 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTopoMesh: High-Fidelity Mesh Autoencoding via Topological Unification
Mar 25, 2026The dominant paradigm for high-fidelity 3D generation relies on a VAE-Diffusion pipeline, where the VAE's reconstruction capability sets a firm upper bound on generation quality. A fundamental challenge limiting existing VAEs is the representation mismatch between ground-truth meshes and network predictions: GT meshes have arbitrary, variable topology, while VAEs typically predict fixed-structure implicit fields (\eg, SDF on regular grids). This inherent misalignment prevents establishing explicit mesh-level correspondences, forcing prior work to rely on indirect supervision signals such as SDF or rendering losses. Consequently, fine geometric details, particularly sharp features, are poorly preserved during reconstruction. To address this, we introduce TopoMesh, a sparse voxel-based VAE that unifies both GT and predicted meshes under a shared Dual Marching Cubes (DMC) topological framework. Specifically, we convert arbitrary input meshes into DMC-compliant representations via a remeshing algorithm that preserves sharp edges using an L$\infty$ distance metric. Our decoder outputs meshes in the same DMC format, ensuring that both predicted and target meshes share identical topological structures. This establishes explicit correspondences at the vertex and face level, allowing us to derive explicit mesh-level supervision signals for topology, vertex positions, and face orientations with clear gradients. Our sparse VAE architecture employs this unified framework and is trained with Teacher Forcing and progressive resolution training for stable and efficient convergence. Extensive experiments demonstrate that TopoMesh significantly outperforms existing VAEs in reconstruction fidelity, achieving superior preservation of sharp features and geometric details.
UCM: Unifying Camera Control and Memory with Time-aware Positional Encoding Warping for World Models
Feb 26, 2026World models based on video generation demonstrate remarkable potential for simulating interactive environments but face persistent difficulties in two key areas: maintaining long-term content consistency when scenes are revisited and enabling precise camera control from user-provided inputs. Existing methods based on explicit 3D reconstruction often compromise flexibility in unbounded scenarios and fine-grained structures. Alternative methods rely directly on previously generated frames without establishing explicit spatial correspondence, thereby constraining controllability and consistency. To address these limitations, we present UCM, a novel framework that unifies long-term memory and precise camera control via a time-aware positional encoding warping mechanism. To reduce computational overhead, we design an efficient dual-stream diffusion transformer for high-fidelity generation. Moreover, we introduce a scalable data curation strategy utilizing point-cloud-based rendering to simulate scene revisiting, facilitating training on over 500K monocular videos. Extensive experiments on real-world and synthetic benchmarks demonstrate that UCM significantly outperforms state-of-the-art methods in long-term scene consistency, while also achieving precise camera controllability in high-fidelity video generation.
DepthSync: Diffusion Guidance-Based Depth Synchronization for Scale- and Geometry-Consistent Video Depth Estimation
Jul 02, 2025
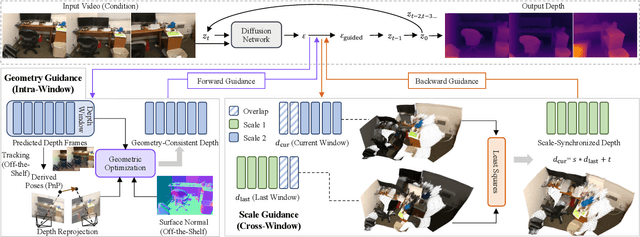

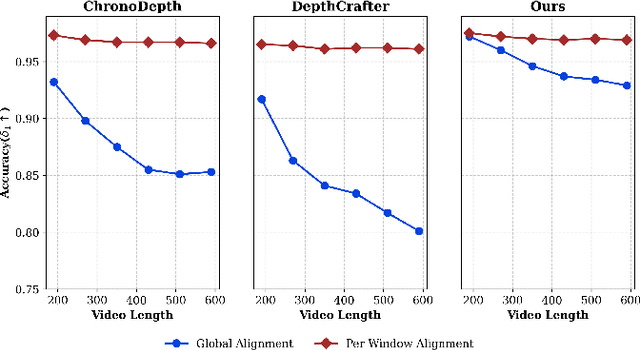
Diffusion-based video depth estimation methods have achieved remarkable success with strong generalization ability. However, predicting depth for long videos remains challenging. Existing methods typically split videos into overlapping sliding windows, leading to accumulated scale discrepancies across different windows, particularly as the number of windows increases. Additionally, these methods rely solely on 2D diffusion priors, overlooking the inherent 3D geometric structure of video depths, which results in geometrically inconsistent predictions. In this paper, we propose DepthSync, a novel, training-free framework using diffusion guidance to achieve scale- and geometry-consistent depth predictions for long videos. Specifically, we introduce scale guidance to synchronize the depth scale across windows and geometry guidance to enforce geometric alignment within windows based on the inherent 3D constraints in video depths. These two terms work synergistically, steering the denoising process toward consistent depth predictions. Experiments on various datasets validate the effectiveness of our method in producing depth estimates with improved scale and geometry consistency, particularly for long videos.
