 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransBridge: Boost 3D Object Detection by Scene-Level Completion with Transformer Decoder
Dec 12, 2025



3D object detection is essential in autonomous driving, providing vital information about moving objects and obstacles. Detecting objects in distant regions with only a few LiDAR points is still a challenge, and numerous strategies have been developed to address point cloud sparsity through densification.This paper presents a joint completion and detection framework that improves the detection feature in sparse areas while maintaining costs unchanged. Specifically, we propose TransBridge, a novel transformer-based up-sampling block that fuses the features from the detection and completion networks.The detection network can benefit from acquiring implicit completion features derived from the completion network. Additionally, we design the Dynamic-Static Reconstruction (DSRecon) module to produce dense LiDAR data for the completion network, meeting the requirement for dense point cloud ground truth.Furthermore, we employ the transformer mechanism to establish connections between channels and spatial relations, resulting in a high-resolution feature map used for completion purposes.Extensive experiments on the nuScenes and Waymo datasets demonstrate the effectiveness of the proposed framework.The results show that our framework consistently improves end-to-end 3D object detection, with the mean average precision (mAP) ranging from 0.7 to 1.5 across multiple methods, indicating its generalization ability. For the two-stage detection framework, it also boosts the mAP up to 5.78 points.
iDiT-HOI: Inpainting-based Hand Object Interaction Reenactment via Video Diffusion Transformer
Jun 15, 2025Digital human video generation is gaining traction in fields like education and e-commerce, driven by advancements in head-body animation and lip-syncing technologies. However, realistic Hand-Object Interaction (HOI) - the complex dynamics between human hands and objects - continues to pose challenges. Generating natural and believable HOI reenactments is difficult due to issues such as occlusion between hands and objects, variations in object shapes and orientations, and the necessity for precise physical interactions, and importantly, the ability to generalize to unseen humans and objects. This paper presents a novel framework iDiT-HOI that enables in-the-wild HOI reenactment generation. Specifically, we propose a unified inpainting-based token process method, called Inp-TPU, with a two-stage video diffusion transformer (DiT) model. The first stage generates a key frame by inserting the designated object into the hand region, providing a reference for subsequent frames. The second stage ensures temporal coherence and fluidity in hand-object interactions. The key contribution of our method is to reuse the pretrained model's context perception capabilities without introducing additional parameters, enabling strong generalization to unseen objects and scenarios, and our proposed paradigm naturally supports long video generation. Comprehensive evaluations demonstrate that our approach outperforms existing methods, particularly in challenging real-world scenes, offering enhanced realism and more seamless hand-object interactions.
CMD: Constraining Multimodal Distribution for Domain Adaptation in Stereo Matching
Apr 30, 2025Recently, learning-based stereo matching methods have achieved great improvement in public benchmarks, where soft argmin and smooth L1 loss play a core contribution to their success. However, in unsupervised domain adaptation scenarios, we observe that these two operations often yield multimodal disparity probability distributions in target domains, resulting in degraded generalization. In this paper, we propose a novel approach, Constrain Multi-modal Distribution (CMD), to address this issue. Specifically, we introduce \textit{uncertainty-regularized minimization} and \textit{anisotropic soft argmin} to encourage the network to produce predominantly unimodal disparity distributions in the target domain, thereby improving prediction accuracy. Experimentally, we apply the proposed method to multiple representative stereo-matching networks and conduct domain adaptation from synthetic data to unlabeled real-world scenes. Results consistently demonstrate improved generalization in both top-performing and domain-adaptable stereo-matching models. The code for CMD will be available at: \href{https://github.com/gallenszl/CMD}{https://github.com/gallenszl/CMD}.
DriVerse: Navigation World Model for Driving Simulation via Multimodal Trajectory Prompting and Motion Alignment
Apr 22, 2025



