 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCUPID: Pose-Grounded Generative 3D Reconstruction from a Single Image
Oct 23, 2025This work proposes a new generation-based 3D reconstruction method, named Cupid, that accurately infers the camera pose, 3D shape, and texture of an object from a single 2D image. Cupid casts 3D reconstruction as a conditional sampling process from a learned distribution of 3D objects, and it jointly generates voxels and pixel-voxel correspondences, enabling robust pose and shape estimation under a unified generative framework. By representing both input camera poses and 3D shape as a distribution in a shared 3D latent space, Cupid adopts a two-stage flow matching pipeline: (1) a coarse stage that produces initial 3D geometry with associated 2D projections for pose recovery; and (2) a refinement stage that integrates pose-aligned image features to enhance structural fidelity and appearance details. Extensive experiments demonstrate Cupid outperforms leading 3D reconstruction methods with an over 3 dB PSNR gain and an over 10% Chamfer Distance reduction, while matching monocular estimators on pose accuracy and delivering superior visual fidelity over baseline 3D generative models. For an immersive view of the 3D results generated by Cupid, please visit cupid3d.github.io.
Surfel-based Gaussian Inverse Rendering for Fast and Relightable Dynamic Human Reconstruction from Monocular Video
Jul 23, 2024



Efficient and accurate reconstruction of a relightable, dynamic clothed human avatar from a monocular video is crucial for the entertainment industry. This paper introduces the Surfel-based Gaussian Inverse Avatar (SGIA) method, which introduces efficient training and rendering for relightable dynamic human reconstruction. SGIA advances previous Gaussian Avatar methods by comprehensively modeling Physically-Based Rendering (PBR) properties for clothed human avatars, allowing for the manipulation of avatars into novel poses under diverse lighting conditions. Specifically, our approach integrates pre-integration and image-based lighting for fast light calculations that surpass the performance of existing implicit-based techniques. To address challenges related to material lighting disentanglement and accurate geometry reconstruction, we propose an innovative occlusion approximation strategy and a progressive training approach. Extensive experiments demonstrate that SGIA not only achieves highly accurate physical properties but also significantly enhances the realistic relighting of dynamic human avatars, providing a substantial speed advantage. We exhibit more results in our project page: https://GS-IA.github.io.
3D StreetUnveiler with Semantic-Aware 2DGS
May 28, 2024



Unveiling an empty street from crowded observations captured by in-car cameras is crucial for autonomous driving. However, removing all temporary static objects, such as stopped vehicles and standing pedestrians, presents a significant challenge. Unlike object-centric 3D inpainting, which relies on thorough observation in a small scene, street scenes involve long trajectories that differ from previous 3D inpainting tasks. The camera-centric moving environment of captured videos further complicates the task due to the limited degree and time duration of object observation. To address these obstacles, we introduce StreetUnveiler to reconstruct an empty street. StreetUnveiler learns a 3D representation of the empty street from crowded observations. Our representation is based on the hard-label semantic 2D Gaussian Splatting (2DGS) for its scalability and ability to identify Gaussians to be removed. We inpaint rendered image after removing unwanted Gaussians to provide pseudo-labels and subsequently re-optimize the 2DGS. Given its temporal continuous movement, we divide the empty street scene into observed, partial-observed, and unobserved regions, which we propose to locate through a rendered alpha map. This decomposition helps us to minimize the regions that need to be inpainted. To enhance the temporal consistency of the inpainting, we introduce a novel time-reversal framework to inpaint frames in reverse order and use later frames as references for earlier frames to fully utilize the long-trajectory observations. Our experiments conducted on the street scene dataset successfully reconstructed a 3D representation of the empty street. The mesh representation of the empty street can be extracted for further applications. Project page and more visualizations can be found at: https://streetunveiler.github.io
RoomDesigner: Encoding Anchor-latents for Style-consistent and Shape-compatible Indoor Scene Generation
Oct 16, 2023Indoor scene generation aims at creating shape-compatible, style-consistent furniture arrangements within a spatially reasonable layout. However, most existing approaches primarily focus on generating plausible furniture layouts without incorporating specific details related to individual furniture pieces. To address this limitation, we propose a two-stage model integrating shape priors into the indoor scene generation by encoding furniture as anchor latent representations. In the first stage, we employ discrete vector quantization to encode furniture pieces as anchor-latents. Based on the anchor-latents representation, the shape and location information of the furniture was characterized by a concatenation of location, size, orientation, class, and our anchor latent. In the second stage, we leverage a transformer model to predict indoor scenes autoregressively. Thanks to incorporating the proposed anchor-latents representations, our generative model produces shape-compatible and style-consistent furniture arrangements and synthesis furniture in diverse shapes. Furthermore, our method facilitates various human interaction applications, such as style-consistent scene completion, object mismatch correction, and controllable object-level editing. Experimental results on the 3D-Front dataset demonstrate that our approach can generate more consistent and compatible indoor scenes compared to existing methods, even without shape retrieval. Additionally, extensive ablation studies confirm the effectiveness of our design choices in the indoor scene generation model.
ResNeRF: Geometry-Guided Residual Neural Radiance Field for Indoor Scene Novel View Synthesis
Dec 01, 2022



