 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSee What You Need: Query-Aware Visual Intelligence through Reasoning-Perception Loops
Aug 25, 2025Human video comprehension demonstrates dynamic coordination between reasoning and visual attention, adaptively focusing on query-relevant details. However, current long-form video question answering systems employ rigid pipelines that decouple reasoning from perception, leading to either information loss through premature visual abstraction or computational inefficiency through exhaustive processing. The core limitation lies in the inability to adapt visual extraction to specific reasoning requirements, different queries demand fundamentally different visual evidence from the same video content. In this work, we present CAVIA, a training-free framework that revolutionizes video understanding through reasoning, perception coordination. Unlike conventional approaches where visual processing operates independently of reasoning, CAVIA creates a closed-loop system where reasoning continuously guides visual extraction based on identified information gaps. CAVIA introduces three innovations: (1) hierarchical reasoning, guided localization to precise frames; (2) cross-modal semantic bridging for targeted extraction; (3) confidence-driven iterative synthesis. CAVIA achieves state-of-the-art performance on challenging benchmarks: EgoSchema (65.7%, +5.3%), NExT-QA (76.1%, +2.6%), and IntentQA (73.8%, +6.9%), demonstrating that dynamic reasoning-perception coordination provides a scalable paradigm for video understanding.
EffiQA: Efficient Question-Answering with Strategic Multi-Model Collaboration on Knowledge Graphs
Jun 03, 2024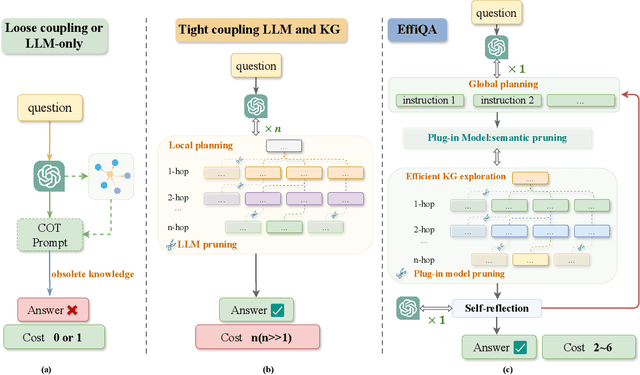



While large language models (LLMs) have shown remarkable capabilities in natural language processing, they struggle with complex, multi-step reasoning tasks involving knowledge graphs (KGs). Existing approaches that integrate LLMs and KGs either underutilize the reasoning abilities of LLMs or suffer from prohibitive computational costs due to tight coupling. To address these limitations, we propose a novel collaborative framework named EffiQA that can strike a balance between performance and efficiency via an iterative paradigm. EffiQA consists of three stages: global planning, efficient KG exploration, and self-reflection. Specifically, EffiQA leverages the commonsense capability of LLMs to explore potential reasoning pathways through global planning. Then, it offloads semantic pruning to a small plug-in model for efficient KG exploration. Finally, the exploration results are fed to LLMs for self-reflection to further improve the global planning and efficient KG exploration. Empirical evidence on multiple KBQA benchmarks shows EffiQA's effectiveness, achieving an optimal balance between reasoning accuracy and computational costs. We hope the proposed new framework will pave the way for efficient, knowledge-intensive querying by redefining the integration of LLMs and KGs, fostering future research on knowledge-based question answering.
On the Equity of Nuclear Norm Maximization in Unsupervised Domain Adaptation
Apr 12, 2022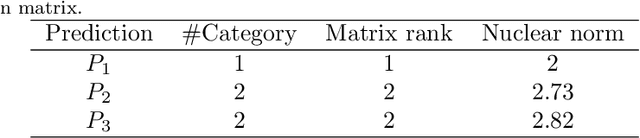



Nuclear norm maximization has shown the power to enhance the transferability of unsupervised domain adaptation model (UDA) in an empirical scheme. In this paper, we identify a new property termed equity, which indicates the balance degree of predicted classes, to demystify the efficacy of nuclear norm maximization for UDA theoretically. With this in mind, we offer a new discriminability-and-equity maximization paradigm built on squares loss, such that predictions are equalized explicitly. To verify its feasibility and flexibility, two new losses termed Class Weighted Squares Maximization (CWSM) and Normalized Squares Maximization (NSM), are proposed to maximize both predictive discriminability and equity, from the class level and the sample level, respectively. Importantly, we theoretically relate these two novel losses (i.e., CWSM and NSM) to the equity maximization under mild conditions, and empirically suggest the importance of the predictive equity in UDA. Moreover, it is very efficient to realize the equity constraints in both losses. Experiments of cross-domain image classification on three popular benchmark datasets show that both CWSM and NSM contribute to outperforming the corresponding counterparts.
