 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeYoutu-LLM: Unlocking the Native Agentic Potential for Lightweight Large Language Models
Dec 31, 2025We introduce Youtu-LLM, a lightweight yet powerful language model that harmonizes high computational efficiency with native agentic intelligence. Unlike typical small models that rely on distillation, Youtu-LLM (1.96B) is pre-trained from scratch to systematically cultivate reasoning and planning capabilities. The key technical advancements are as follows: (1) Compact Architecture with Long-Context Support: Built on a dense Multi-Latent Attention (MLA) architecture with a novel STEM-oriented vocabulary, Youtu-LLM supports a 128k context window. This design enables robust long-context reasoning and state tracking within a minimal memory footprint, making it ideal for long-horizon agent and reasoning tasks. (2) Principled "Commonsense-STEM-Agent" Curriculum: We curated a massive corpus of approximately 11T tokens and implemented a multi-stage training strategy. By progressively shifting the pre-training data distribution from general commonsense to complex STEM and agentic tasks, we ensure the model acquires deep cognitive abilities rather than superficial alignment. (3) Scalable Agentic Mid-training: Specifically for the agentic mid-training, we employ diverse data construction schemes to synthesize rich and varied trajectories across math, coding, and tool-use domains. This high-quality data enables the model to internalize planning and reflection behaviors effectively. Extensive evaluations show that Youtu-LLM sets a new state-of-the-art for sub-2B LLMs. On general benchmarks, it achieves competitive performance against larger models, while on agent-specific tasks, it significantly surpasses existing SOTA baselines, demonstrating that lightweight models can possess strong intrinsic agentic capabilities.
A-TDOM: Active TDOM via On-the-Fly 3DGS
Sep 16, 2025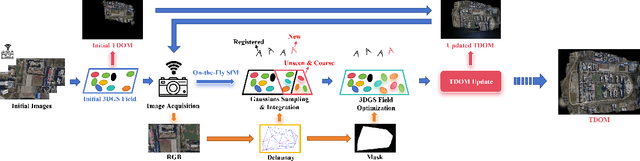
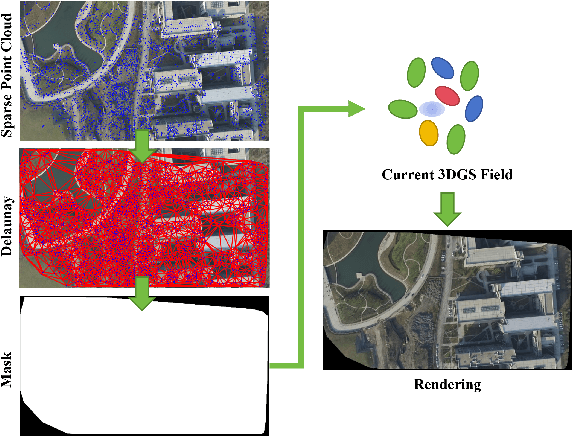
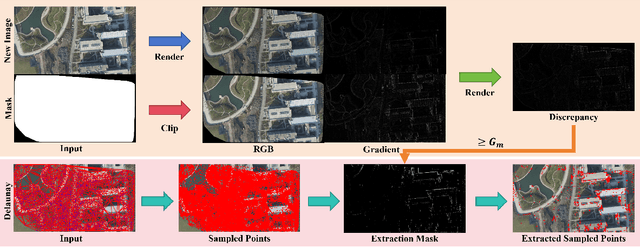
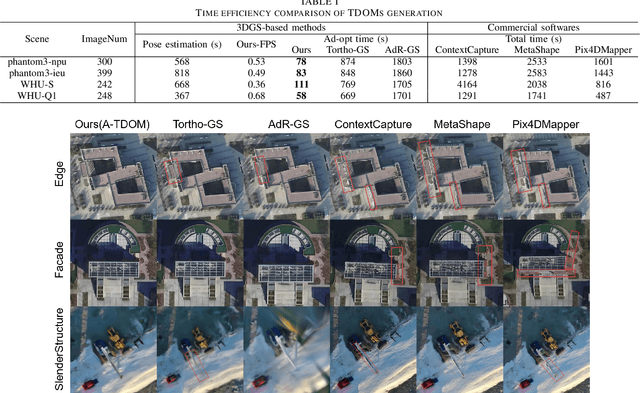
True Digital Orthophoto Map (TDOM) serves as a crucial geospatial product in various fields such as urban management, city planning, land surveying, etc. However, traditional TDOM generation methods generally rely on a complex offline photogrammetric pipeline, resulting in delays that hinder real-time applications. Moreover, the quality of TDOM may degrade due to various challenges, such as inaccurate camera poses or Digital Surface Model (DSM) and scene occlusions. To address these challenges, this work introduces A-TDOM, a near real-time TDOM generation method based on On-the-Fly 3DGS optimization. As each image is acquired, its pose and sparse point cloud are computed via On-the-Fly SfM. Then new Gaussians are integrated and optimized into previously unseen or coarsely reconstructed regions. By integrating with orthogonal splatting, A-TDOM can render just after each update of a new 3DGS field. Initial experiments on multiple benchmarks show that the proposed A-TDOM is capable of actively rendering TDOM in near real-time, with 3DGS optimization for each new image in seconds while maintaining acceptable rendering quality and TDOM geometric accuracy.
