 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparrow: Text-Anchored Window Attention with Visual-Semantic Glimpsing for Speculative Decoding in Video LLMs
Feb 17, 2026Although speculative decoding is widely used to accelerate Vision-Language Models (VLMs) inference, it faces severe performance collapse when applied to Video Large Language Models (Vid-LLMs). The draft model typically falls into the trap of attention dilution and negative visual gain due to key-value cache explosion and context window mismatches. We observe a visual semantic internalization phenomenon in Vid-LLMs, indicating that critical visual semantics are implicitly encoded into text hidden states during deep-layer interactions, which renders raw visual inputs structurally redundant during deep inference. To address this, we propose the Sparrow framework, which first utilizes visually-aware text-anchored window attention via hidden state reuse to fully offload visual computation to the target model, and leverages intermediate-layer visual state bridging to train the draft model with semantic-rich intermediate states, thereby filtering out low-level visual noise. Additionally, a multi-token prediction strategy is introduced to bridge the training-inference distribution shift. Experiments show that Sparrow achieves an average speedup of 2.82x even with 25k visual tokens, effectively resolving the performance degradation in long sequences and offering a practical solution for real-time long video tasks.
Nightjar: Dynamic Adaptive Speculative Decoding for Large Language Models Serving
Dec 27, 2025Speculative decoding (SD) accelerates LLM inference by verifying draft tokens in parallel. However, this method presents a critical trade-off: it improves throughput in low-load, memory-bound systems but degrades performance in high-load, compute-bound environments due to verification overhead. Current SD implementations use a fixed speculative length, failing to adapt to dynamic request rates and creating a significant performance bottleneck in real-world serving scenarios. To overcome this, we propose Nightjar, a novel learning-based algorithm for adaptive speculative inference that adjusts to request load by dynamically selecting the optimal speculative length for different batch sizes and even disabling speculative decoding when it provides no benefit. Experiments show that Nightjar achieves up to 14.8% higher throughput and 20.2% lower latency compared to standard speculative decoding, demonstrating robust efficiency for real-time serving.
Step-DeepResearch Technical Report
Dec 24, 2025As LLMs shift toward autonomous agents, Deep Research has emerged as a pivotal metric. However, existing academic benchmarks like BrowseComp often fail to meet real-world demands for open-ended research, which requires robust skills in intent recognition, long-horizon decision-making, and cross-source verification. To address this, we introduce Step-DeepResearch, a cost-effective, end-to-end agent. We propose a Data Synthesis Strategy Based on Atomic Capabilities to reinforce planning and report writing, combined with a progressive training path from agentic mid-training to SFT and RL. Enhanced by a Checklist-style Judger, this approach significantly improves robustness. Furthermore, to bridge the evaluation gap in the Chinese domain, we establish ADR-Bench for realistic deep research scenarios. Experimental results show that Step-DeepResearch (32B) scores 61.4% on Scale AI Research Rubrics. On ADR-Bench, it significantly outperforms comparable models and rivals SOTA closed-source models like OpenAI and Gemini DeepResearch. These findings prove that refined training enables medium-sized models to achieve expert-level capabilities at industry-leading cost-efficiency.
