 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFORESTLLM: Large Language Models Make Random Forest Great on Few-shot Tabular Learning
Jan 16, 2026Tabular data high-stakes critical decision-making in domains such as finance, healthcare, and scientific discovery. Yet, learning effectively from tabular data in few-shot settings, where labeled examples are scarce, remains a fundamental challenge. Traditional tree-based methods often falter in these regimes due to their reliance on statistical purity metrics, which become unstable and prone to overfitting with limited supervision. At the same time, direct applications of large language models (LLMs) often overlook its inherent structure, leading to suboptimal performance. To overcome these limitations, we propose FORESTLLM, a novel framework that unifies the structural inductive biases of decision forests with the semantic reasoning capabilities of LLMs. Crucially, FORESTLLM leverages the LLM only during training, treating it as an offline model designer that encodes rich, contextual knowledge into a lightweight, interpretable forest model, eliminating the need for LLM inference at test time. Our method is two-fold. First, we introduce a semantic splitting criterion in which the LLM evaluates candidate partitions based on their coherence over both labeled and unlabeled data, enabling the induction of more robust and generalizable tree structures under few-shot supervision. Second, we propose a one-time in-context inference mechanism for leaf node stabilization, where the LLM distills the decision path and its supporting examples into a concise, deterministic prediction, replacing noisy empirical estimates with semantically informed outputs. Across a diverse suite of few-shot classification and regression benchmarks, FORESTLLM achieves state-of-the-art performance.
TimeSeriesScientist: A General-Purpose AI Agent for Time Series Analysis
Oct 02, 2025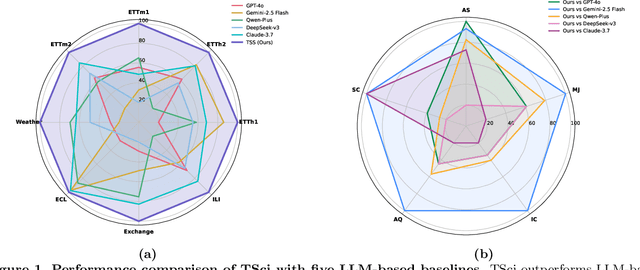
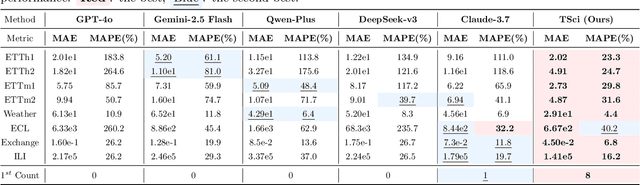
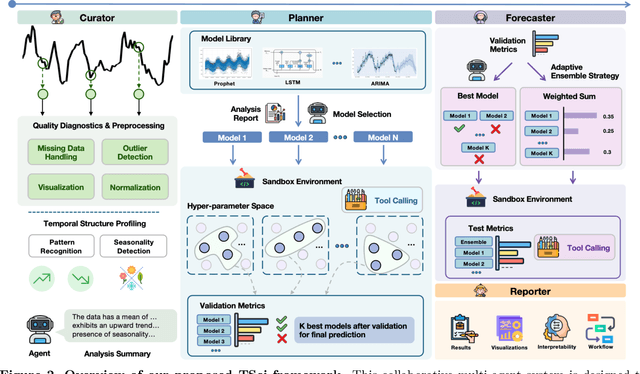
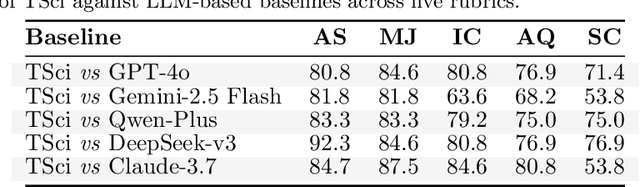
Time series forecasting is central to decision-making in domains as diverse as energy, finance, climate, and public health. In practice, forecasters face thousands of short, noisy series that vary in frequency, quality, and horizon, where the dominant cost lies not in model fitting, but in the labor-intensive preprocessing, validation, and ensembling required to obtain reliable predictions. Prevailing statistical and deep learning models are tailored to specific datasets or domains and generalize poorly. A general, domain-agnostic framework that minimizes human intervention is urgently in demand. In this paper, we introduce TimeSeriesScientist (TSci), the first LLM-driven agentic framework for general time series forecasting. The framework comprises four specialized agents: Curator performs LLM-guided diagnostics augmented by external tools that reason over data statistics to choose targeted preprocessing; Planner narrows the hypothesis space of model choice by leveraging multi-modal diagnostics and self-planning over the input; Forecaster performs model fitting and validation and, based on the results, adaptively selects the best model configuration as well as ensemble strategy to make final predictions; and Reporter synthesizes the whole process into a comprehensive, transparent report. With transparent natural-language rationales and comprehensive reports, TSci transforms the forecasting workflow into a white-box system that is both interpretable and extensible across tasks. Empirical results on eight established benchmarks demonstrate that TSci consistently outperforms both statistical and LLM-based baselines, reducing forecast error by an average of 10.4% and 38.2%, respectively. Moreover, TSci produces a clear and rigorous report that makes the forecasting workflow more transparent and interpretable.