Youtu-GraphRAG: Vertically Unified Agents for Graph Retrieval-Augmented Complex Reasoning
Aug 27, 2025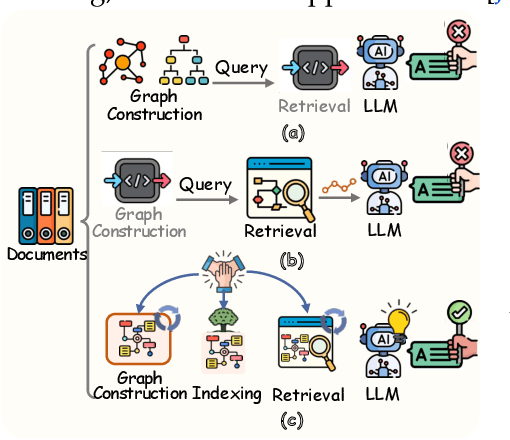
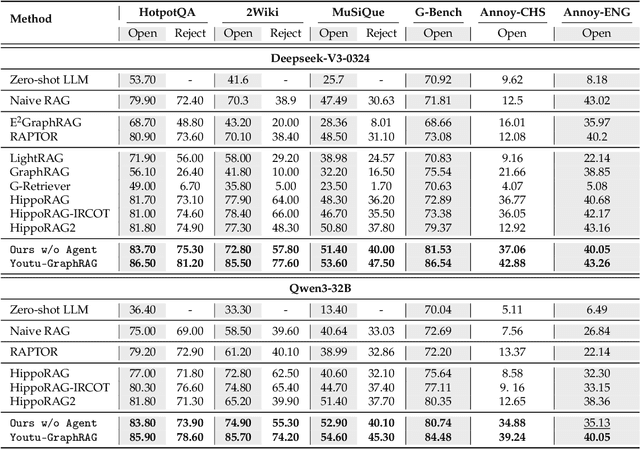

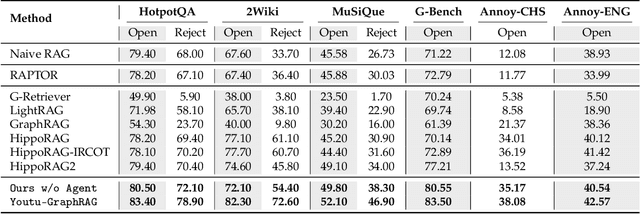
Graph retrieval-augmented generation (GraphRAG) has effectively enhanced large language models in complex reasoning by organizing fragmented knowledge into explicitly structured graphs. Prior efforts have been made to improve either graph construction or graph retrieval in isolation, yielding suboptimal performance, especially when domain shifts occur. In this paper, we propose a vertically unified agentic paradigm, Youtu-GraphRAG, to jointly connect the entire framework as an intricate integration. Specifically, (i) a seed graph schema is introduced to bound the automatic extraction agent with targeted entity types, relations and attribute types, also continuously expanded for scalability over unseen domains; (ii) To obtain higher-level knowledge upon the schema, we develop novel dually-perceived community detection, fusing structural topology with subgraph semantics for comprehensive knowledge organization. This naturally yields a hierarchical knowledge tree that supports both top-down filtering and bottom-up reasoning with community summaries; (iii) An agentic retriever is designed to interpret the same graph schema to transform complex queries into tractable and parallel sub-queries. It iteratively performs reflection for more advanced reasoning; (iv) To alleviate the knowledge leaking problem in pre-trained LLM, we propose a tailored anonymous dataset and a novel 'Anonymity Reversion' task that deeply measures the real performance of the GraphRAG frameworks. Extensive experiments across six challenging benchmarks demonstrate the robustness of Youtu-GraphRAG, remarkably moving the Pareto frontier with up to 90.71% saving of token costs and 16.62% higher accuracy over state-of-the-art baselines. The results indicate our adaptability, allowing seamless domain transfer with minimal intervention on schema.
