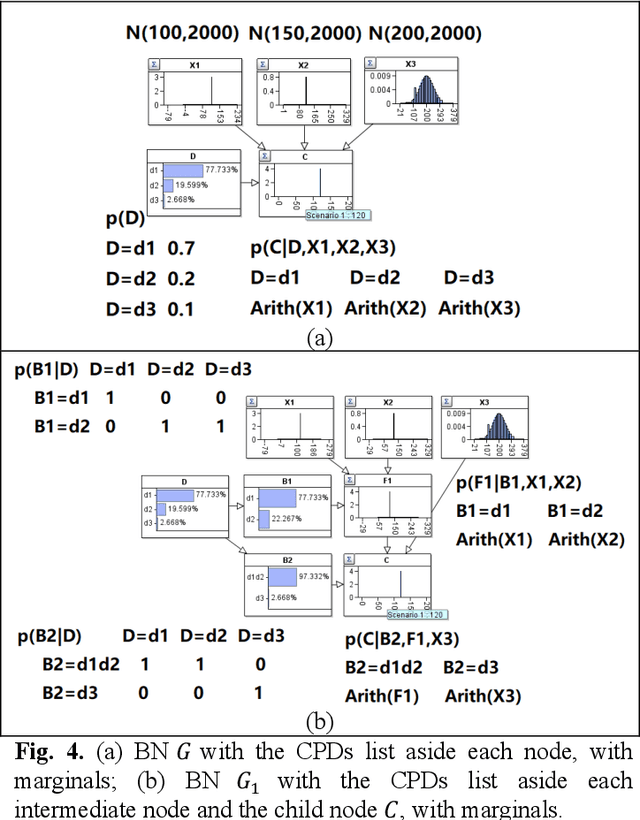
Hybrid Bayesian networks (HBN) contain complex conditional probabilistic distributions (CPD) specified as partitioned expressions over discrete and continuous variables. The size of these CPDs grows exponentially with the number of parent nodes when using discrete inference, resulting in significant inefficiency. Normally, an effective way to reduce the CPD size is to use a binary factorization (BF) algorithm to decompose the statistical or arithmetic functions in the CPD by factorizing the number of connected parent nodes to sets of size two. However, the BF algorithm was not designed to handle partitioned expressions. Hence, we propose a new algorithm called stacking factorization (SF) to decompose the partitioned expressions. The SF algorithm creates intermediate nodes to incrementally reconstruct the densities in the original partitioned expression, allowing no more than two continuous parent nodes to be connected to each child node in the resulting HBN. SF can be either used independently or combined with the BF algorithm. We show that the SF+BF algorithm significantly reduces the CPD size and contributes to lowering the tree-width of a model, thus improving efficiency.
Darwin3: A large-scale neuromorphic chip with a Novel ISA and On-Chip Learning
Dec 29, 2023
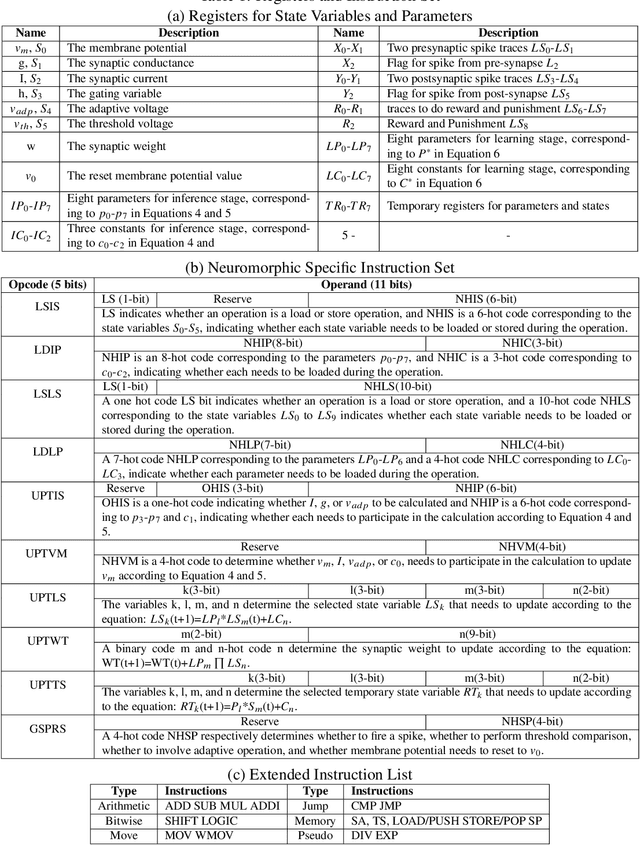
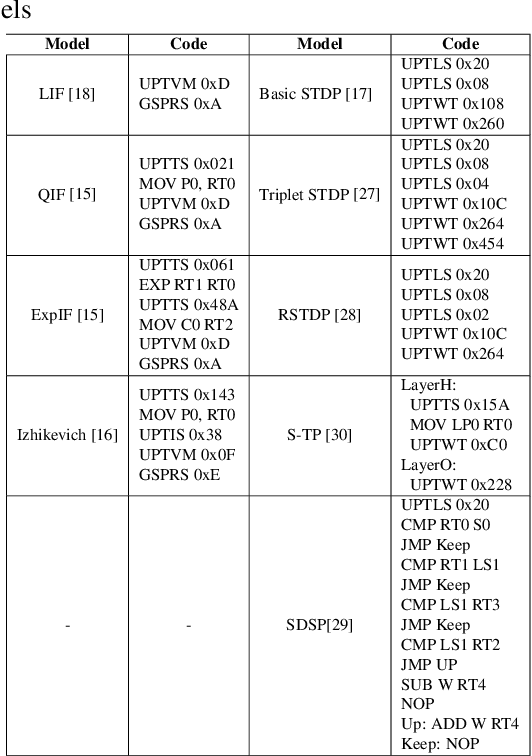