GeometryCrafter: Consistent Geometry Estimation for Open-world Videos with Diffusion Priors
Apr 01, 2025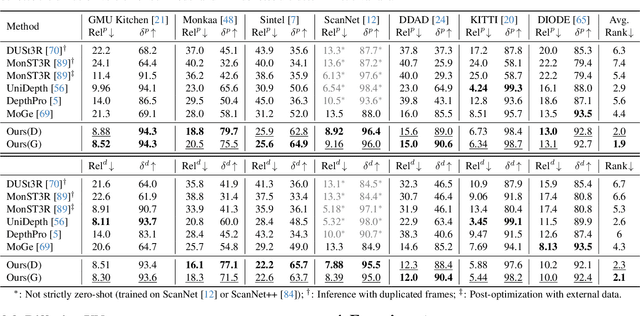
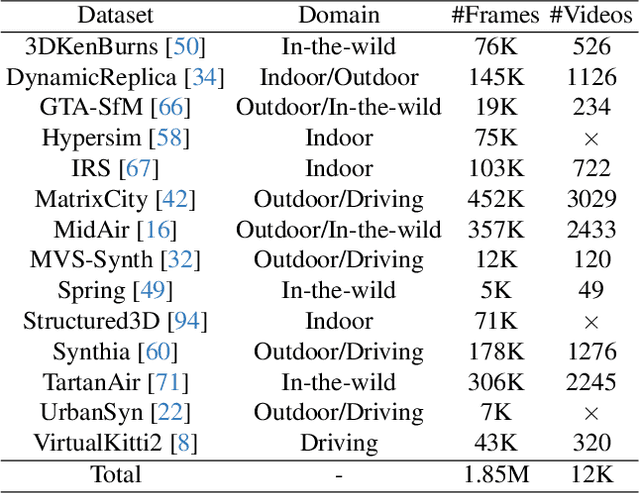


Despite remarkable advancements in video depth estimation, existing methods exhibit inherent limitations in achieving geometric fidelity through the affine-invariant predictions, limiting their applicability in reconstruction and other metrically grounded downstream tasks. We propose GeometryCrafter, a novel framework that recovers high-fidelity point map sequences with temporal coherence from open-world videos, enabling accurate 3D/4D reconstruction, camera parameter estimation, and other depth-based applications. At the core of our approach lies a point map Variational Autoencoder (VAE) that learns a latent space agnostic to video latent distributions for effective point map encoding and decoding. Leveraging the VAE, we train a video diffusion model to model the distribution of point map sequences conditioned on the input videos. Extensive evaluations on diverse datasets demonstrate that GeometryCrafter achieves state-of-the-art 3D accuracy, temporal consistency, and generalization capability.
Splatter-360: Generalizable 360$^{\circ}$ Gaussian Splatting for Wide-baseline Panoramic Images
Dec 09, 2024Wide-baseline panoramic images are frequently used in applications like VR and simulations to minimize capturing labor costs and storage needs. However, synthesizing novel views from these panoramic images in real time remains a significant challenge, especially due to panoramic imagery's high resolution and inherent distortions. Although existing 3D Gaussian splatting (3DGS) methods can produce photo-realistic views under narrow baselines, they often overfit the training views when dealing with wide-baseline panoramic images due to the difficulty in learning precise geometry from sparse 360$^{\circ}$ views. This paper presents \textit{Splatter-360}, a novel end-to-end generalizable 3DGS framework designed to handle wide-baseline panoramic images. Unlike previous approaches, \textit{Splatter-360} performs multi-view matching directly in the spherical domain by constructing a spherical cost volume through a spherical sweep algorithm, enhancing the network's depth perception and geometry estimation. Additionally, we introduce a 3D-aware bi-projection encoder to mitigate the distortions inherent in panoramic images and integrate cross-view attention to improve feature interactions across multiple viewpoints. This enables robust 3D-aware feature representations and real-time rendering capabilities. Experimental results on the HM3D~\cite{hm3d} and Replica~\cite{replica} demonstrate that \textit{Splatter-360} significantly outperforms state-of-the-art NeRF and 3DGS methods (e.g., PanoGRF, MVSplat, DepthSplat, and HiSplat) in both synthesis quality and generalization performance for wide-baseline panoramic images. Code and trained models are available at \url{https://3d-aigc.github.io/Splatter-360/}.
