 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAnimaX: Animating the Inanimate in 3D with Joint Video-Pose Diffusion Models
Jun 24, 2025We present AnimaX, a feed-forward 3D animation framework that bridges the motion priors of video diffusion models with the controllable structure of skeleton-based animation. Traditional motion synthesis methods are either restricted to fixed skeletal topologies or require costly optimization in high-dimensional deformation spaces. In contrast, AnimaX effectively transfers video-based motion knowledge to the 3D domain, supporting diverse articulated meshes with arbitrary skeletons. Our method represents 3D motion as multi-view, multi-frame 2D pose maps, and enables joint video-pose diffusion conditioned on template renderings and a textual motion prompt. We introduce shared positional encodings and modality-aware embeddings to ensure spatial-temporal alignment between video and pose sequences, effectively transferring video priors to motion generation task. The resulting multi-view pose sequences are triangulated into 3D joint positions and converted into mesh animation via inverse kinematics. Trained on a newly curated dataset of 160,000 rigged sequences, AnimaX achieves state-of-the-art results on VBench in generalization, motion fidelity, and efficiency, offering a scalable solution for category-agnostic 3D animation. Project page: \href{https://anima-x.github.io/}{https://anima-x.github.io/}.
DetailGen3D: Generative 3D Geometry Enhancement via Data-Dependent Flow
Nov 25, 2024Modern 3D generation methods can rapidly create shapes from sparse or single views, but their outputs often lack geometric detail due to computational constraints. We present DetailGen3D, a generative approach specifically designed to enhance these generated 3D shapes. Our key insight is to model the coarse-to-fine transformation directly through data-dependent flows in latent space, avoiding the computational overhead of large-scale 3D generative models. We introduce a token matching strategy that ensures accurate spatial correspondence during refinement, enabling local detail synthesis while preserving global structure. By carefully designing our training data to match the characteristics of synthesized coarse shapes, our method can effectively enhance shapes produced by various 3D generation and reconstruction approaches, from single-view to sparse multi-view inputs. Extensive experiments demonstrate that DetailGen3D achieves high-fidelity geometric detail synthesis while maintaining efficiency in training.
DreamCraft3D++: Efficient Hierarchical 3D Generation with Multi-Plane Reconstruction Model
Oct 16, 2024
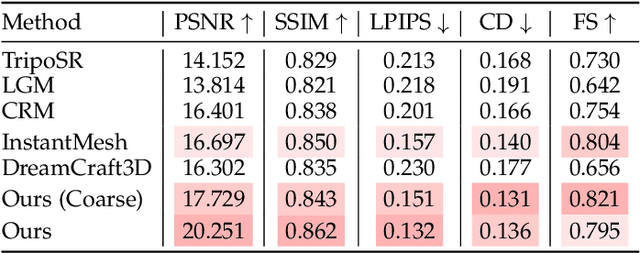


We introduce DreamCraft3D++, an extension of DreamCraft3D that enables efficient high-quality generation of complex 3D assets. DreamCraft3D++ inherits the multi-stage generation process of DreamCraft3D, but replaces the time-consuming geometry sculpting optimization with a feed-forward multi-plane based reconstruction model, speeding up the process by 1000x. For texture refinement, we propose a training-free IP-Adapter module that is conditioned on the enhanced multi-view images to enhance texture and geometry consistency, providing a 4x faster alternative to DreamCraft3D's DreamBooth fine-tuning. Experiments on diverse datasets demonstrate DreamCraft3D++'s ability to generate creative 3D assets with intricate geometry and realistic 360{\deg} textures, outperforming state-of-the-art image-to-3D methods in quality and speed. The full implementation will be open-sourced to enable new possibilities in 3D content creation.
ConTex-Human: Free-View Rendering of Human from a Single Image with Texture-Consistent Synthesis
Nov 28, 2023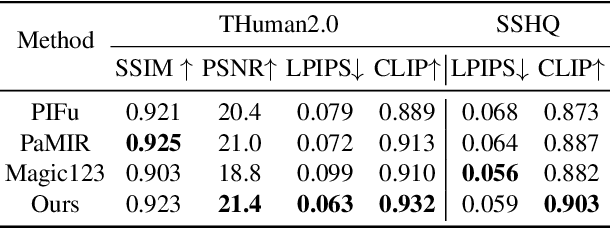

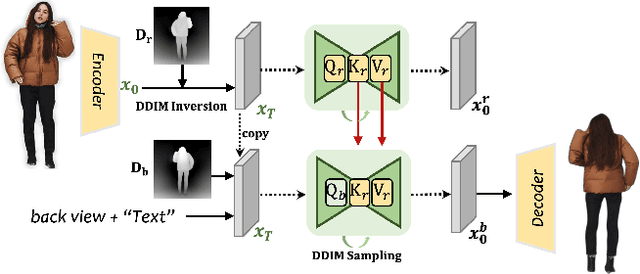
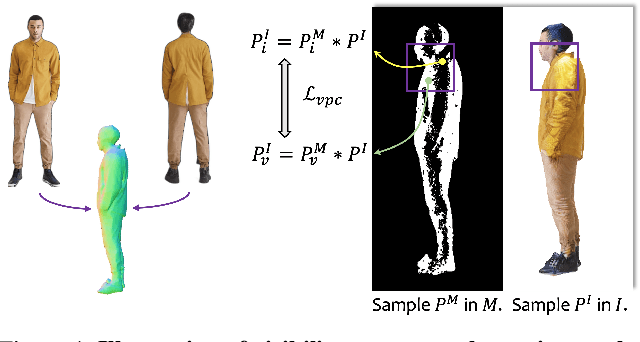
In this work, we propose a method to address the challenge of rendering a 3D human from a single image in a free-view manner. Some existing approaches could achieve this by using generalizable pixel-aligned implicit fields to reconstruct a textured mesh of a human or by employing a 2D diffusion model as guidance with the Score Distillation Sampling (SDS) method, to lift the 2D image into 3D space. However, a generalizable implicit field often results in an over-smooth texture field, while the SDS method tends to lead to a texture-inconsistent novel view with the input image. In this paper, we introduce a texture-consistent back view synthesis module that could transfer the reference image content to the back view through depth and text-guided attention injection. Moreover, to alleviate the color distortion that occurs in the side region, we propose a visibility-aware patch consistency regularization for texture mapping and refinement combined with the synthesized back view texture. With the above techniques, we could achieve high-fidelity and texture-consistent human rendering from a single image. Experiments conducted on both real and synthetic data demonstrate the effectiveness of our method and show that our approach outperforms previous baseline methods.
HumanRef: Single Image to 3D Human Generation via Reference-Guided Diffusion
Nov 28, 2023