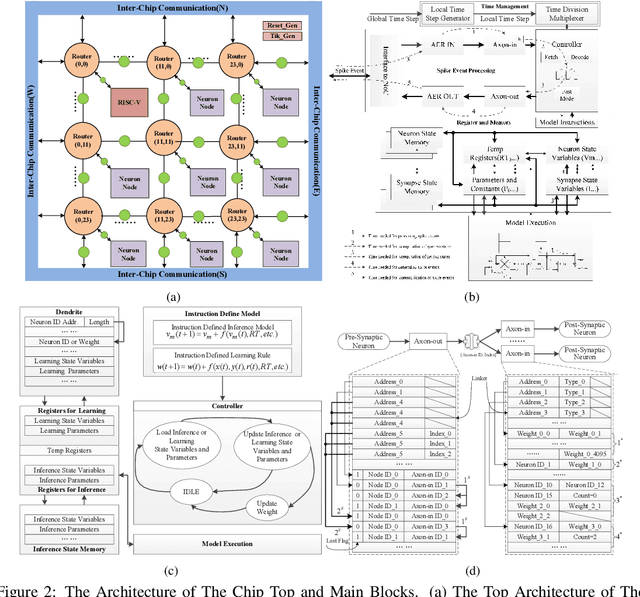
Spiking Neural Networks (SNNs) are gaining increasing attention for their biological plausibility and potential for improved computational efficiency. To match the high spatial-temporal dynamics in SNNs, neuromorphic chips are highly desired to execute SNNs in hardware-based neuron and synapse circuits directly. This paper presents a large-scale neuromorphic chip named Darwin3 with a novel instruction set architecture(ISA), which comprises 10 primary instructions and a few extended instructions. It supports flexible neuron model programming and local learning rule designs. The Darwin3 chip architecture is designed in a mesh of computing nodes with an innovative routing algorithm. We used a compression mechanism to represent synaptic connections, significantly reducing memory usage. The Darwin3 chip supports up to 2.35 million neurons, making it the largest of its kind in neuron scale. The experimental results showed that code density was improved up to 28.3x in Darwin3, and neuron core fan-in and fan-out were improved up to 4096x and 3072x by connection compression compared to the physical memory depth. Our Darwin3 chip also provided memory saving between 6.8X and 200.8X when mapping convolutional spiking neural networks (CSNN) onto the chip, demonstrating state-of-the-art performance in accuracy and latency compared to other neuromorphic chips.