A-TDOM: Active TDOM via On-the-Fly 3DGS
Sep 16, 2025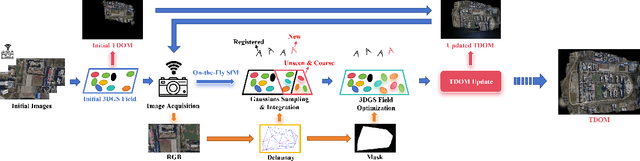
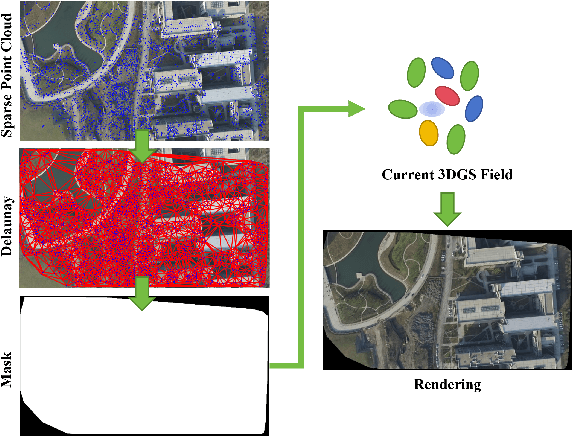
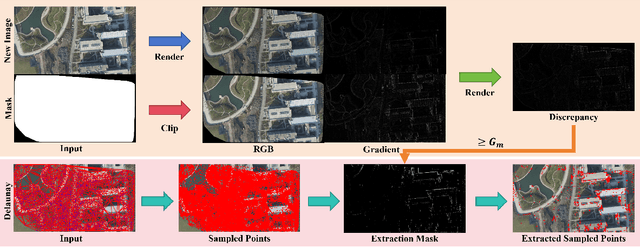
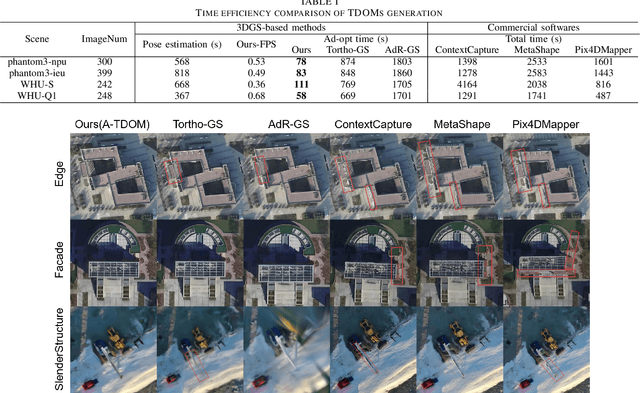
True Digital Orthophoto Map (TDOM) serves as a crucial geospatial product in various fields such as urban management, city planning, land surveying, etc. However, traditional TDOM generation methods generally rely on a complex offline photogrammetric pipeline, resulting in delays that hinder real-time applications. Moreover, the quality of TDOM may degrade due to various challenges, such as inaccurate camera poses or Digital Surface Model (DSM) and scene occlusions. To address these challenges, this work introduces A-TDOM, a near real-time TDOM generation method based on On-the-Fly 3DGS optimization. As each image is acquired, its pose and sparse point cloud are computed via On-the-Fly SfM. Then new Gaussians are integrated and optimized into previously unseen or coarsely reconstructed regions. By integrating with orthogonal splatting, A-TDOM can render just after each update of a new 3DGS field. Initial experiments on multiple benchmarks show that the proposed A-TDOM is capable of actively rendering TDOM in near real-time, with 3DGS optimization for each new image in seconds while maintaining acceptable rendering quality and TDOM geometric accuracy.