Sequential-NIAH: A Needle-In-A-Haystack Benchmark for Extracting Sequential Needles from Long Contexts
Apr 09, 2025Evaluating the ability of large language models (LLMs) to handle extended contexts is critical, particularly for retrieving information relevant to specific queries embedded within lengthy inputs. We introduce Sequential-NIAH, a benchmark specifically designed to evaluate the capability of LLMs to extract sequential information items (known as needles) from long contexts. The benchmark comprises three types of needle generation pipelines: synthetic, real, and open-domain QA. It includes contexts ranging from 8K to 128K tokens in length, with a dataset of 14,000 samples (2,000 reserved for testing). To facilitate evaluation on this benchmark, we trained a synthetic data-driven evaluation model capable of evaluating answer correctness based on chronological or logical order, achieving an accuracy of 99.49% on synthetic test data. We conducted experiments on six well-known LLMs, revealing that even the best-performing model achieved a maximum accuracy of only 63.15%. Further analysis highlights the growing challenges posed by increasing context lengths and the number of needles, underscoring substantial room for improvement. Additionally, noise robustness experiments validate the reliability of the benchmark, making Sequential-NIAH an important reference for advancing research on long text extraction capabilities of LLMs.
FactGuard: Leveraging Multi-Agent Systems to Generate Answerable and Unanswerable Questions for Enhanced Long-Context LLM Extraction
Apr 08, 2025Extractive reading comprehension systems are designed to locate the correct answer to a question within a given text. However, a persistent challenge lies in ensuring these models maintain high accuracy in answering questions while reliably recognizing unanswerable queries. Despite significant advances in large language models (LLMs) for reading comprehension, this issue remains critical, particularly as the length of supported contexts continues to expand. To address this challenge, we propose an innovative data augmentation methodology grounded in a multi-agent collaborative framework. Unlike traditional methods, such as the costly human annotation process required for datasets like SQuAD 2.0, our method autonomously generates evidence-based question-answer pairs and systematically constructs unanswerable questions. Using this methodology, we developed the FactGuard-Bench dataset, which comprises 25,220 examples of both answerable and unanswerable question scenarios, with context lengths ranging from 8K to 128K. Experimental evaluations conducted on seven popular LLMs reveal that even the most advanced models achieve only 61.79% overall accuracy. Furthermore, we emphasize the importance of a model's ability to reason about unanswerable questions to avoid generating plausible but incorrect answers. By implementing efficient data selection and generation within the multi-agent collaborative framework, our method significantly reduces the traditionally high costs associated with manual annotation and provides valuable insights for the training and optimization of LLMs.
Gaussian On-the-Fly Splatting: A Progressive Framework for Robust Near Real-Time 3DGS Optimization
Mar 17, 20253D Gaussian Splatting (3DGS) achieves high-fidelity rendering with fast real-time performance, but existing methods rely on offline training after full Structure-from-Motion (SfM) processing. In contrast, this work introduces On-the-Fly GS, a progressive framework enabling near real-time 3DGS optimization during image capture. As each image arrives, its pose and sparse points are updated via on-the-fly SfM, and newly optimized Gaussians are immediately integrated into the 3DGS field. We propose a progressive local optimization strategy to prioritize new images and their neighbors by their corresponding overlapping relationship, allowing the new image and its overlapping images to get more training. To further stabilize training across old and new images, an adaptive learning rate schedule balances the iterations and the learning rate. Moreover, to maintain overall quality of the 3DGS field, an efficient global optimization scheme prevents overfitting to the newly added images. Experiments on multiple benchmark datasets show that our On-the-Fly GS reduces training time significantly, optimizing each new image in seconds with minimal rendering loss, offering the first practical step toward rapid, progressive 3DGS reconstruction.