Random resistive memory-based deep extreme point learning machine for unified visual processing
Dec 14, 2023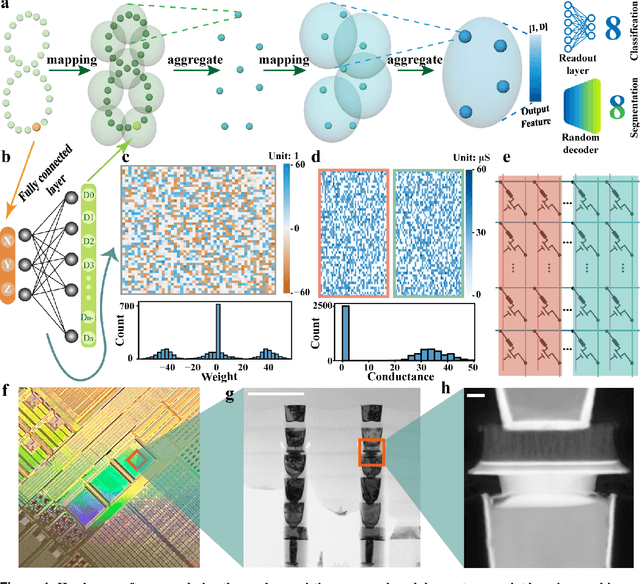
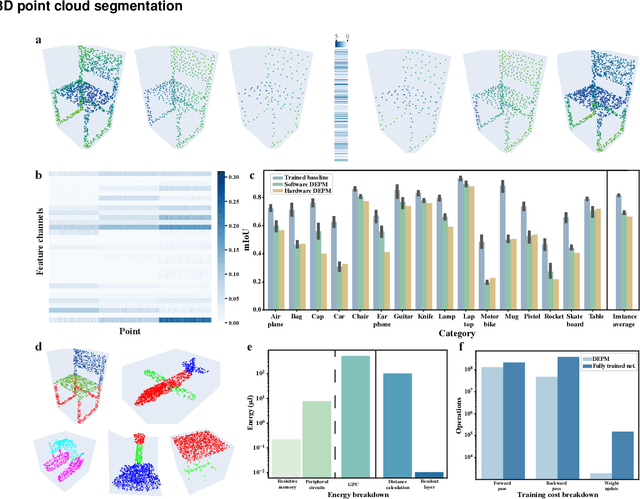
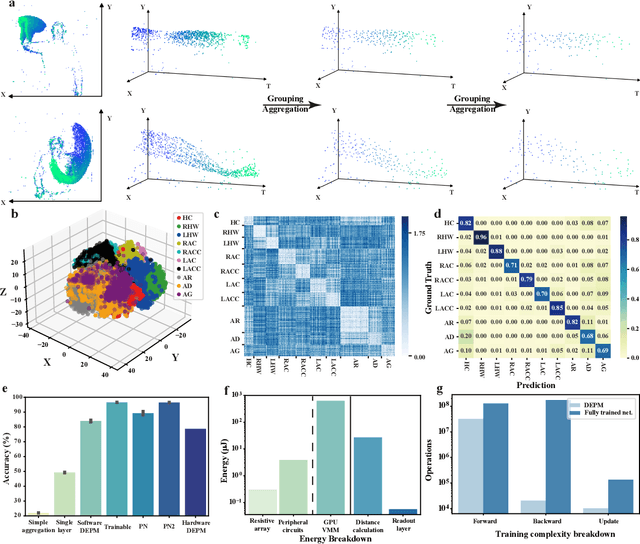
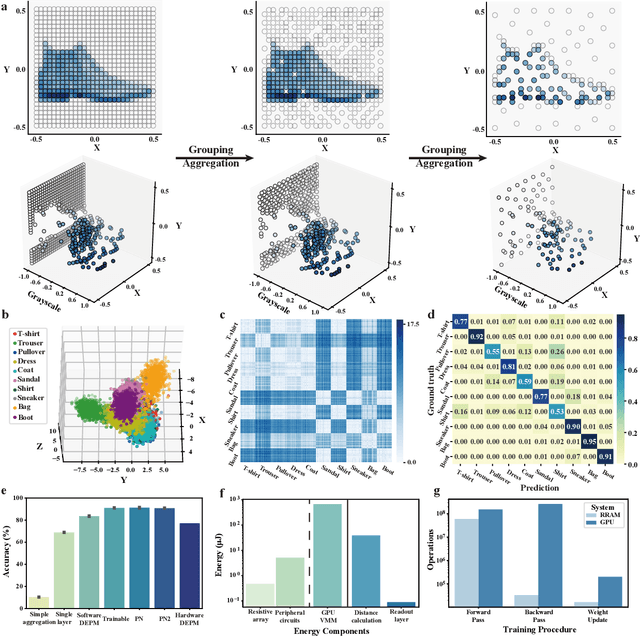
Visual sensors, including 3D LiDAR, neuromorphic DVS sensors, and conventional frame cameras, are increasingly integrated into edge-side intelligent machines. Realizing intensive multi-sensory data analysis directly on edge intelligent machines is crucial for numerous emerging edge applications, such as augmented and virtual reality and unmanned aerial vehicles, which necessitates unified data representation, unprecedented hardware energy efficiency and rapid model training. However, multi-sensory data are intrinsically heterogeneous, causing significant complexity in the system development for edge-side intelligent machines. In addition, the performance of conventional digital hardware is limited by the physically separated processing and memory units, known as the von Neumann bottleneck, and the physical limit of transistor scaling, which contributes to the slowdown of Moore's law. These limitations are further intensified by the tedious training of models with ever-increasing sizes. We propose a novel hardware-software co-design, random resistive memory-based deep extreme point learning machine (DEPLM), that