This paper presents DriVerse, a generative model for simulating navigation-driven driving scenes from a single image and a future trajectory. Previous autonomous driving world models either directly feed the trajectory or discrete control signals into the generation pipeline, leading to poor alignment between the control inputs and the implicit features of the 2D base generative model, which results in low-fidelity video outputs. Some methods use coarse textual commands or discrete vehicle control signals, which lack the precision to guide fine-grained, trajectory-specific video generation, making them unsuitable for evaluating actual autonomous driving algorithms. DriVerse introduces explicit trajectory guidance in two complementary forms: it tokenizes trajectories into textual prompts using a predefined trend vocabulary for seamless language integration, and converts 3D trajectories into 2D spatial motion priors to enhance control over static content within the driving scene. To better handle dynamic objects, we further introduce a lightweight motion alignment module, which focuses on the inter-frame consistency of dynamic pixels, significantly enhancing the temporal coherence of moving elements over long sequences. With minimal training and no need for additional data, DriVerse outperforms specialized models on future video generation tasks across both the nuScenes and Waymo datasets. The code and models will be released to the public.
Para-Lane: Multi-Lane Dataset Registering Parallel Scans for Benchmarking Novel View Synthesis
Feb 21, 2025To evaluate end-to-end autonomous driving systems, a simulation environment based on Novel View Synthesis (NVS) techniques is essential, which synthesizes photo-realistic images and point clouds from previously recorded sequences under new vehicle poses, particularly in cross-lane scenarios. Therefore, the development of a multi-lane dataset and benchmark is necessary. While recent synthetic scene-based NVS datasets have been prepared for cross-lane benchmarking, they still lack the realism of captured images and point clouds. To further assess the performance of existing methods based on NeRF and 3DGS, we present the first multi-lane dataset registering parallel scans specifically for novel driving view synthesis dataset derived from real-world scans, comprising 25 groups of associated sequences, including 16,000 front-view images, 64,000 surround-view images, and 16,000 LiDAR frames. All frames are labeled to differentiate moving objects from static elements. Using this dataset, we evaluate the performance of existing approaches in various testing scenarios at different lanes and distances. Additionally, our method provides the solution for solving and assessing the quality of multi-sensor poses for multi-modal data alignment for curating such a dataset in real-world. We plan to continually add new sequences to test the generalization of existing methods across different scenarios. The dataset is released publicly at the project page: https://nizqleo.github.io/paralane-dataset/.
Splatter-360: Generalizable 360$^{\circ}$ Gaussian Splatting for Wide-baseline Panoramic Images
Dec 09, 2024Wide-baseline panoramic images are frequently used in applications like VR and simulations to minimize capturing labor costs and storage needs. However, synthesizing novel views from these panoramic images in real time remains a significant challenge, especially due to panoramic imagery's high resolution and inherent distortions. Although existing 3D Gaussian splatting (3DGS) methods can produce photo-realistic views under narrow baselines, they often overfit the training views when dealing with wide-baseline panoramic images due to the difficulty in learning precise geometry from sparse 360$^{\circ}$ views. This paper presents \textit{Splatter-360}, a novel end-to-end generalizable 3DGS framework designed to handle wide-baseline panoramic images. Unlike previous approaches, \textit{Splatter-360} performs multi-view matching directly in the spherical domain by constructing a spherical cost volume through a spherical sweep algorithm, enhancing the network's depth perception and geometry estimation. Additionally, we introduce a 3D-aware bi-projection encoder to mitigate the distortions inherent in panoramic images and integrate cross-view attention to improve feature interactions across multiple viewpoints. This enables robust 3D-aware feature representations and real-time rendering capabilities. Experimental results on the HM3D~\cite{hm3d} and Replica~\cite{replica} demonstrate that \textit{Splatter-360} significantly outperforms state-of-the-art NeRF and 3DGS methods (e.g., PanoGRF, MVSplat, DepthSplat, and HiSplat) in both synthesis quality and generalization performance for wide-baseline panoramic images. Code and trained models are available at \url{https://3d-aigc.github.io/Splatter-360/}.
TexGaussian: Generating High-quality PBR Material via Octree-based 3D Gaussian Splatting
Nov 29, 2024
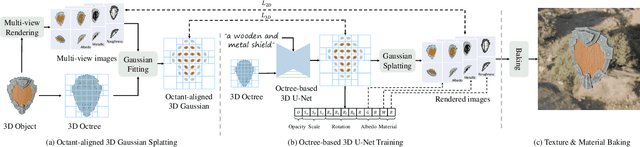