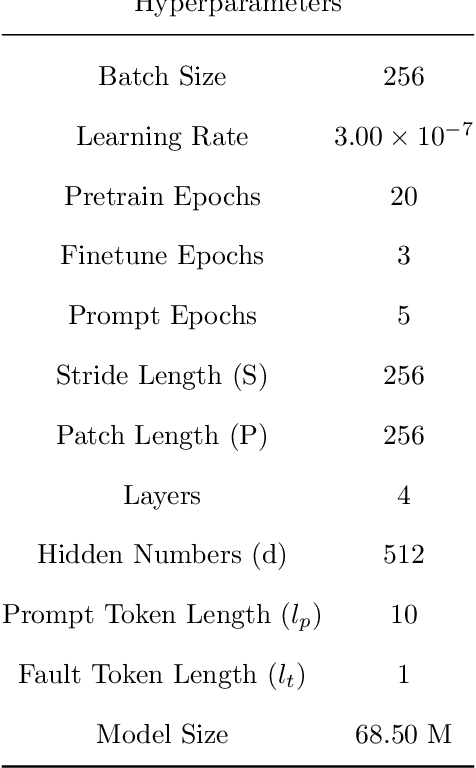
RmGPT: Rotating Machinery Generative Pretrained Model
Sep 26, 2024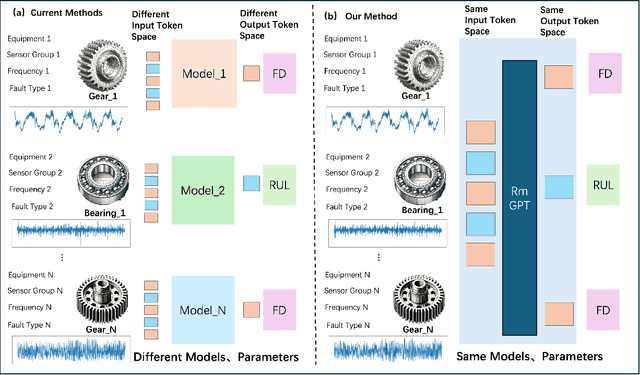
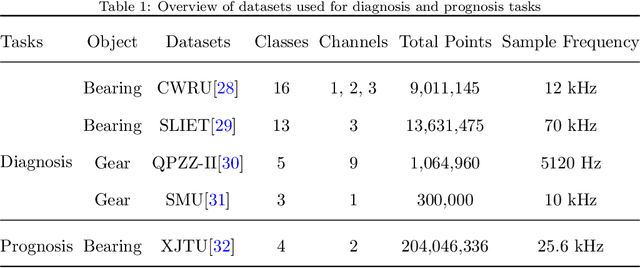
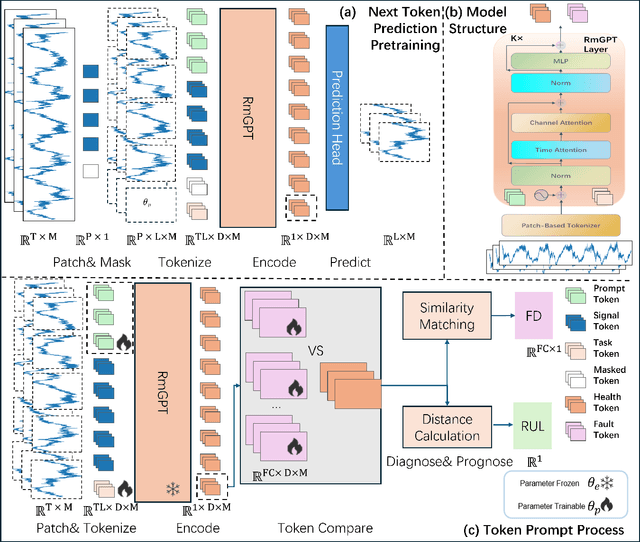
In industry, the reliability of rotating machinery is critical for production efficiency and safety. Current methods of Prognostics and Health Management (PHM) often rely on task-specific models, which face significant challenges in handling diverse datasets with varying signal characteristics, fault modes and operating conditions. Inspired by advancements in generative pretrained models, we propose RmGPT, a unified model for diagnosis and prognosis tasks. RmGPT introduces a novel token-based framework, incorporating Signal Tokens, Prompt Tokens, Time-Frequency Task Tokens and Fault Tokens to handle heterogeneous data within a unified model architecture. We leverage self-supervised learning for robust feature extraction and introduce a next signal token prediction pretraining strategy, alongside efficient prompt learning for task-specific adaptation. Extensive experiments demonstrate that RmGPT significantly outperforms state-of-the-art algorithms, achieving near-perfect accuracy in diagnosis tasks and exceptionally low errors in prognosis tasks. Notably, RmGPT excels in few-shot learning scenarios, achieving 92% accuracy in 16-class one-shot experiments, highlighting its adaptability and robustness. This work establishes RmGPT as a powerful PHM foundation model for rotating machinery, advancing the scalability and generalizability of PHM solutions.