PosterGen: Aesthetic-Aware Paper-to-Poster Generation via Multi-Agent LLMs
Aug 24, 2025Multi-agent systems built upon large language models (LLMs) have demonstrated remarkable capabilities in tackling complex compositional tasks. In this work, we apply this paradigm to the paper-to-poster generation problem, a practical yet time-consuming process faced by researchers preparing for conferences. While recent approaches have attempted to automate this task, most neglect core design and aesthetic principles, resulting in posters that require substantial manual refinement. To address these design limitations, we propose PosterGen, a multi-agent framework that mirrors the workflow of professional poster designers. It consists of four collaborative specialized agents: (1) Parser and Curator agents extract content from the paper and organize storyboard; (2) Layout agent maps the content into a coherent spatial layout; (3) Stylist agents apply visual design elements such as color and typography; and (4) Renderer composes the final poster. Together, these agents produce posters that are both semantically grounded and visually appealing. To evaluate design quality, we introduce a vision-language model (VLM)-based rubric that measures layout balance, readability, and aesthetic coherence. Experimental results show that PosterGen consistently matches in content fidelity, and significantly outperforms existing methods in visual designs, generating posters that are presentation-ready with minimal human refinements.
Tokenization Constraints in LLMs: A Study of Symbolic and Arithmetic Reasoning Limits
May 20, 2025Tokenization is the first - and often underappreciated - layer of computation in language models. While Chain-of-Thought (CoT) prompting enables transformer models to approximate recurrent computation by externalizing intermediate steps, we show that the success of such reasoning is fundamentally bounded by the structure of tokenized inputs. This work presents a theoretical and empirical investigation into how tokenization schemes, particularly subword-based methods like byte-pair encoding (BPE), impede symbolic computation by merging or obscuring atomic reasoning units. We introduce the notion of Token Awareness to formalize how poor token granularity disrupts logical alignment and prevents models from generalizing symbolic procedures. Through systematic evaluation on arithmetic and symbolic tasks, we demonstrate that token structure dramatically affect reasoning performance, causing failure even with CoT, while atomically-aligned formats unlock strong generalization, allowing small models (e.g., GPT-4o-mini) to outperform larger systems (e.g., o1) in structured reasoning. Our findings reveal that symbolic reasoning ability in LLMs is not purely architectural, but deeply conditioned on token-level representations.
GS-I$^{3}$: Gaussian Splatting for Surface Reconstruction from Illumination-Inconsistent Images
Mar 18, 2025



Accurate geometric surface reconstruction, providing essential environmental information for navigation and manipulation tasks, is critical for enabling robotic self-exploration and interaction. Recently, 3D Gaussian Splatting (3DGS) has gained significant attention in the field of surface reconstruction due to its impressive geometric quality and computational efficiency. While recent relevant advancements in novel view synthesis under inconsistent illumination using 3DGS have shown promise, the challenge of robust surface reconstruction under such conditions is still being explored. To address this challenge, we propose a method called GS-3I. Specifically, to mitigate 3D Gaussian optimization bias caused by underexposed regions in single-view images, based on Convolutional Neural Network (CNN), a tone mapping correction framework is introduced. Furthermore, inconsistent lighting across multi-view images, resulting from variations in camera settings and complex scene illumination, often leads to geometric constraint mismatches and deviations in the reconstructed surface. To overcome this, we propose a normal compensation mechanism that integrates reference normals extracted from single-view image with normals computed from multi-view observations to effectively constrain geometric inconsistencies. Extensive experimental evaluations demonstrate that GS-3I can achieve robust and accurate surface reconstruction across complex illumination scenarios, highlighting its effectiveness and versatility in this critical challenge. https://github.com/TFwang-9527/GS-3I
Gaussian On-the-Fly Splatting: A Progressive Framework for Robust Near Real-Time 3DGS Optimization
Mar 17, 20253D Gaussian Splatting (3DGS) achieves high-fidelity rendering with fast real-time performance, but existing methods rely on offline training after full Structure-from-Motion (SfM) processing. In contrast, this work introduces On-the-Fly GS, a progressive framework enabling near real-time 3DGS optimization during image capture. As each image arrives, its pose and sparse points are updated via on-the-fly SfM, and newly optimized Gaussians are immediately integrated into the 3DGS field. We propose a progressive local optimization strategy to prioritize new images and their neighbors by their corresponding overlapping relationship, allowing the new image and its overlapping images to get more training. To further stabilize training across old and new images, an adaptive learning rate schedule balances the iterations and the learning rate. Moreover, to maintain overall quality of the 3DGS field, an efficient global optimization scheme prevents overfitting to the newly added images. Experiments on multiple benchmark datasets show that our On-the-Fly GS reduces training time significantly, optimizing each new image in seconds with minimal rendering loss, offering the first practical step toward rapid, progressive 3DGS reconstruction.
