 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEEG-Based Emergency Braking Intensity Prediction Using Blind Source Separation
Apr 20, 2026Electroencephalography (EEG) signals have been promising for long-term braking intensity prediction but are prone to various artifacts that limit their reliability. Here, we propose a novel framework that models EEG signals as mixtures of independent blind sources and identifies those strongly correlated with braking action. Our method employs independent component analysis to decompose EEG into different components and combines time-frequency analysis with Pearson correlations to select braking-related components. Furthermore, we utilize hierarchical clustering to group braking-related components into two clusters, each characterized by a distinct spatial pattern. Additionally, these components exhibit trial-invariant temporal patterns and demonstrate stable and common neural signatures of the emergency braking process. Using power features from these components and historical braking data, we predict braking intensity at a 200 ms horizon. Evaluations on the open source dataset (O.D.) and human-in-the-loop simulation (H.S.) show that our method outperforms state-of-the-art approaches, achieving RMSE reductions of 8.0% (O.D.) and 23.8% (H.S.).
MagicMan: Generative Novel View Synthesis of Humans with 3D-Aware Diffusion and Iterative Refinement
Aug 26, 2024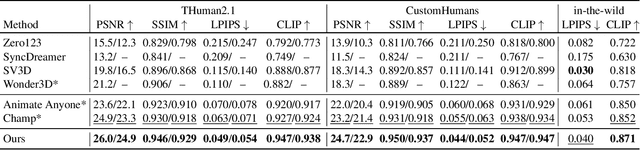
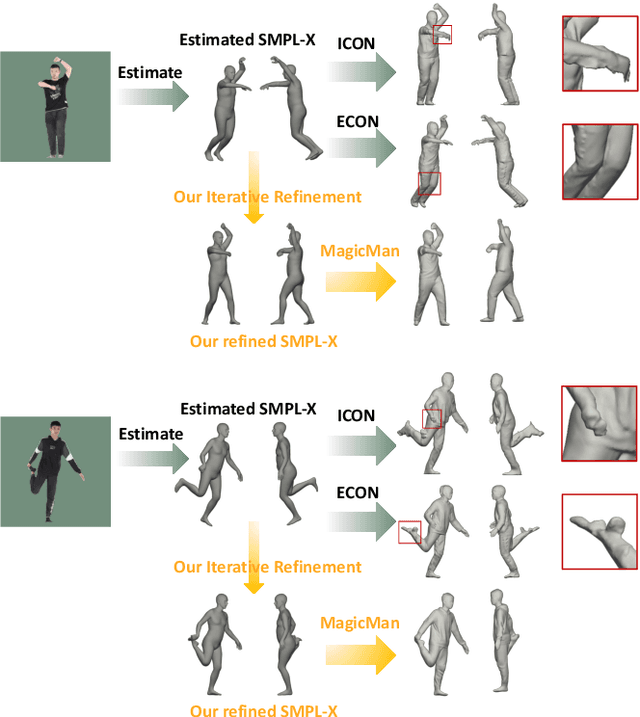
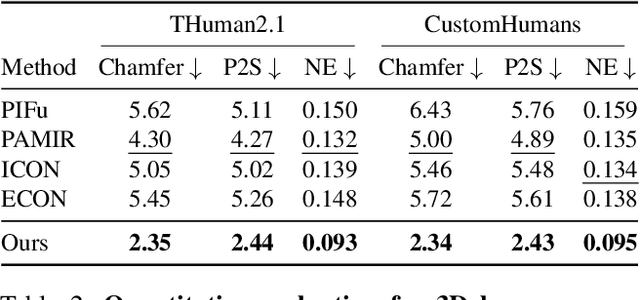
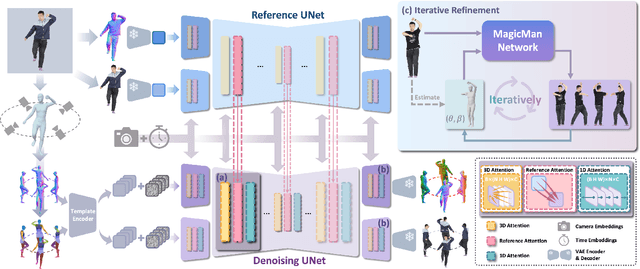
Existing works in single-image human reconstruction suffer from weak generalizability due to insufficient training data or 3D inconsistencies for a lack of comprehensive multi-view knowledge. In this paper, we introduce MagicMan, a human-specific multi-view diffusion model designed to generate high-quality novel view images from a single reference image. As its core, we leverage a pre-trained 2D diffusion model as the generative prior for generalizability, with the parametric SMPL-X model as the 3D body prior to promote 3D awareness. To tackle the critical challenge of maintaining consistency while achieving dense multi-view generation for improved 3D human reconstruction, we first introduce hybrid multi-view attention to facilitate both efficient and thorough information interchange across different views. Additionally, we present a geometry-aware dual branch to perform concurrent generation in both RGB and normal domains, further enhancing consistency via geometry cues. Last but not least, to address ill-shaped issues arising from inaccurate SMPL-X estimation that conflicts with the reference image, we propose a novel iterative refinement strategy, which progressively optimizes SMPL-X accuracy while enhancing the quality and consistency of the generated multi-views. Extensive experimental results demonstrate that our method significantly outperforms existing approaches in both novel view synthesis and subsequent 3D human reconstruction tasks.