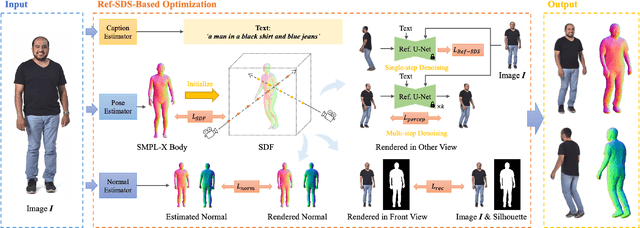
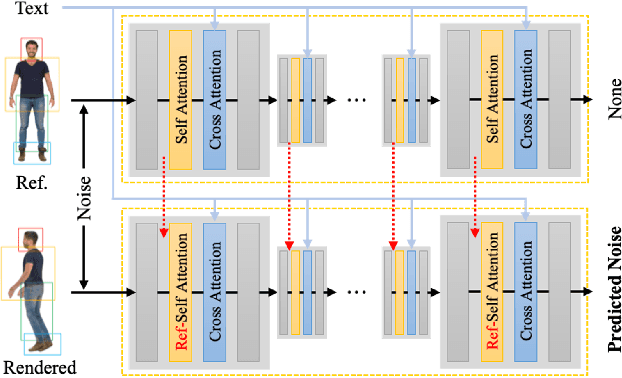
Generating a 3D human model from a single reference image is challenging because it requires inferring textures and geometries in invisible views while maintaining consistency with the reference image. Previous methods utilizing 3D generative models are limited by the availability of 3D training data. Optimization-based methods that lift text-to-image diffusion models to 3D generation often fail to preserve the texture details of the reference image, resulting in inconsistent appearances in different views. In this paper, we propose HumanRef, a 3D human generation framework from a single-view input. To ensure the generated 3D model is photorealistic and consistent with the input image, HumanRef introduces a novel method called reference-guided score distillation sampling (Ref-SDS), which effectively incorporates image guidance into the generation process. Furthermore, we introduce region-aware attention to Ref-SDS, ensuring accurate correspondence between different body regions. Experimental results demonstrate that HumanRef outperforms state-of-the-art methods in generating 3D clothed humans with fine geometry, photorealistic textures, and view-consistent appearances.
Neural Point-based Volumetric Avatar: Surface-guided Neural Points for Efficient and Photorealistic Volumetric Head Avatar
Jul 11, 2023



Rendering photorealistic and dynamically moving human heads is crucial for ensuring a pleasant and immersive experience in AR/VR and video conferencing applications. However, existing methods often struggle to model challenging facial regions (e.g., mouth interior, eyes, hair/beard), resulting in unrealistic and blurry results. In this paper, we propose {\fullname} ({\name}), a method that adopts the neural point representation as well as the neural volume rendering process and discards the predefined connectivity and hard correspondence imposed by mesh-based approaches. Specifically, the neural points are strategically constrained around the surface of the target expression via a high-resolution UV displacement map, achieving increased modeling capacity and more accurate control. We introduce three technical innovations to improve the rendering and training efficiency: a patch-wise depth-guided (shading point) sampling strategy, a lightweight radiance decoding process, and a Grid-Error-Patch (GEP) ray sampling strategy during training. By design, our {\name} is better equipped to handle topologically changing regions and thin structures while also ensuring accurate expression control when animating avatars. Experiments conducted on three subjects from the Multiface dataset demonstrate the effectiveness of our designs, outperforming previous state-of-the-art methods, especially in handling challenging facial regions.
DoubleField: Bridging the Neural Surface and Radiance Fields for High-fidelity Human Rendering
Jun 08, 2021



We introduce DoubleField, a novel representation combining the merits of both surface field and radiance field for high-fidelity human rendering. Within DoubleField, the surface field and radiance field are associated together by a shared feature embedding and a surface-guided sampling strategy. In this way, DoubleField has a continuous but disentangled learning space for geometry and appearance modeling, which supports fast training, inference, and finetuning. To achieve high-fidelity free-viewpoint rendering, DoubleField is further augmented to leverage ultra-high-resolution inputs, where a view-to-view transformer and a transfer learning scheme are introduced for more efficient learning and finetuning from sparse-view inputs at original resolutions. The efficacy of DoubleField is validated by the quantitative evaluations on several datasets and the qualitative results in a real-world sparse multi-view system, showing its superior capability for photo-realistic free-viewpoint human rendering. For code and demo video, please refer to our project page: http://www.liuyebin.com/dbfield/dbfield.html.