DiffPano: Scalable and Consistent Text to Panorama Generation with Spherical Epipolar-Aware Diffusion
Oct 31, 2024



Diffusion-based methods have achieved remarkable achievements in 2D image or 3D object generation, however, the generation of 3D scenes and even $360^{\circ}$ images remains constrained, due to the limited number of scene datasets, the complexity of 3D scenes themselves, and the difficulty of generating consistent multi-view images. To address these issues, we first establish a large-scale panoramic video-text dataset containing millions of consecutive panoramic keyframes with corresponding panoramic depths, camera poses, and text descriptions. Then, we propose a novel text-driven panoramic generation framework, termed DiffPano, to achieve scalable, consistent, and diverse panoramic scene generation. Specifically, benefiting from the powerful generative capabilities of stable diffusion, we fine-tune a single-view text-to-panorama diffusion model with LoRA on the established panoramic video-text dataset. We further design a spherical epipolar-aware multi-view diffusion model to ensure the multi-view consistency of the generated panoramic images. Extensive experiments demonstrate that DiffPano can generate scalable, consistent, and diverse panoramic images with given unseen text descriptions and camera poses.
3D Gaussian Editing with A Single Image
Aug 14, 2024



The modeling and manipulation of 3D scenes captured from the real world are pivotal in various applications, attracting growing research interest. While previous works on editing have achieved interesting results through manipulating 3D meshes, they often require accurately reconstructed meshes to perform editing, which limits their application in 3D content generation. To address this gap, we introduce a novel single-image-driven 3D scene editing approach based on 3D Gaussian Splatting, enabling intuitive manipulation via directly editing the content on a 2D image plane. Our method learns to optimize the 3D Gaussians to align with an edited version of the image rendered from a user-specified viewpoint of the original scene. To capture long-range object deformation, we introduce positional loss into the optimization process of 3D Gaussian Splatting and enable gradient propagation through reparameterization. To handle occluded 3D Gaussians when rendering from the specified viewpoint, we build an anchor-based structure and employ a coarse-to-fine optimization strategy capable of handling long-range deformation while maintaining structural stability. Furthermore, we design a novel masking strategy to adaptively identify non-rigid deformation regions for fine-scale modeling. Extensive experiments show the effectiveness of our method in handling geometric details, long-range, and non-rigid deformation, demonstrating superior editing flexibility and quality compared to previous approaches.
MeGA: Hybrid Mesh-Gaussian Head Avatar for High-Fidelity Rendering and Head Editing
Apr 29, 2024Creating high-fidelity head avatars from multi-view videos is a core issue for many AR/VR applications. However, existing methods usually struggle to obtain high-quality renderings for all different head components simultaneously since they use one single representation to model components with drastically different characteristics (e.g., skin vs. hair). In this paper, we propose a Hybrid Mesh-Gaussian Head Avatar (MeGA) that models different head components with more suitable representations. Specifically, we select an enhanced FLAME mesh as our facial representation and predict a UV displacement map to provide per-vertex offsets for improved personalized geometric details. To achieve photorealistic renderings, we obtain facial colors using deferred neural rendering and disentangle neural textures into three meaningful parts. For hair modeling, we first build a static canonical hair using 3D Gaussian Splatting. A rigid transformation and an MLP-based deformation field are further applied to handle complex dynamic expressions. Combined with our occlusion-aware blending, MeGA generates higher-fidelity renderings for the whole head and naturally supports more downstream tasks. Experiments on the NeRSemble dataset demonstrate the effectiveness of our designs, outperforming previous state-of-the-art methods and supporting various editing functionalities, including hairstyle alteration and texture editing.