100 Drivers, 2200 km: A Natural Dataset of Driving Style toward Human-centered Intelligent Driving Systems
Jun 12, 2024



Effective driving style analysis is critical to developing human-centered intelligent driving systems that consider drivers' preferences. However, the approaches and conclusions of most related studies are diverse and inconsistent because no unified datasets tagged with driving styles exist as a reliable benchmark. The absence of explicit driving style labels makes verifying different approaches and algorithms difficult. This paper provides a new benchmark by constructing a natural dataset of Driving Style (100-DrivingStyle) tagged with the subjective evaluation of 100 drivers' driving styles. In this dataset, the subjective quantification of each driver's driving style is from themselves and an expert according to the Likert-scale questionnaire. The testing routes are selected to cover various driving scenarios, including highways, urban, highway ramps, and signalized traffic. The collected driving data consists of lateral and longitudinal manipulation information, including steering angle, steering speed, lateral acceleration, throttle position, throttle rate, brake pressure, etc. This dataset is the first to provide detailed manipulation data with driving-style tags, and we demonstrate its benchmark function using six classifiers. The 100-DrivingStyle dataset is available via https://github.com/chaopengzhang/100-DrivingStyle-Dataset
Mani-GS: Gaussian Splatting Manipulation with Triangular Mesh
May 28, 2024Neural 3D representations such as Neural Radiance Fields (NeRF), excel at producing photo-realistic rendering results but lack the flexibility for manipulation and editing which is crucial for content creation. Previous works have attempted to address this issue by deforming a NeRF in canonical space or manipulating the radiance field based on an explicit mesh. However, manipulating NeRF is not highly controllable and requires a long training and inference time. With the emergence of 3D Gaussian Splatting (3DGS), extremely high-fidelity novel view synthesis can be achieved using an explicit point-based 3D representation with much faster training and rendering speed. However, there is still a lack of effective means to manipulate 3DGS freely while maintaining rendering quality. In this work, we aim to tackle the challenge of achieving manipulable photo-realistic rendering. We propose to utilize a triangular mesh to manipulate 3DGS directly with self-adaptation. This approach reduces the need to design various algorithms for different types of Gaussian manipulation. By utilizing a triangle shape-aware Gaussian binding and adapting method, we can achieve 3DGS manipulation and preserve high-fidelity rendering after manipulation. Our approach is capable of handling large deformations, local manipulations, and soft body simulations while keeping high-quality rendering. Furthermore, we demonstrate that our method is also effective with inaccurate meshes extracted from 3DGS. Experiments conducted demonstrate the effectiveness of our method and its superiority over baseline approaches.
