 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeakly Supervised Video Representation Learning with Unaligned Text for Sequential Videos
Mar 28, 2023



Sequential video understanding, as an emerging video understanding task, has driven lots of researchers' attention because of its goal-oriented nature. This paper studies weakly supervised sequential video understanding where the accurate time-stamp level text-video alignment is not provided. We solve this task by borrowing ideas from CLIP. Specifically, we use a transformer to aggregate frame-level features for video representation and use a pre-trained text encoder to encode the texts corresponding to each action and the whole video, respectively. To model the correspondence between text and video, we propose a multiple granularity loss, where the video-paragraph contrastive loss enforces matching between the whole video and the complete script, and a fine-grained frame-sentence contrastive loss enforces the matching between each action and its description. As the frame-sentence correspondence is not available, we propose to use the fact that video actions happen sequentially in the temporal domain to generate pseudo frame-sentence correspondence and supervise the network training with the pseudo labels. Extensive experiments on video sequence verification and text-to-video matching show that our method outperforms baselines by a large margin, which validates the effectiveness of our proposed approach. Code is available at https://github.com/svip-lab/WeakSVR
TransRAC: Encoding Multi-scale Temporal Correlation with Transformers for Repetitive Action Counting
Apr 03, 2022


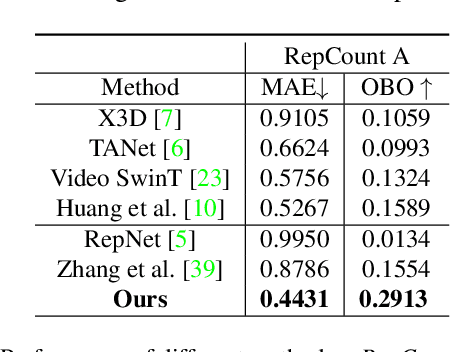
Counting repetitive actions are widely seen in human activities such as physical exercise. Existing methods focus on performing repetitive action counting in short videos, which is tough for dealing with longer videos in more realistic scenarios. In the data-driven era, the degradation of such generalization capability is mainly attributed to the lack of long video datasets. To complement this margin, we introduce a new large-scale repetitive action counting dataset covering a wide variety of video lengths, along with more realistic situations where action interruption or action inconsistencies occur in the video. Besides, we also provide a fine-grained annotation of the action cycles instead of just counting annotation along with a numerical value. Such a dataset contains 1,451 videos with about 20,000 annotations, which is more challenging. For repetitive action counting towards more realistic scenarios, we further propose encoding multi-scale temporal correlation with transformers that can take into account both performance and efficiency. Furthermore, with the help of fine-grained annotation of action cycles, we propose a density map regression-based method to predict the action period, which yields better performance with sufficient interpretability. Our proposed method outperforms state-of-the-art methods on all datasets and also achieves better performance on the unseen dataset without fine-tuning. The dataset and code are available.