We represent the ResNeRF, a novel geometry-guided two-stage framework for indoor scene novel view synthesis. Be aware of that a good geometry would greatly boost the performance of novel view synthesis, and to avoid the geometry ambiguity issue, we propose to characterize the density distribution of the scene based on a base density estimated from scene geometry and a residual density parameterized by the geometry. In the first stage, we focus on geometry reconstruction based on SDF representation, which would lead to a good geometry surface of the scene and also a sharp density. In the second stage, the residual density is learned based on the SDF learned in the first stage for encoding more details about the appearance. In this way, our method can better learn the density distribution with the geometry prior for high-fidelity novel view synthesis while preserving the 3D structures. Experiments on large-scale indoor scenes with many less-observed and textureless areas show that with the good 3D surface, our method achieves state-of-the-art performance for novel view synthesis.
TransRAC: Encoding Multi-scale Temporal Correlation with Transformers for Repetitive Action Counting
Apr 03, 2022


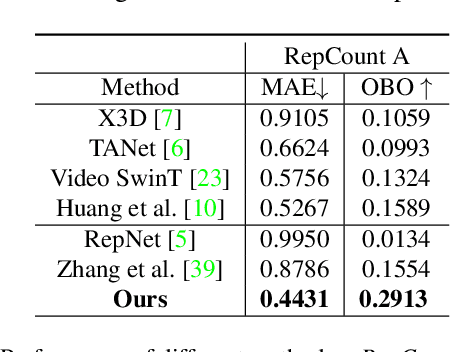
Counting repetitive actions are widely seen in human activities such as physical exercise. Existing methods focus on performing repetitive action counting in short videos, which is tough for dealing with longer videos in more realistic scenarios. In the data-driven era, the degradation of such generalization capability is mainly attributed to the lack of long video datasets. To complement this margin, we introduce a new large-scale repetitive action counting dataset covering a wide variety of video lengths, along with more realistic situations where action interruption or action inconsistencies occur in the video. Besides, we also provide a fine-grained annotation of the action cycles instead of just counting annotation along with a numerical value. Such a dataset contains 1,451 videos with about 20,000 annotations, which is more challenging. For repetitive action counting towards more realistic scenarios, we further propose encoding multi-scale temporal correlation with transformers that can take into account both performance and efficiency. Furthermore, with the help of fine-grained annotation of action cycles, we propose a density map regression-based method to predict the action period, which yields better performance with sufficient interpretability. Our proposed method outperforms state-of-the-art methods on all datasets and also achieves better performance on the unseen dataset without fine-tuning. The dataset and code are available.