UV Gaussians: Joint Learning of Mesh Deformation and Gaussian Textures for Human Avatar Modeling
Mar 18, 2024



Reconstructing photo-realistic drivable human avatars from multi-view image sequences has been a popular and challenging topic in the field of computer vision and graphics. While existing NeRF-based methods can achieve high-quality novel view rendering of human models, both training and inference processes are time-consuming. Recent approaches have utilized 3D Gaussians to represent the human body, enabling faster training and rendering. However, they undermine the importance of the mesh guidance and directly predict Gaussians in 3D space with coarse mesh guidance. This hinders the learning procedure of the Gaussians and tends to produce blurry textures. Therefore, we propose UV Gaussians, which models the 3D human body by jointly learning mesh deformations and 2D UV-space Gaussian textures. We utilize the embedding of UV map to learn Gaussian textures in 2D space, leveraging the capabilities of powerful 2D networks to extract features. Additionally, through an independent Mesh network, we optimize pose-dependent geometric deformations, thereby guiding Gaussian rendering and significantly enhancing rendering quality. We collect and process a new dataset of human motion, which includes multi-view images, scanned models, parametric model registration, and corresponding texture maps. Experimental results demonstrate that our method achieves state-of-the-art synthesis of novel view and novel pose. The code and data will be made available on the homepage https://alex-jyj.github.io/UV-Gaussians/ once the paper is accepted.
ConTex-Human: Free-View Rendering of Human from a Single Image with Texture-Consistent Synthesis
Nov 28, 2023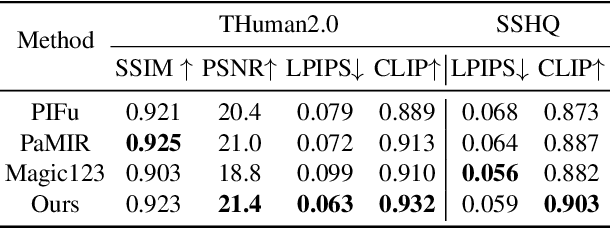

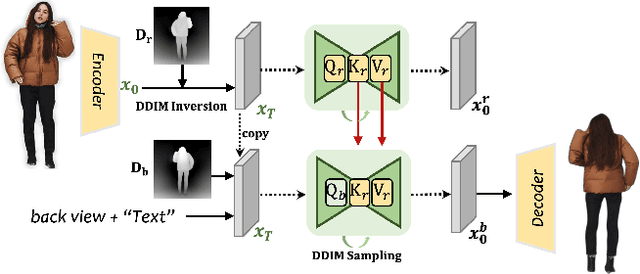
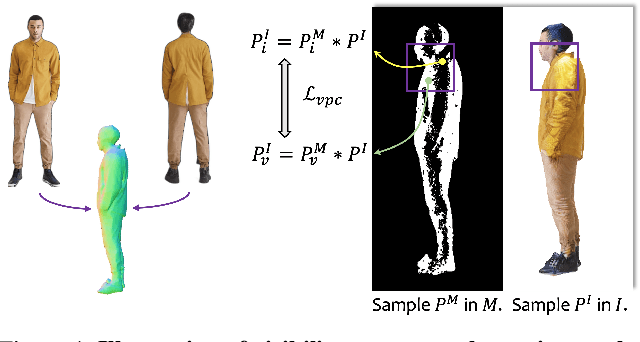
In this work, we propose a method to address the challenge of rendering a 3D human from a single image in a free-view manner. Some existing approaches could achieve this by using generalizable pixel-aligned implicit fields to reconstruct a textured mesh of a human or by employing a 2D diffusion model as guidance with the Score Distillation Sampling (SDS) method, to lift the 2D image into 3D space. However, a generalizable implicit field often results in an over-smooth texture field, while the SDS method tends to lead to a texture-inconsistent novel view with the input image. In this paper, we introduce a texture-consistent back view synthesis module that could transfer the reference image content to the back view through depth and text-guided attention injection. Moreover, to alleviate the color distortion that occurs in the side region, we propose a visibility-aware patch consistency regularization for texture mapping and refinement combined with the synthesized back view texture. With the above techniques, we could achieve high-fidelity and texture-consistent human rendering from a single image. Experiments conducted on both real and synthetic data demonstrate the effectiveness of our method and show that our approach outperforms previous baseline methods.