Deep Tiny Network for Recognition-Oriented Face Image Quality Assessment
Jun 09, 2021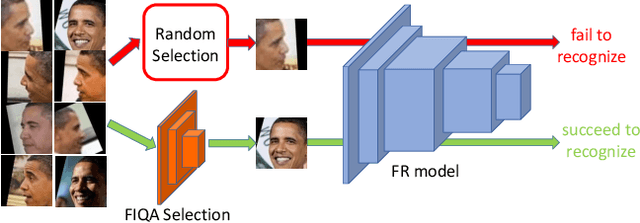
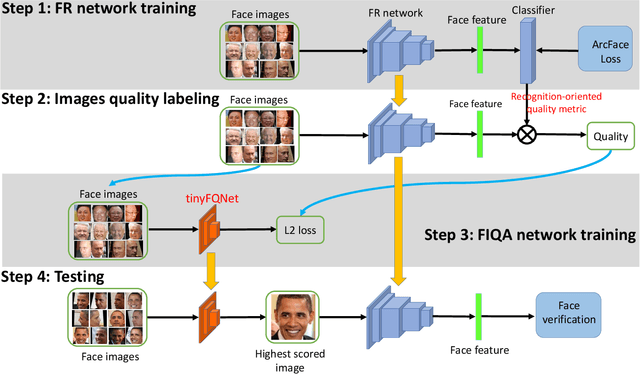
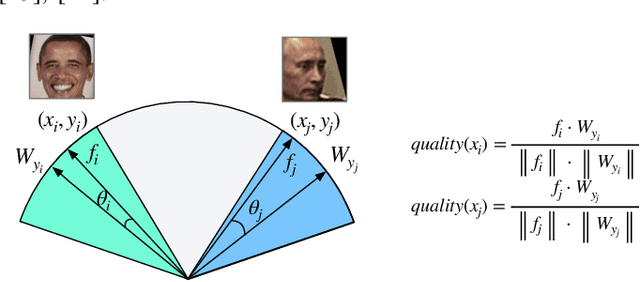
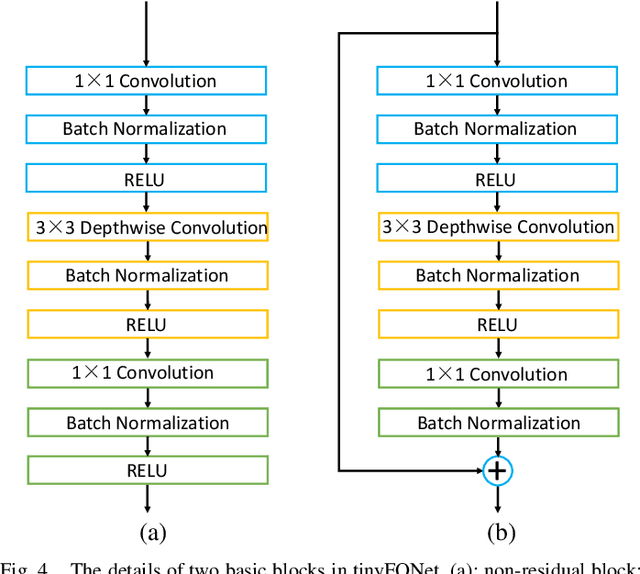
Face recognition has made significant progress in recent years due to deep convolutional neural networks (CNN). In many face recognition (FR) scenarios, face images are acquired from a sequence with huge intra-variations. These intra-variations, which are mainly affected by the low-quality face images, cause instability of recognition performance. Previous works have focused on ad-hoc methods to select frames from a video or use face image quality assessment (FIQA) methods, which consider only a particular or combination of several distortions. In this work, we present an efficient non-reference image quality assessment for FR that directly links image quality assessment (IQA) and FR. More specifically, we propose a new measurement to evaluate image quality without any reference. Based on the proposed quality measurement, we propose a deep Tiny Face Quality network (tinyFQnet) to learn a quality prediction function from data. We evaluate the proposed method for different powerful FR models on two classical video-based (or template-based) benchmark: IJB-B and YTF. Extensive experiments show that, although the tinyFQnet is much smaller than the others, the proposed method outperforms state-of-the-art quality assessment methods in terms of effectiveness and efficiency.