offers efficient unified point set analysis. We show the system's versatility across various data modalities and two different learning tasks. Compared to a conventional digital hardware-based system, our co-design system achieves huge energy efficiency improvements and training cost reduction when compared to conventional systems. Our random resistive memory-based deep extreme point learning machine may pave the way for energy-efficient and training-friendly edge AI across various data modalities and tasks.
Pruning random resistive memory for optimizing analogue AI
Nov 13, 2023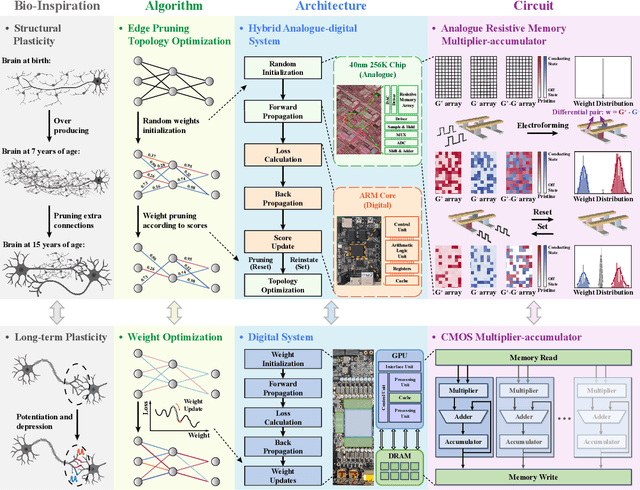
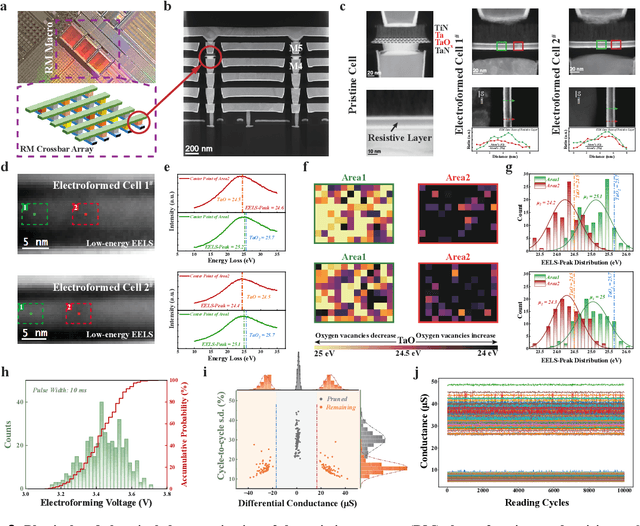
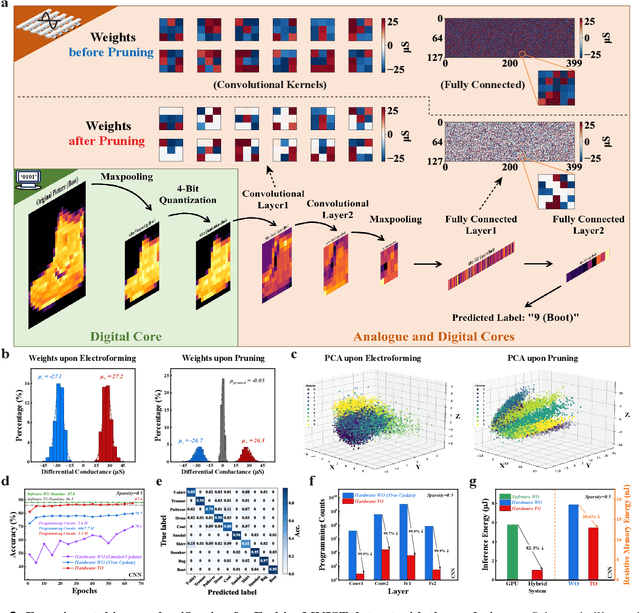
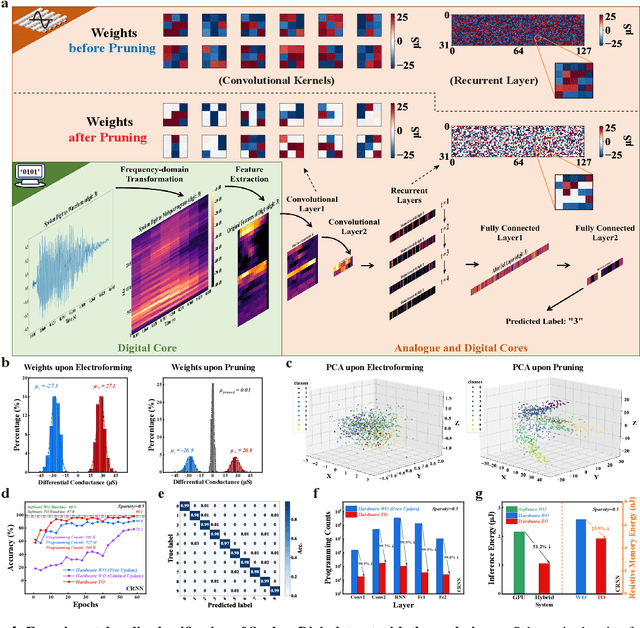
The rapid advancement of artificial intelligence (AI) has been marked by the large language models exhibiting human-like intelligence. However, these models also present unprecedented challenges to energy consumption and environmental sustainability. One promising solution is to revisit analogue computing, a technique that predates digital computing and exploits emerging analogue electronic devices, such as resistive memory, which features in-memory computing, high scalability, and nonvolatility. However, analogue computing still faces the same challenges as before: programming nonidealities and expensive programming due to the underlying devices