Shareable Driving Style Learning and Analysis with a Hierarchical Latent Model
Oct 24, 2023Driving style is usually used to characterize driving behavior for a driver or a group of drivers. However, it remains unclear how one individual's driving style shares certain common grounds with other drivers. Our insight is that driving behavior is a sequence of responses to the weighted mixture of latent driving styles that are shareable within and between individuals. To this end, this paper develops a hierarchical latent model to learn the relationship between driving behavior and driving styles. We first propose a fragment-based approach to represent complex sequential driving behavior, allowing for sufficiently representing driving behavior in a low-dimension feature space. Then, we provide an analytical formulation for the interaction of driving behavior and shareable driving style with a hierarchical latent model by introducing the mechanism of Dirichlet allocation. Our developed model is finally validated and verified with 100 drivers in naturalistic driving settings with urban and highways. Experimental results reveal that individuals share driving styles within and between them. We also analyzed the influence of personalities (e.g., age, gender, and driving experience) on driving styles and found that a naturally aggressive driver would not always keep driving aggressively (i.e., could behave calmly sometimes) but with a higher proportion of aggressiveness than other types of drivers.
Non-local Recurrent Neural Memory for Supervised Sequence Modeling
Aug 26, 2019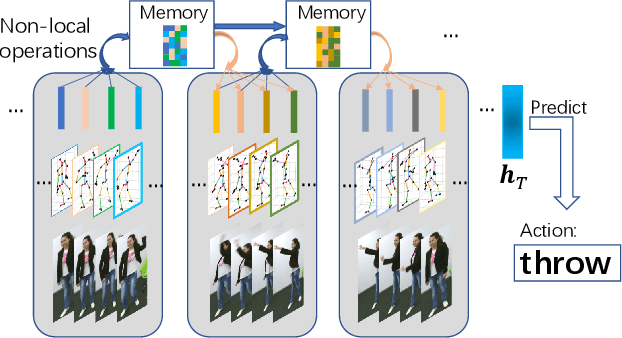
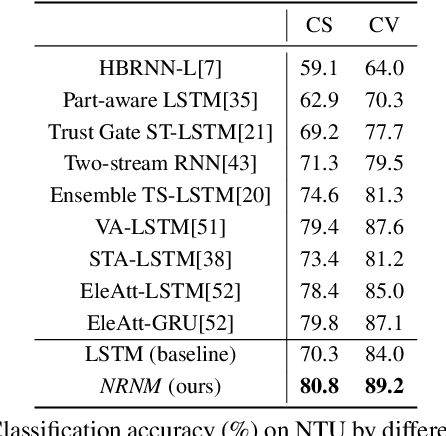
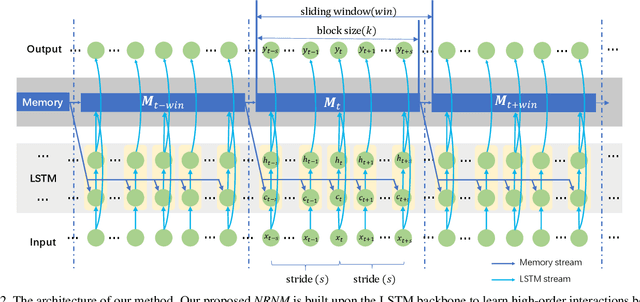
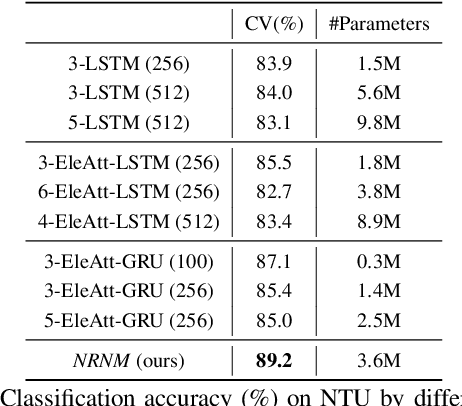
Typical methods for supervised sequence modeling are built upon the recurrent neural networks to capture temporal dependencies. One potential limitation of these methods is that they only model explicitly information interactions between adjacent time steps in a sequence, hence the high-order interactions between nonadjacent time steps are not fully exploited. It greatly limits the capability of modeling the long-range temporal dependencies since one-order interactions cannot be maintained for a long term due to information dilution and gradient vanishing. To tackle this limitation, we propose the Non-local Recurrent Neural Memory (NRNM) for supervised sequence modeling, which performs non-local operations to learn full-order interactions within a sliding temporal block and models global interactions between blocks in a gated recurrent manner. Consequently, our model is able to capture the long-range dependencies. Besides, the latent high-level features contained in high-order interactions can be distilled by our model. We demonstrate the merits of our NRNM on two different tasks: action recognition and sentiment analysis.