 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation via Route Constrained Optimization
Paper and Code
Apr 19, 2019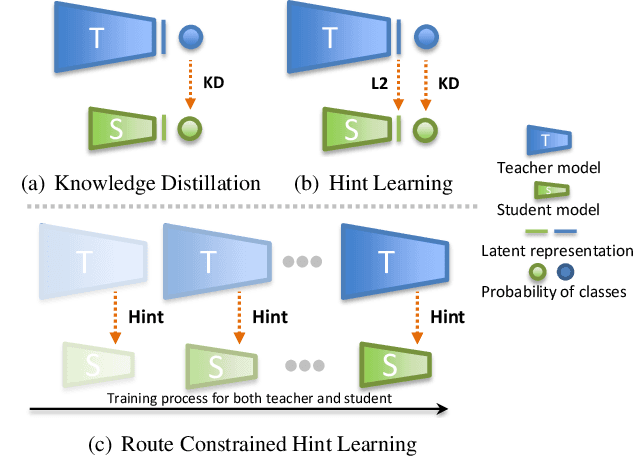
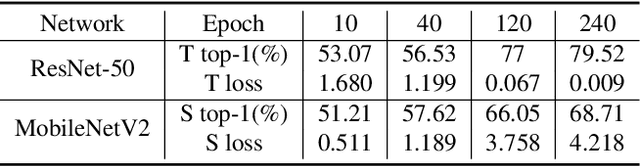
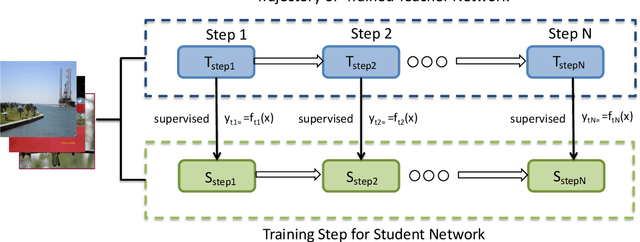
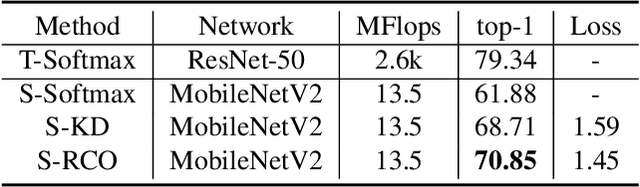
Distillation-based learning boosts the performance of the miniaturized neural network based on the hypothesis that the representation of a teacher model can be used as structured and relatively weak supervision, and thus would be easily learned by a miniaturized model. However, we find that the representation of a converged heavy model is still a strong constraint for training a small student model, which leads to a high lower bound of congruence loss. In this work, inspired by curriculum learning we consider the knowledge distillation from the perspective of curriculum learning by routing. Instead of supervising the student model with a converged teacher model, we supervised it with some anchor points selected from the route in parameter space that the teacher model passed by, as we called route constrained optimization (RCO). We experimentally demonstrate this simple operation greatly reduces the lower bound of congruence loss for knowledge distillation, hint and mimicking learning. On close-set classification tasks like CIFAR100 and ImageNet, RCO improves knowledge distillation by 2.14% and 1.5% respectively. For the sake of evaluating the generalization, we also test RCO on the open-set face recognition task MegaFace.