GS-I$^{3}$: Gaussian Splatting for Surface Reconstruction from Illumination-Inconsistent Images
Mar 18, 2025



Accurate geometric surface reconstruction, providing essential environmental information for navigation and manipulation tasks, is critical for enabling robotic self-exploration and interaction. Recently, 3D Gaussian Splatting (3DGS) has gained significant attention in the field of surface reconstruction due to its impressive geometric quality and computational efficiency. While recent relevant advancements in novel view synthesis under inconsistent illumination using 3DGS have shown promise, the challenge of robust surface reconstruction under such conditions is still being explored. To address this challenge, we propose a method called GS-3I. Specifically, to mitigate 3D Gaussian optimization bias caused by underexposed regions in single-view images, based on Convolutional Neural Network (CNN), a tone mapping correction framework is introduced. Furthermore, inconsistent lighting across multi-view images, resulting from variations in camera settings and complex scene illumination, often leads to geometric constraint mismatches and deviations in the reconstructed surface. To overcome this, we propose a normal compensation mechanism that integrates reference normals extracted from single-view image with normals computed from multi-view observations to effectively constrain geometric inconsistencies. Extensive experimental evaluations demonstrate that GS-3I can achieve robust and accurate surface reconstruction across complex illumination scenarios, highlighting its effectiveness and versatility in this critical challenge. https://github.com/TFwang-9527/GS-3I
GS-3I: Gaussian Splatting for Surface Reconstruction from Illumination-Inconsistent Images
Mar 16, 2025Accurate geometric surface reconstruction, providing essential environmental information for navigation and manipulation tasks, is critical for enabling robotic self-exploration and interaction. Recently, 3D Gaussian Splatting (3DGS) has gained significant attention in the field of surface reconstruction due to its impressive geometric quality and computational efficiency. While recent relevant advancements in novel view synthesis under inconsistent illumination using 3DGS have shown promise, the challenge of robust surface reconstruction under such conditions is still being explored. To address this challenge, we propose a method called GS-3I. Specifically, to mitigate 3D Gaussian optimization bias caused by underexposed regions in single-view images, based on Convolutional Neural Network (CNN), a tone mapping correction framework is introduced. Furthermore, inconsistent lighting across multi-view images, resulting from variations in camera settings and complex scene illumination, often leads to geometric constraint mismatches and deviations in the reconstructed surface. To overcome this, we propose a normal compensation mechanism that integrates reference normals extracted from single-view image with normals computed from multi-view observations to effectively constrain geometric inconsistencies. Extensive experimental evaluations demonstrate that GS-3I can achieve robust and accurate surface reconstruction across complex illumination scenarios, highlighting its effectiveness and versatility in this critical challenge. https://github.com/TFwang-9527/GS-3I
Balance Divergence for Knowledge Distillation
Jan 14, 2025



Knowledge distillation has been widely adopted in computer vision task processing, since it can effectively enhance the performance of lightweight student networks by leveraging the knowledge transferred from cumbersome teacher networks. Most existing knowledge distillation methods utilize Kullback-Leibler divergence to mimic the logit output probabilities between the teacher network and the student network. Nonetheless, these methods may neglect the negative parts of the teacher's ''dark knowledge'' because the divergence calculations may ignore the effect of the minute probabilities from the teacher's logit output. This deficiency may lead to suboptimal performance in logit mimicry during the distillation process and result in an imbalance of information acquired by the student network. In this paper, we investigate the impact of this imbalance and propose a novel method, named Balance Divergence Distillation. By introducing a compensatory operation using reverse Kullback-Leibler divergence, our method can improve the modeling of the extremely small values in the negative from the teacher and preserve the learning capacity for the positive. Furthermore, we test the impact of different temperature coefficients adjustments, which may conducted to further balance for knowledge transferring. We evaluate the proposed method on several computer vision tasks, including image classification and semantic segmentation. The evaluation results show that our method achieves an accuracy improvement of 1%~3% for lightweight students on both CIFAR-100 and ImageNet dataset, and a 4.55% improvement in mIoU for PSP-ResNet18 on the Cityscapes dataset. The experiments show that our method is a simple yet highly effective solution that can be smoothly applied to different knowledge distillation methods.
Dovetail: A CPU/GPU Heterogeneous Speculative Decoding for LLM inference
Dec 25, 2024Due to the high resource demands of Large Language Models (LLMs), achieving widespread deployment on consumer-grade devices presents significant challenges. Typically, personal or consumer-grade devices, including servers configured prior to the era of large-scale models, generally have relatively weak GPUs and relatively strong CPUs. However, most current methods primarily depend on GPUs for computation. Therefore, we propose Dovetail, an approach that deploys the draft model on the GPU to generate draft tokens while allowing the target model to perform parallel verification on the CPU, thereby improving the utilization of all available hardware resources and occupying less inter-device communication bandwidth. Accordingly, we have redesigned the draft model to better align with heterogeneous hardware characteristics. To this end, we implemented several optimizations: reducing the number of draft tokens to mitigate latency in parallel verification, increasing the depth of the draft model to enhance its predictive capacity, and introducing DGF (Dynamic Gating Fusion) to improve the integration of features and token embeddings. In the HumanEval benchmark, Dovetail achieved an inference speed of 5.86 tokens per second for LLaMA2-Chat-7B using 3GB of VRAM, representing an approximately 2.77x improvement over CPU-only inference. Furthermore, the inference speed was increased to 8 tokens per second when utilizing 7GB of VRAM.
