 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFACE: A Face-based Autoregressive Representation for High-Fidelity and Efficient Mesh Generation
Mar 03, 2026Autoregressive models for 3D mesh generation suffer from a fundamental limitation: they flatten meshes into long vertex-coordinate sequences. This results in prohibitive computational costs, hindering the efficient synthesis of high-fidelity geometry. We argue this bottleneck stems from operating at the wrong semantic level. We introduce FACE, a novel Autoregressive Autoencoder (ARAE) framework that reconceptualizes the task by generating meshes at the face level. Our one-face-one-token strategy treats each triangle face, the fundamental building block of a mesh, as a single, unified token. This simple yet powerful design reduces the sequence length by a factor of nine, leading to an unprecedented compression ratio of 0.11, halving the previous state-of-the-art. This dramatic efficiency gain does not compromise quality; by pairing our face-level decoder with a powerful VecSet encoder, FACE achieves state-of-the-art reconstruction quality on standard benchmarks. The versatility of the learned latent space is further demonstrated by training a latent diffusion model that achieves high-fidelity, single-image-to-mesh generation. FACE provides a simple, scalable, and powerful paradigm that lowers the barrier to high-quality structured 3D content creation.
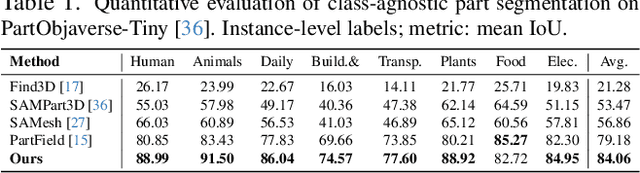
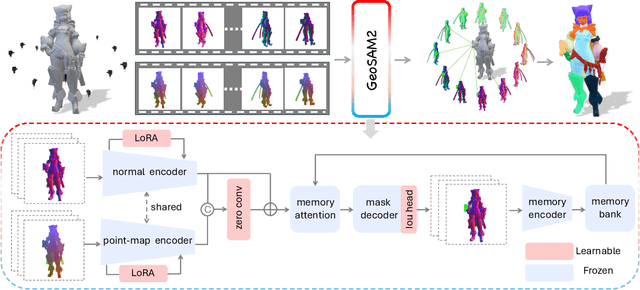
GeoSAM2: Unleashing the Power of SAM2 for 3D Part Segmentation
Aug 19, 2025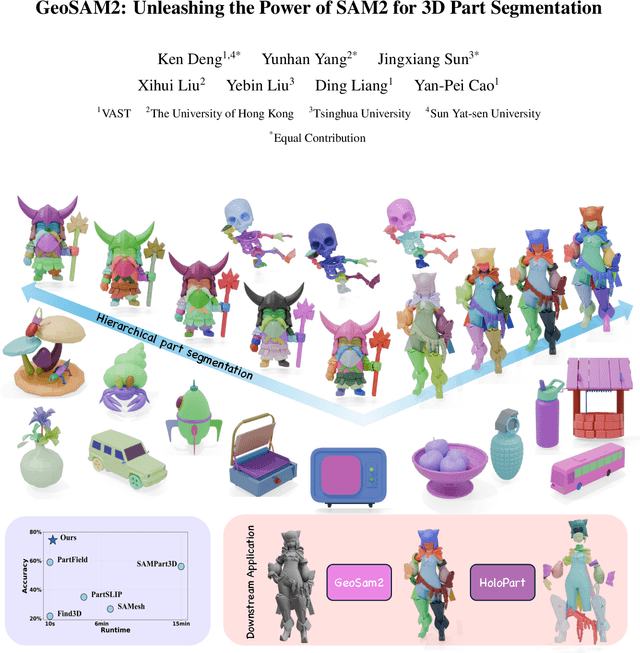

Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.
OmniPart: Part-Aware 3D Generation with Semantic Decoupling and Structural Cohesion
Jul 08, 2025The creation of 3D assets with explicit, editable part structures is crucial for advancing interactive applications, yet most generative methods produce only monolithic shapes, limiting their utility. We introduce OmniPart, a novel framework for part-aware 3D object generation designed to achieve high semantic decoupling among components while maintaining robust structural cohesion. OmniPart uniquely decouples this complex task into two synergistic stages: (1) an autoregressive structure planning module generates a controllable, variable-length sequence of 3D part bounding boxes, critically guided by flexible 2D part masks that allow for intuitive control over part decomposition without requiring direct correspondences or semantic labels; and (2) a spatially-conditioned rectified flow model, efficiently adapted from a pre-trained holistic 3D generator, synthesizes all 3D parts simultaneously and consistently within the planned layout. Our approach supports user-defined part granularity, precise localization, and enables diverse downstream applications. Extensive experiments demonstrate that OmniPart achieves state-of-the-art performance, paving the way for more interpretable, editable, and versatile 3D content.