GS-3I: Gaussian Splatting for Surface Reconstruction from Illumination-Inconsistent Images
Mar 16, 2025Accurate geometric surface reconstruction, providing essential environmental information for navigation and manipulation tasks, is critical for enabling robotic self-exploration and interaction. Recently, 3D Gaussian Splatting (3DGS) has gained significant attention in the field of surface reconstruction due to its impressive geometric quality and computational efficiency. While recent relevant advancements in novel view synthesis under inconsistent illumination using 3DGS have shown promise, the challenge of robust surface reconstruction under such conditions is still being explored. To address this challenge, we propose a method called GS-3I. Specifically, to mitigate 3D Gaussian optimization bias caused by underexposed regions in single-view images, based on Convolutional Neural Network (CNN), a tone mapping correction framework is introduced. Furthermore, inconsistent lighting across multi-view images, resulting from variations in camera settings and complex scene illumination, often leads to geometric constraint mismatches and deviations in the reconstructed surface. To overcome this, we propose a normal compensation mechanism that integrates reference normals extracted from single-view image with normals computed from multi-view observations to effectively constrain geometric inconsistencies. Extensive experimental evaluations demonstrate that GS-3I can achieve robust and accurate surface reconstruction across complex illumination scenarios, highlighting its effectiveness and versatility in this critical challenge. https://github.com/TFwang-9527/GS-3I
PG-SAG: Parallel Gaussian Splatting for Fine-Grained Large-Scale Urban Buildings Reconstruction via Semantic-Aware Grouping
Jan 03, 2025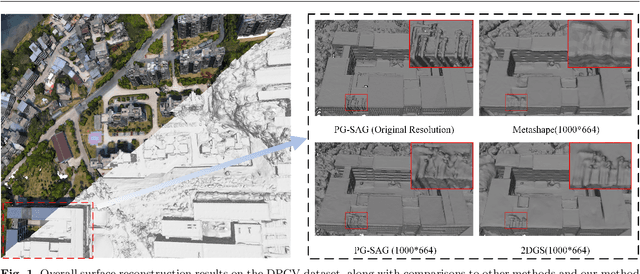
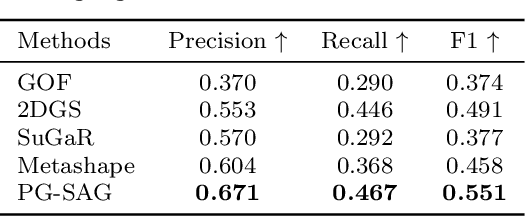


3D Gaussian Splatting (3DGS) has emerged as a transformative method in the field of real-time novel synthesis. Based on 3DGS, recent advancements cope with large-scale scenes via spatial-based partition strategy to reduce video memory and optimization time costs. In this work, we introduce a parallel Gaussian splatting method, termed PG-SAG, which fully exploits semantic cues for both partitioning and Gaussian kernel optimization, enabling fine-grained building surface reconstruction of large-scale urban areas without downsampling the original image resolution. First, the Cross-modal model - Language Segment Anything is leveraged to segment building masks. Then, the segmented building regions is grouped into sub-regions according to the visibility check across registered images. The Gaussian kernels for these sub-regions are optimized in parallel with masked pixels. In addition, the normal loss is re-formulated for the detected edges of masks to alleviate the ambiguities in normal vectors on edges. Finally, to improve the optimization of 3D Gaussians, we introduce a gradient-constrained balance-load loss that accounts for the complexity of the corresponding scenes, effectively minimizing the thread waiting time in the pixel-parallel rendering stage as well as the reconstruction lost. Extensive experiments are tested on various urban datasets, the results demonstrated the superior performance of our PG-SAG on building surface reconstruction, compared to several state-of-the-art 3DGS-based methods. Project Web:https://github.com/TFWang-9527/PG-SAG.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023

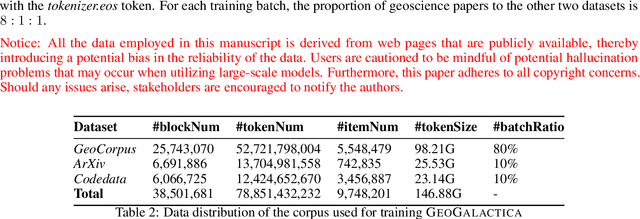
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.