Exploring the potential of collaborative UAV 3D mapping in Kenyan savanna for wildlife research
Sep 24, 2024



UAV-based biodiversity conservation applications have exhibited many data acquisition advantages for researchers. UAV platforms with embedded data processing hardware can support conservation challenges through 3D habitat mapping, surveillance and monitoring solutions. High-quality real-time scene reconstruction as well as real-time UAV localization can optimize the exploration vs exploitation balance of single or collaborative mission. In this work, we explore the potential of two collaborative frameworks - Visual Simultaneous Localization and Mapping (V-SLAM) and Structure-from-Motion (SfM) for 3D mapping purposes and compare results with standard offline approaches.
Topology Optimization of Random Memristors for Input-Aware Dynamic SNN
Jul 26, 2024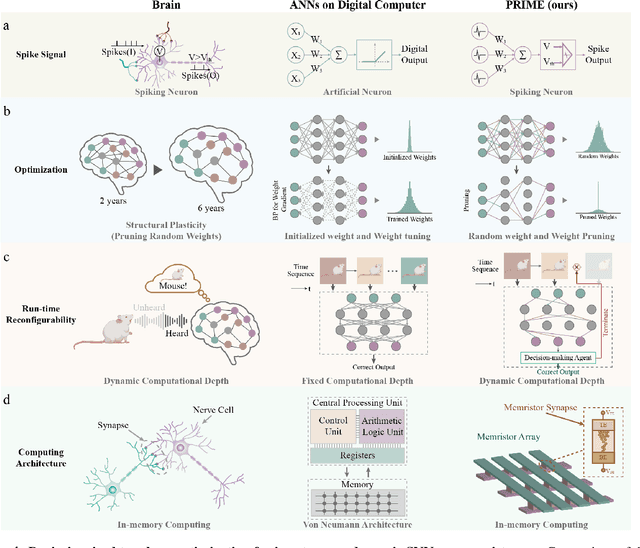
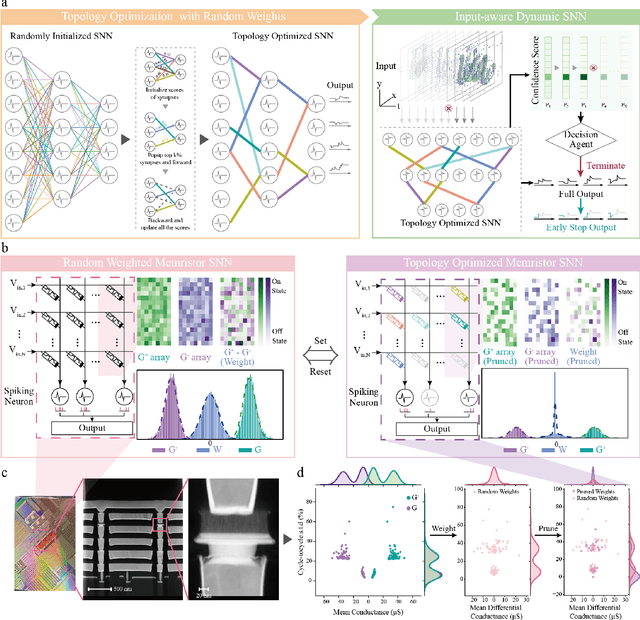
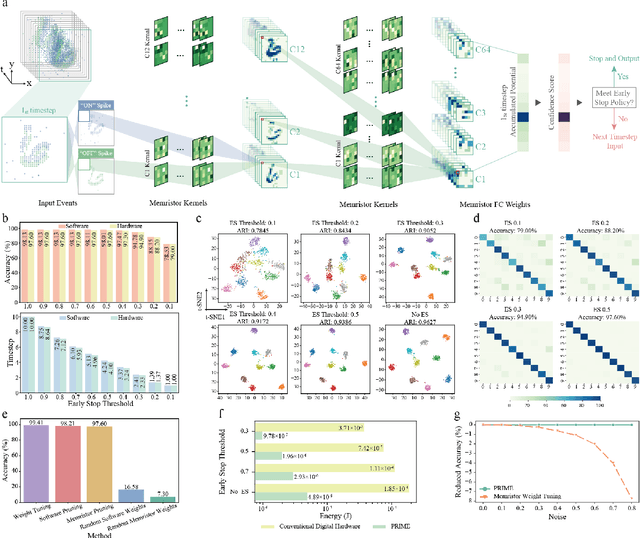
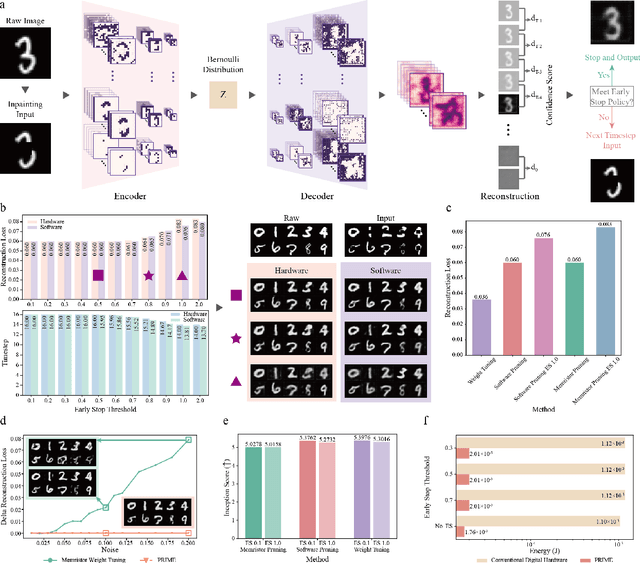
There is unprecedented development in machine learning, exemplified by recent large language models and world simulators, which are artificial neural networks running on digital computers. However, they still cannot parallel human brains in terms of energy efficiency and the streamlined adaptability to inputs of different difficulties, due to differences in signal representation, optimization, run-time reconfigurability, and hardware architecture. To address these fundamental challenges, we introduce pruning optimization for input-aware dynamic memristive spiking neural network (PRIME). Signal representation-wise, PRIME employs leaky integrate-and-fire neurons to emulate the brain's inherent spiking mechanism. Drawing inspiration from the brain's structural plasticity, PRIME optimizes the topology of a random memristive spiking neural network without expensive memristor conductance fine-tuning. For runtime reconfigurability, inspired by the brain's dynamic adjustment of computational depth, PRIME employs an input-aware dynamic early stop policy to minimize latency during inference, thereby boosting energy efficiency without compromising performance. Architecture-wise, PRIME leverages memristive in-memory computing, mirroring the brain and mitigating the von Neumann bottleneck. We validated our system using a 40 nm 256 Kb memristor-based in-memory computing macro on neuromorphic image classification and image inpainting. Our results demonstrate the classification accuracy and Inception Score are comparable to the software baseline, while achieving maximal 62.50-fold improvements in energy efficiency, and maximal 77.0% computational load savings. The system also exhibits robustness against stochastic synaptic noise of analogue memristors. Our software-hardware co-designed model paves the way to future brain-inspired neuromorphic computing with brain-like energy efficiency and adaptivity.
