 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConTex-Human: Free-View Rendering of Human from a Single Image with Texture-Consistent Synthesis
Paper and Code
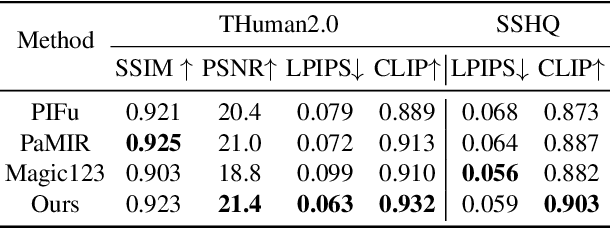

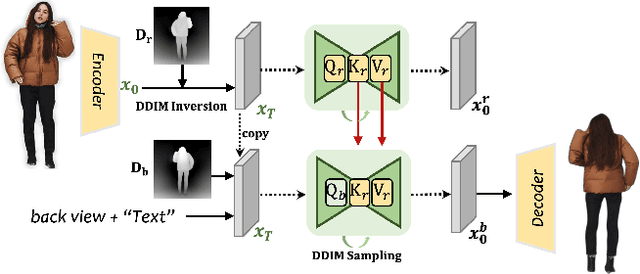
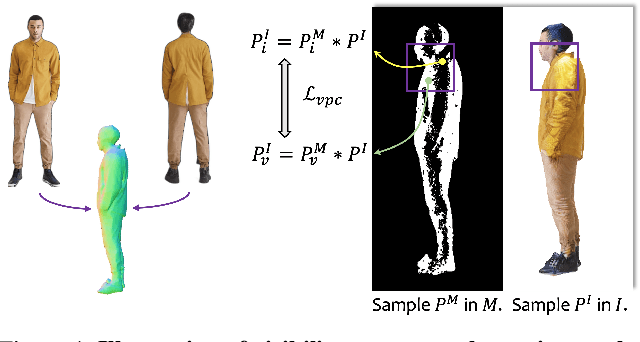
In this work, we propose a method to address the challenge of rendering a 3D human from a single image in a free-view manner. Some existing approaches could achieve this by using generalizable pixel-aligned implicit fields to reconstruct a textured mesh of a human or by employing a 2D diffusion model as guidance with the Score Distillation Sampling (SDS) method, to lift the 2D image into 3D space. However, a generalizable implicit field often results in an over-smooth texture field, while the SDS method tends to lead to a texture-inconsistent novel view with the input image. In this paper, we introduce a texture-consistent back view synthesis module that could transfer the reference image content to the back view through depth and text-guided attention injection. Moreover, to alleviate the color distortion that occurs in the side region, we propose a visibility-aware patch consistency regularization for texture mapping and refinement combined with the synthesized back view texture. With the above techniques, we could achieve high-fidelity and texture-consistent human rendering from a single image. Experiments conducted on both real and synthetic data demonstrate the effectiveness of our method and show that our approach outperforms previous baseline methods.