SparseFlex: High-Resolution and Arbitrary-Topology 3D Shape Modeling
Mar 27, 2025Creating high-fidelity 3D meshes with arbitrary topology, including open surfaces and complex interiors, remains a significant challenge. Existing implicit field methods often require costly and detail-degrading watertight conversion, while other approaches struggle with high resolutions. This paper introduces SparseFlex, a novel sparse-structured isosurface representation that enables differentiable mesh reconstruction at resolutions up to $1024^3$ directly from rendering losses. SparseFlex combines the accuracy of Flexicubes with a sparse voxel structure, focusing computation on surface-adjacent regions and efficiently handling open surfaces. Crucially, we introduce a frustum-aware sectional voxel training strategy that activates only relevant voxels during rendering, dramatically reducing memory consumption and enabling high-resolution training. This also allows, for the first time, the reconstruction of mesh interiors using only rendering supervision. Building upon this, we demonstrate a complete shape modeling pipeline by training a variational autoencoder (VAE) and a rectified flow transformer for high-quality 3D shape generation. Our experiments show state-of-the-art reconstruction accuracy, with a ~82% reduction in Chamfer Distance and a ~88% increase in F-score compared to previous methods, and demonstrate the generation of high-resolution, detailed 3D shapes with arbitrary topology. By enabling high-resolution, differentiable mesh reconstruction and generation with rendering losses, SparseFlex significantly advances the state-of-the-art in 3D shape representation and modeling.
TripoSG: High-Fidelity 3D Shape Synthesis using Large-Scale Rectified Flow Models
Feb 10, 2025Recent advancements in diffusion techniques have propelled image and video generation to unprece- dented levels of quality, significantly accelerating the deployment and application of generative AI. However, 3D shape generation technology has so far lagged behind, constrained by limitations in 3D data scale, complexity of 3D data process- ing, and insufficient exploration of advanced tech- niques in the 3D domain. Current approaches to 3D shape generation face substantial challenges in terms of output quality, generalization capa- bility, and alignment with input conditions. We present TripoSG, a new streamlined shape diffu- sion paradigm capable of generating high-fidelity 3D meshes with precise correspondence to input images. Specifically, we propose: 1) A large-scale rectified flow transformer for 3D shape generation, achieving state-of-the-art fidelity through training on extensive, high-quality data. 2) A hybrid supervised training strategy combining SDF, normal, and eikonal losses for 3D VAE, achieving high- quality 3D reconstruction performance. 3) A data processing pipeline to generate 2 million high- quality 3D samples, highlighting the crucial rules for data quality and quantity in training 3D gen- erative models. Through comprehensive experi- ments, we have validated the effectiveness of each component in our new framework. The seamless integration of these parts has enabled TripoSG to achieve state-of-the-art performance in 3D shape generation. The resulting 3D shapes exhibit en- hanced detail due to high-resolution capabilities and demonstrate exceptional fidelity to input im- ages. Moreover, TripoSG demonstrates improved versatility in generating 3D models from diverse image styles and contents, showcasing strong gen- eralization capabilities. To foster progress and innovation in the field of 3D generation, we will make our model publicly available.
MIDI: Multi-Instance Diffusion for Single Image to 3D Scene Generation
Dec 04, 2024This paper introduces MIDI, a novel paradigm for compositional 3D scene generation from a single image. Unlike existing methods that rely on reconstruction or retrieval techniques or recent approaches that employ multi-stage object-by-object generation, MIDI extends pre-trained image-to-3D object generation models to multi-instance diffusion models, enabling the simultaneous generation of multiple 3D instances with accurate spatial relationships and high generalizability. At its core, MIDI incorporates a novel multi-instance attention mechanism, that effectively captures inter-object interactions and spatial coherence directly within the generation process, without the need for complex multi-step processes. The method utilizes partial object images and global scene context as inputs, directly modeling object completion during 3D generation. During training, we effectively supervise the interactions between 3D instances using a limited amount of scene-level data, while incorporating single-object data for regularization, thereby maintaining the pre-trained generalization ability. MIDI demonstrates state-of-the-art performance in image-to-scene generation, validated through evaluations on synthetic data, real-world scene data, and stylized scene images generated by text-to-image diffusion models.
DetailGen3D: Generative 3D Geometry Enhancement via Data-Dependent Flow
Nov 25, 2024Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.