Dynamic neural network with memristive CIM and CAM for 2D and 3D vision
Jul 12, 2024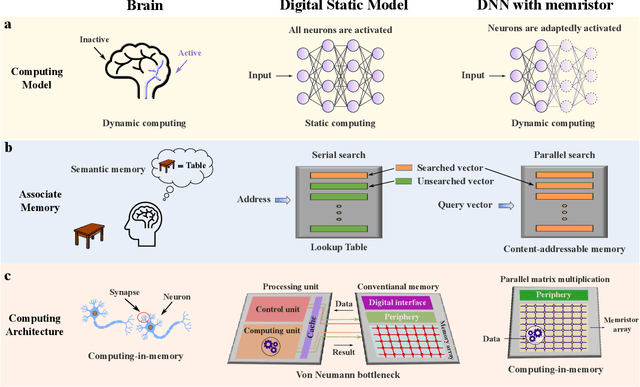
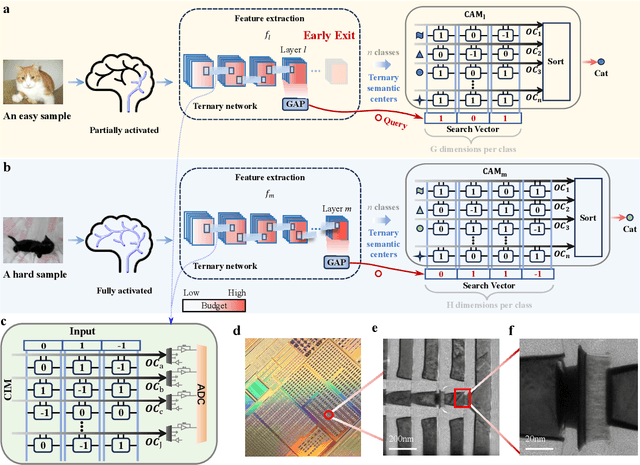
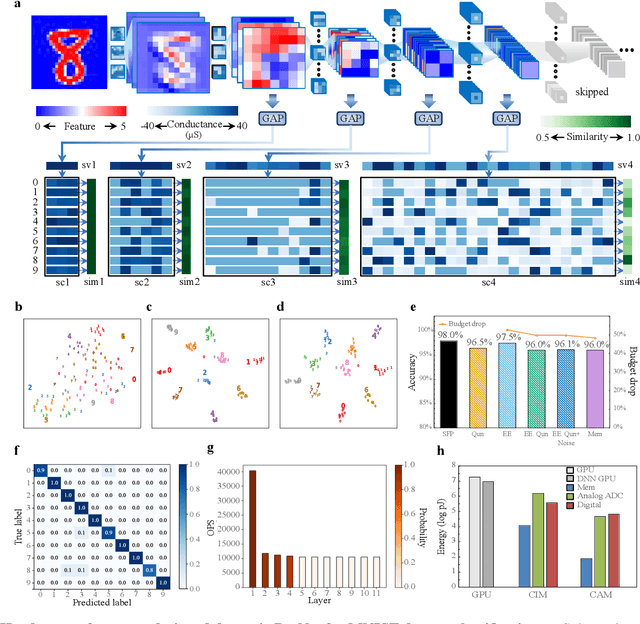
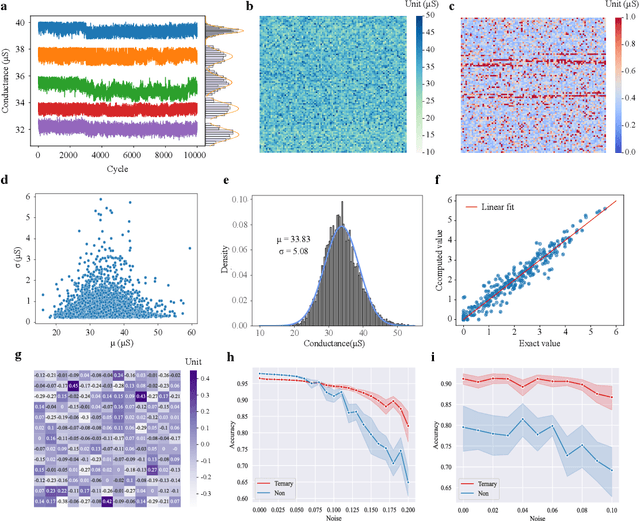
The brain is dynamic, associative and efficient. It reconfigures by associating the inputs with past experiences, with fused memory and processing. In contrast, AI models are static, unable to associate inputs with past experiences, and run on digital computers with physically separated memory and processing. We propose a hardware-software co-design, a semantic memory-based dynamic neural network (DNN) using memristor. The network associates incoming data with the past experience stored as semantic vectors. The network and the semantic memory are physically implemented on noise-robust ternary memristor-based Computing-In-Memory (CIM) and Content-Addressable Memory (CAM) circuits, respectively. We validate our co-designs, using a 40nm memristor macro, on ResNet and PointNet++ for classifying images and 3D points from the MNIST and ModelNet datasets, which not only achieves accuracy on par with software but also a 48.1% and 15.9% reduction in computational budget. Moreover, it delivers a 77.6% and 93.3% reduction in energy consumption.