Deep Tiny Network for Recognition-Oriented Face Image Quality Assessment
Jun 09, 2021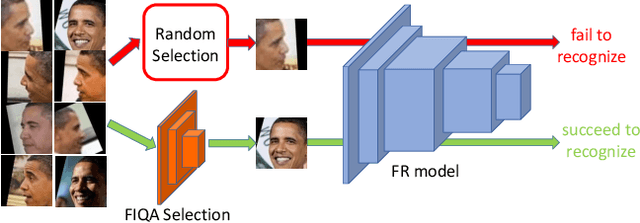
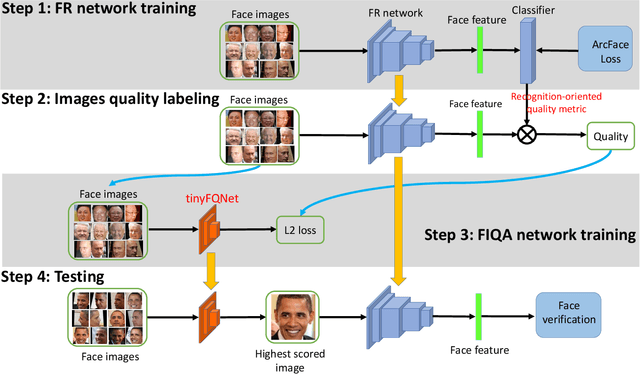
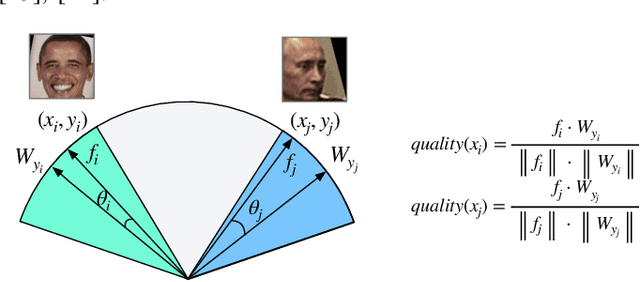
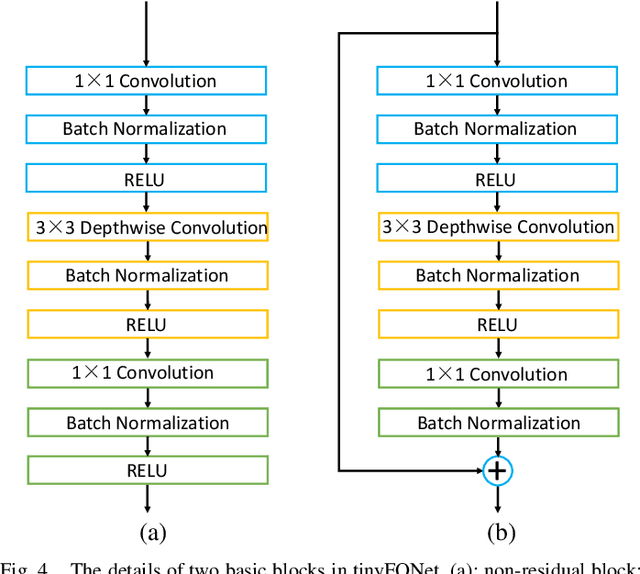
Face recognition has made significant progress in recent years due to deep convolutional neural networks (CNN). In many face recognition (FR) scenarios, face images are acquired from a sequence with huge intra-variations. These intra-variations, which are mainly affected by the low-quality face images, cause instability of recognition performance. Previous works have focused on ad-hoc methods to select frames from a video or use face image quality assessment (FIQA) methods, which consider only a particular or combination of several distortions. In this work, we present an efficient non-reference image quality assessment for FR that directly links image quality assessment (IQA) and FR. More specifically, we propose a new measurement to evaluate image quality without any reference. Based on the proposed quality measurement, we propose a deep Tiny Face Quality network (tinyFQnet) to learn a quality prediction function from data. We evaluate the proposed method for different powerful FR models on two classical video-based (or template-based) benchmark: IJB-B and YTF. Extensive experiments show that, although the tinyFQnet is much smaller than the others, the proposed method outperforms state-of-the-art quality assessment methods in terms of effectiveness and efficiency.