TEXGen: a Generative Diffusion Model for Mesh Textures
Nov 22, 2024



While high-quality texture maps are essential for realistic 3D asset rendering, few studies have explored learning directly in the texture space, especially on large-scale datasets. In this work, we depart from the conventional approach of relying on pre-trained 2D diffusion models for test-time optimization of 3D textures. Instead, we focus on the fundamental problem of learning in the UV texture space itself. For the first time, we train a large diffusion model capable of directly generating high-resolution texture maps in a feed-forward manner. To facilitate efficient learning in high-resolution UV spaces, we propose a scalable network architecture that interleaves convolutions on UV maps with attention layers on point clouds. Leveraging this architectural design, we train a 700 million parameter diffusion model that can generate UV texture maps guided by text prompts and single-view images. Once trained, our model naturally supports various extended applications, including text-guided texture inpainting, sparse-view texture completion, and text-driven texture synthesis. Project page is at http://cvmi-lab.github.io/TEXGen/.
* Accepted to SIGGRAPH Asia Journal Article (TOG 2024)
TripoSR: Fast 3D Object Reconstruction from a Single Image
Mar 04, 2024



This technical report introduces TripoSR, a 3D reconstruction model leveraging transformer architecture for fast feed-forward 3D generation, producing 3D mesh from a single image in under 0.5 seconds. Building upon the LRM network architecture, TripoSR integrates substantial improvements in data processing, model design, and training techniques. Evaluations on public datasets show that TripoSR exhibits superior performance, both quantitatively and qualitatively, compared to other open-source alternatives. Released under the MIT license, TripoSR is intended to empower researchers, developers, and creatives with the latest advancements in 3D generative AI.
Triplane Meets Gaussian Splatting: Fast and Generalizable Single-View 3D Reconstruction with Transformers
Dec 16, 2023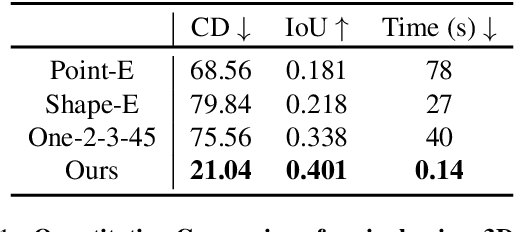
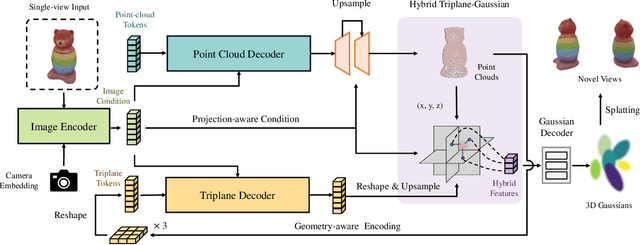
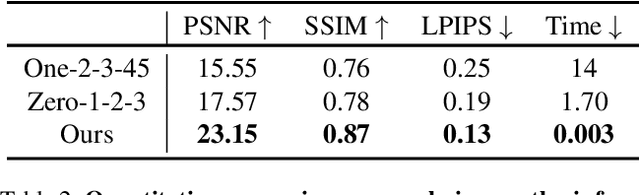

Recent advancements in 3D reconstruction from single images have been driven by the evolution of generative models. Prominent among these are methods based on Score Distillation Sampling (SDS) and the adaptation of diffusion models in the 3D domain. Despite their progress, these techniques often face limitations due to slow optimization or rendering processes, leading to extensive training and optimization times. In this paper, we introduce a novel approach for single-view reconstruction that efficiently generates a 3D model from a single image via feed-forward inference. Our method utilizes two transformer-based networks, namely a point decoder and a triplane decoder, to reconstruct 3D objects using a hybrid Triplane-Gaussian intermediate representation. This hybrid representation strikes a balance, achieving a faster rendering speed compared to implicit representations while simultaneously delivering superior rendering quality than explicit representations. The point decoder is designed for generating point clouds from single images, offering an explicit representation which is then utilized by the triplane decoder to query Gaussian features for each point. This design choice addresses the challenges associated with directly regressing explicit 3D Gaussian attributes characterized by their non-structural nature. Subsequently, the 3D Gaussians are decoded by an MLP to enable rapid rendering through splatting. Both decoders are built upon a scalable, transformer-based architecture and have been efficiently trained on large-scale 3D datasets. The evaluations conducted on both synthetic datasets and real-world images demonstrate that our method not only achieves higher quality but also ensures a faster runtime in comparison to previous state-of-the-art techniques. Please see our project page at https://zouzx.github.io/TriplaneGaussian/.