Texture-GS: Disentangling the Geometry and Texture for 3D Gaussian Splatting Editing
Mar 15, 2024
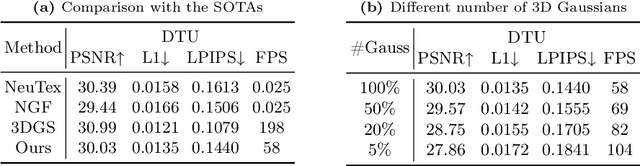
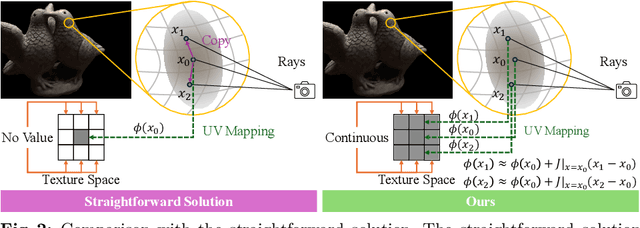
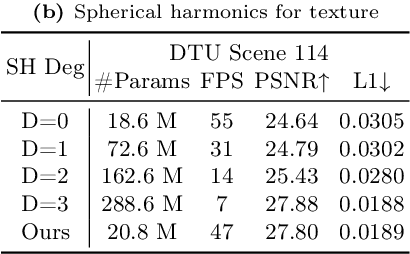
3D Gaussian splatting, emerging as a groundbreaking approach, has drawn increasing attention for its capabilities of high-fidelity reconstruction and real-time rendering. However, it couples the appearance and geometry of the scene within the Gaussian attributes, which hinders the flexibility of editing operations, such as texture swapping. To address this issue, we propose a novel approach, namely Texture-GS, to disentangle the appearance from the geometry by representing it as a 2D texture mapped onto the 3D surface, thereby facilitating appearance editing. Technically, the disentanglement is achieved by our proposed texture mapping module, which consists of a UV mapping MLP to learn the UV coordinates for the 3D Gaussian centers, a local Taylor expansion of the MLP to efficiently approximate the UV coordinates for the ray-Gaussian intersections, and a learnable texture to capture the fine-grained appearance. Extensive experiments on the DTU dataset demonstrate that our method not only facilitates high-fidelity appearance editing but also achieves real-time rendering on consumer-level devices, e.g. a single RTX 2080 Ti GPU.
MAL: Motion-Aware Loss with Temporal and Distillation Hints for Self-Supervised Depth Estimation
Feb 18, 2024
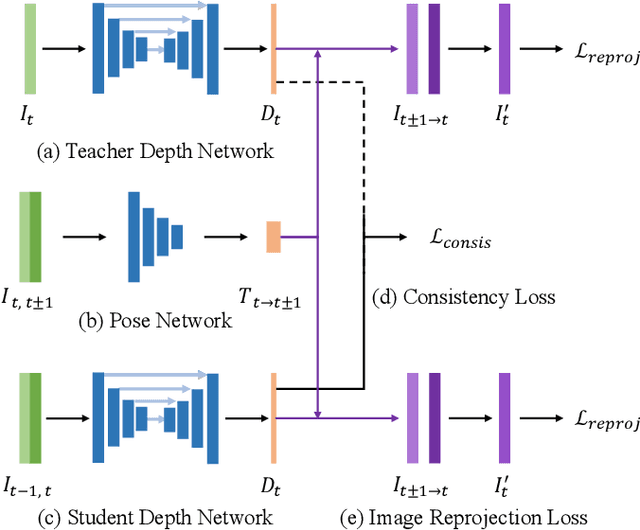

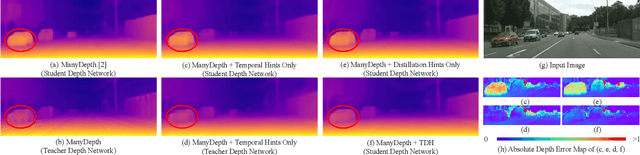
Depth perception is crucial for a wide range of robotic applications. Multi-frame self-supervised depth estimation methods have gained research interest due to their ability to leverage large-scale, unlabeled real-world data. However, the self-supervised methods often rely on the assumption of a static scene and their performance tends to degrade in dynamic environments. To address this issue, we present Motion-Aware Loss, which leverages the temporal relation among consecutive input frames and a novel distillation scheme between the teacher and student networks in the multi-frame self-supervised depth estimation methods. Specifically, we associate the spatial locations of moving objects with the temporal order of input frames to eliminate errors induced by object motion. Meanwhile, we enhance the original distillation scheme in multi-frame methods to better exploit the knowledge from a teacher network. MAL is a novel, plug-and-play module designed for seamless integration into multi-frame self-supervised monocular depth estimation methods. Adding MAL into previous state-of-the-art methods leads to a reduction in depth estimation errors by up to 4.2% and 10.8% on KITTI and CityScapes benchmarks, respectively.