Knowledge Distillation via Route Constrained Optimization
Apr 19, 2019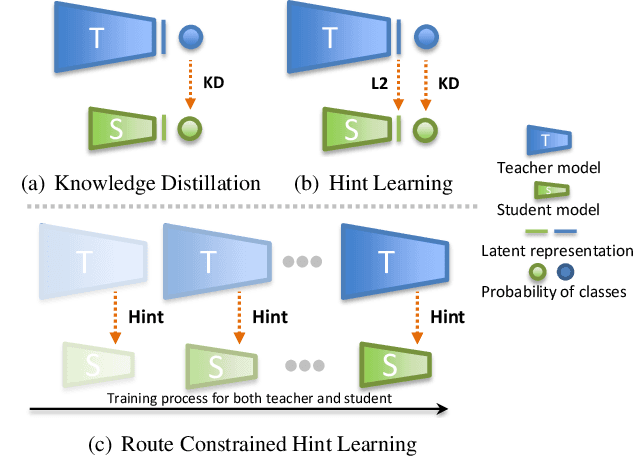
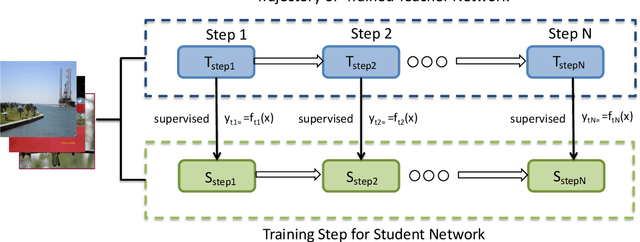
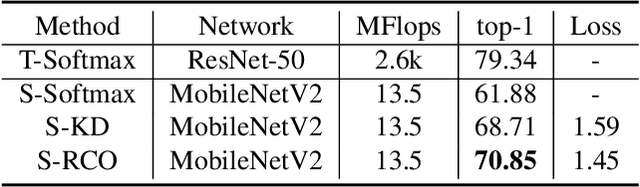
Distillation-based learning boosts the performance of the miniaturized neural network based on the hypothesis that the representation of a teacher model can be used as structured and relatively weak supervision, and thus would be easily learned by a miniaturized model. However, we find that the representation of a converged heavy model is still a strong constraint for training a small student model, which leads to a high lower bound of congruence loss. In this work, inspired by curriculum learning we consider the knowledge distillation from the perspective of curriculum learning by routing. Instead of supervising the student model with a converged teacher model, we supervised it with some anchor points selected from the route in parameter space that the teacher model passed by, as we called route constrained optimization (RCO). We experimentally demonstrate this simple operation greatly reduces the lower bound of congruence loss for knowledge distillation, hint and mimicking learning. On close-set classification tasks like CIFAR100 and ImageNet, RCO improves knowledge distillation by 2.14% and 1.5% respectively. For the sake of evaluating the generalization, we also test RCO on the open-set face recognition task MegaFace.
Correlation Congruence for Knowledge Distillation
Apr 03, 2019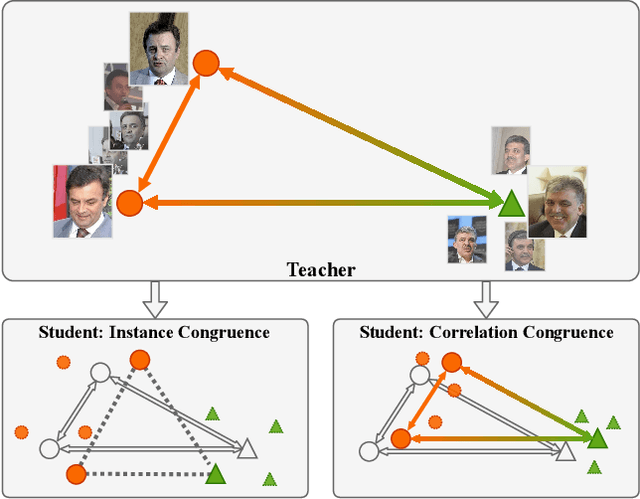
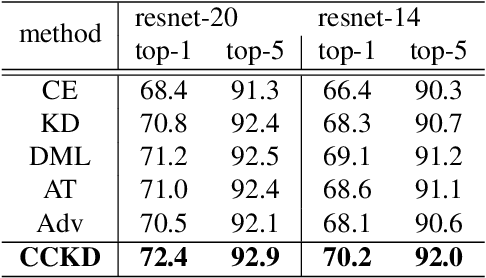
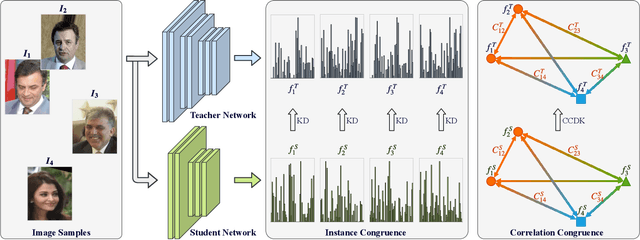
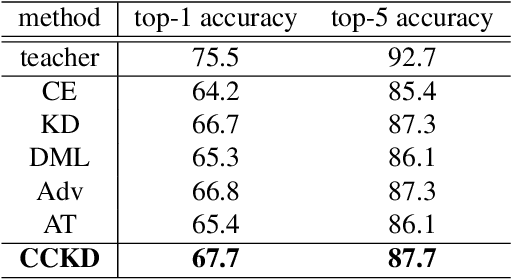
Most teacher-student frameworks based on knowledge distillation (KD) depend on a strong congruent constraint on instance level. However, they usually ignore the correlation between multiple instances, which is also valuable for knowledge transfer. In this work, we propose a new framework named correlation congruence for knowledge distillation (CCKD), which transfers not only the instance-level information, but also the correlation between instances. Furthermore, a generalized kernel method based on Taylor series expansion is proposed to better capture the correlation between instances. Empirical experiments and ablation studies on image classification tasks (including CIFAR-100, ImageNet-1K) and metric learning tasks (including ReID and Face Recognition) show that the proposed CCKD substantially outperforms the original KD and achieves state-of-the-art accuracy compared with other SOTA KD-based methods. The CCKD can be easily deployed in the majority of the teacher-student framework such as KD and hint-based learning methods.