Physically Based Rendering (PBR) materials play a crucial role in modern graphics, enabling photorealistic rendering across diverse environment maps. Developing an effective and efficient algorithm that is capable of automatically generating high-quality PBR materials rather than RGB texture for 3D meshes can significantly streamline the 3D content creation. Most existing methods leverage pre-trained 2D diffusion models for multi-view image synthesis, which often leads to severe inconsistency between the generated textures and input 3D meshes. This paper presents TexGaussian, a novel method that uses octant-aligned 3D Gaussian Splatting for rapid PBR material generation. Specifically, we place each 3D Gaussian on the finest leaf node of the octree built from the input 3D mesh to render the multiview images not only for the albedo map but also for roughness and metallic. Moreover, our model is trained in a regression manner instead of diffusion denoising, capable of generating the PBR material for a 3D mesh in a single feed-forward process. Extensive experiments on publicly available benchmarks demonstrate that our method synthesizes more visually pleasing PBR materials and runs faster than previous methods in both unconditional and text-conditional scenarios, which exhibit better consistency with the given geometry. Our code and trained models are available at https://3d-aigc.github.io/TexGaussian.
DGTR: Distributed Gaussian Turbo-Reconstruction for Sparse-View Vast Scenes
Nov 20, 2024
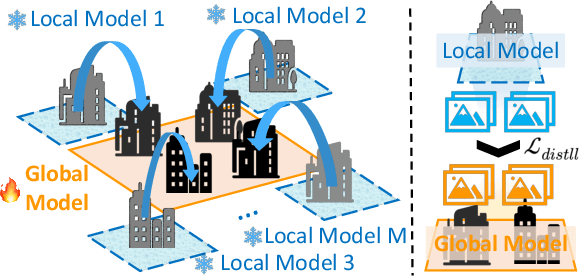


Novel-view synthesis (NVS) approaches play a critical role in vast scene reconstruction. However, these methods rely heavily on dense image inputs and prolonged training times, making them unsuitable where computational resources are limited. Additionally, few-shot methods often struggle with poor reconstruction quality in vast environments. This paper presents DGTR, a novel distributed framework for efficient Gaussian reconstruction for sparse-view vast scenes. Our approach divides the scene into regions, processed independently by drones with sparse image inputs. Using a feed-forward Gaussian model, we predict high-quality Gaussian primitives, followed by a global alignment algorithm to ensure geometric consistency. Synthetic views and depth priors are incorporated to further enhance training, while a distillation-based model aggregation mechanism enables efficient reconstruction. Our method achieves high-quality large-scale scene reconstruction and novel-view synthesis in significantly reduced training times, outperforming existing approaches in both speed and scalability. We demonstrate the effectiveness of our framework on vast aerial scenes, achieving high-quality results within minutes. Code will released on our [https://3d-aigc.github.io/DGTR].
HERO-SLAM: Hybrid Enhanced Robust Optimization of Neural SLAM
Jul 26, 2024Simultaneous Localization and Mapping (SLAM) is a fundamental task in robotics, driving numerous applications such as autonomous driving and virtual reality. Recent progress on neural implicit SLAM has shown encouraging and impressive results. However, the robustness of neural SLAM, particularly in challenging or data-limited situations, remains an unresolved issue. This paper presents HERO-SLAM, a Hybrid Enhanced Robust Optimization method for neural SLAM, which combines the benefits of neural implicit field and feature-metric optimization. This hybrid method optimizes a multi-resolution implicit field and enhances robustness in challenging environments with sudden viewpoint changes or sparse data collection. Our comprehensive experimental results on benchmarking datasets validate the effectiveness of our hybrid approach, demonstrating its superior performance over existing implicit field-based methods in challenging scenarios. HERO-SLAM provides a new pathway to enhance the stability, performance, and applicability of neural SLAM in real-world scenarios. Code is available on the project page: https://hero-slam.github.io.
Surfel-based Gaussian Inverse Rendering for Fast and Relightable Dynamic Human Reconstruction from Monocular Video
Jul 23, 2024



Efficient and accurate reconstruction of a relightable, dynamic clothed human avatar from a monocular video is crucial for the entertainment industry. This paper introduces the Surfel-based Gaussian Inverse Avatar (SGIA) method, which introduces efficient training and rendering for relightable dynamic human reconstruction. SGIA advances previous Gaussian Avatar methods by comprehensively modeling Physically-Based Rendering (PBR) properties for clothed human avatars, allowing for the manipulation of avatars into novel poses under diverse lighting conditions. Specifically, our approach integrates pre-integration and image-based lighting for fast light calculations that surpass the performance of existing implicit-based techniques. To address challenges related to material lighting disentanglement and accurate geometry reconstruction, we propose an innovative occlusion approximation strategy and a progressive training approach. Extensive experiments demonstrate that SGIA not only achieves highly accurate physical properties but also significantly enhances the realistic relighting of dynamic human avatars, providing a substantial speed advantage. We exhibit more results in our project page: https://GS-IA.github.io.