Correlation Congruence for Knowledge Distillation
Apr 03, 2019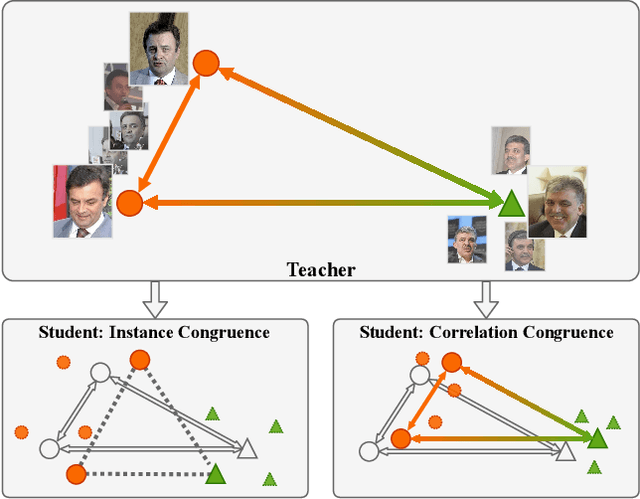
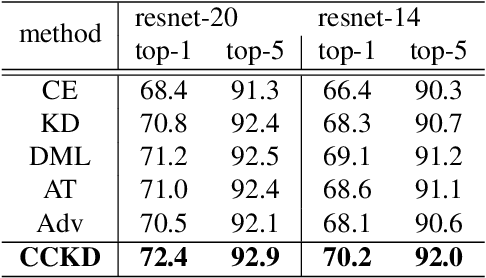
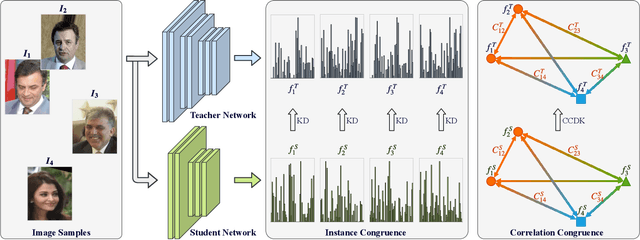
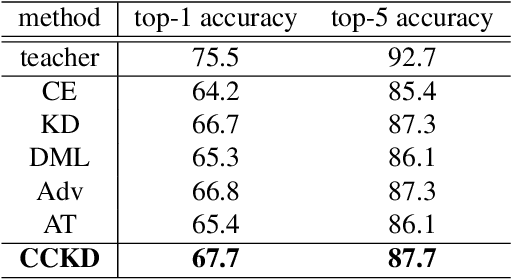
Most teacher-student frameworks based on knowledge distillation (KD) depend on a strong congruent constraint on instance level. However, they usually ignore the correlation between multiple instances, which is also valuable for knowledge transfer. In this work, we propose a new framework named correlation congruence for knowledge distillation (CCKD), which transfers not only the instance-level information, but also the correlation between instances. Furthermore, a generalized kernel method based on Taylor series expansion is proposed to better capture the correlation between instances. Empirical experiments and ablation studies on image classification tasks (including CIFAR-100, ImageNet-1K) and metric learning tasks (including ReID and Face Recognition) show that the proposed CCKD substantially outperforms the original KD and achieves state-of-the-art accuracy compared with other SOTA KD-based methods. The CCKD can be easily deployed in the majority of the teacher-student framework such as KD and hint-based learning methods.
ThunderNet: Towards Real-time Generic Object Detection
Mar 28, 2019



Real-time generic object detection on mobile platforms is a crucial but challenging computer vision task. However, previous CNN-based detectors suffer from enormous computational cost, which hinders them from real-time inference in computation-constrained scenarios. In this paper, we investigate the effectiveness of two-stage detectors in real-time generic detection and propose a lightweight two-stage detector named ThunderNet. In the backbone part, we analyze the drawbacks in previous lightweight backbones and present a lightweight backbone designed for object detection. In the detection part, we exploit an extremely efficient RPN and detection head design. To generate more discriminative feature representation, we design two efficient architecture blocks, Context Enhancement Module and Spatial Attention Module. At last, we investigate the balance between the input resolution, the backbone, and the detection head. Compared with lightweight one-stage detectors, ThunderNet achieves superior performance with only 40% of the computational cost on PASCAL VOC and COCO benchmarks. Without bells and whistles, our model runs at 24.1 fps on an ARM-based device. To the best of our knowledge, this is the first real-time detector reported on ARM platforms. Code will be released for paper reproduction.