physics. Here, we report a universal solution, software-hardware co-design using structural plasticity-inspired edge pruning to optimize the topology of a randomly weighted analogue resistive memory neural network. Software-wise, the topology of a randomly weighted neural network is optimized by pruning connections rather than precisely tuning resistive memory weights. Hardware-wise, we reveal the physical origin of the programming stochasticity using transmission electron microscopy, which is leveraged for large-scale and low-cost implementation of an overparameterized random neural network containing high-performance sub-networks. We implemented the co-design on a 40nm 256K resistive memory macro, observing 17.3% and 19.9% accuracy improvements in image and audio classification on FashionMNIST and Spoken digits datasets, as well as 9.8% (2%) improvement in PR (ROC) in image segmentation on DRIVE datasets, respectively. This is accompanied by 82.1%, 51.2%, and 99.8% improvement in energy efficiency thanks to analogue in-memory computing. By embracing the intrinsic stochasticity and in-memory computing, this work may solve the biggest obstacle of analogue computing systems and thus unleash their immense potential for next-generation AI hardware.
Local Search for Integer Linear Programming
May 07, 2023

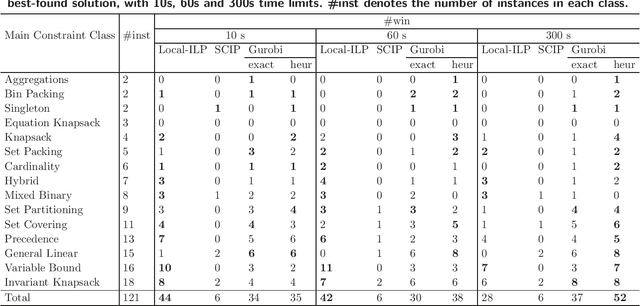
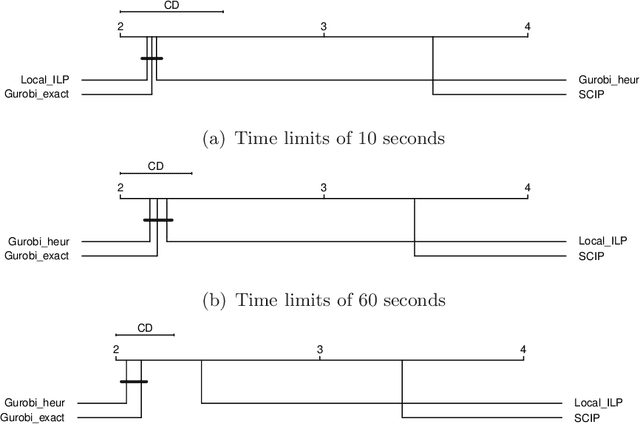
Integer linear programming models a wide range of practical combinatorial optimization problems and has significant impacts in industry and management sectors. This work develops the first standalone local search solver for general integer linear programming validated on a large heterogeneous problem dataset. We propose a local search framework that switches in three modes, namely Search, Improve, and Restore modes, and design tailored operators adapted to different modes, thus improve the quality of the current solution according to different situations. For the Search and Restore modes, we propose an operator named tight move, which adaptively modifies variables' values trying to make some constraint tight. For the Improve mode, an efficient operator lift move is proposed to improve the quality of the objective function while maintaining feasibility. Putting these together, we develop a local search solver for integer linear programming called Local-ILP. Experiments conducted on the MIPLIB dataset show the effectiveness of our solver in solving large-scale hard integer linear programming problems within a reasonably short time. Local-ILP is competitive and complementary to the state-of-the-art commercial solver Gurobi and significantly outperforms the state-of-the-art non-commercial solver SCIP. Moreover, our solver establishes new records for 6 MIPLIB open instances.