 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Model Efficiency: Multi-Agent Inference with Large Models
Apr 06, 2026Most vision-language models (VLMs) apply a large language model (LLM) as the decoder, where the response tokens are generated sequentially through autoregression. Therefore, the number of output tokens can be the bottleneck of the end-to-end latency. However, different models may require vastly different numbers of output tokens to achieve comparable performance. In this work, we conduct a comprehensive analysis of the latency across different components of VLMs on simulated data. The experiment shows that a large model with fewer output tokens can be more efficient than a small model with a long output sequence. The empirical study on diverse real-world benchmarks confirms the observation that a large model can achieve better or comparable performance as a small model with significantly fewer output tokens. To leverage the efficiency of large models, we propose a multi-agent inference framework that keeps large models with short responses but transfers the key reasoning tokens from the small model when necessary. The comparison on benchmark tasks demonstrates that by reusing the reasoning tokens from small models, it can help approach the performance of a large model with its own reasoning, which confirms the effectiveness of our proposal.
NTIRE 2026 3D Restoration and Reconstruction in Real-world Adverse Conditions: RealX3D Challenge Results
Apr 05, 2026This paper presents a comprehensive review of the NTIRE 2026 3D Restoration and Reconstruction (3DRR) Challenge, detailing the proposed methods and results. The challenge seeks to identify robust reconstruction pipelines that are robust under real-world adverse conditions, specifically extreme low-light and smoke-degraded environments, as captured by our RealX3D benchmark. A total of 279 participants registered for the competition, of whom 33 teams submitted valid results. We thoroughly evaluate the submitted approaches against state-of-the-art baselines, revealing significant progress in 3D reconstruction under adverse conditions. Our analysis highlights shared design principles among top-performing methods and provides insights into effective strategies for handling 3D scene degradation.
To Think or Not To Think, That is The Question for Large Reasoning Models in Theory of Mind Tasks
Feb 11, 2026Theory of Mind (ToM) assesses whether models can infer hidden mental states such as beliefs, desires, and intentions, which is essential for natural social interaction. Although recent progress in Large Reasoning Models (LRMs) has boosted step-by-step inference in mathematics and coding, it is still underexplored whether this benefit transfers to socio-cognitive skills. We present a systematic study of nine advanced Large Language Models (LLMs), comparing reasoning models with non-reasoning models on three representative ToM benchmarks. The results show that reasoning models do not consistently outperform non-reasoning models and sometimes perform worse. A fine-grained analysis reveals three insights. First, slow thinking collapses: accuracy significantly drops as responses grow longer, and larger reasoning budgets hurt performance. Second, moderate and adaptive reasoning benefits performance: constraining reasoning length mitigates failure, while distinct success patterns demonstrate the necessity of dynamic adaptation. Third, option matching shortcut: when multiple choice options are removed, reasoning models improve markedly, indicating reliance on option matching rather than genuine deduction. We also design two intervention approaches: Slow-to-Fast (S2F) adaptive reasoning and Think-to-Match (T2M) shortcut prevention to further verify and mitigate the problems. With all results, our study highlights the advancement of LRMs in formal reasoning (e.g., math, code) cannot be fully transferred to ToM, a typical task in social reasoning. We conclude that achieving robust ToM requires developing unique capabilities beyond existing reasoning methods.
Towards Robust Dysarthric Speech Recognition: LLM-Agent Post-ASR Correction Beyond WER
Jan 29, 2026While Automatic Speech Recognition (ASR) is typically benchmarked by word error rate (WER), real-world applications ultimately hinge on semantic fidelity. This mismatch is particularly problematic for dysarthric speech, where articulatory imprecision and disfluencies can cause severe semantic distortions. To bridge this gap, we introduce a Large Language Model (LLM)-based agent for post-ASR correction: a Judge-Editor over the top-k ASR hypotheses that keeps high-confidence spans, rewrites uncertain segments, and operates in both zero-shot and fine-tuned modes. In parallel, we release SAP-Hypo5, the largest benchmark for dysarthric speech correction, to enable reproducibility and future exploration. Under multi-perspective evaluation, our agent achieves a 14.51% WER reduction alongside substantial semantic gains, including a +7.59 pp improvement in MENLI and +7.66 pp in Slot Micro F1 on challenging samples. Our analysis further reveals that WER is highly sensitive to domain shift, whereas semantic metrics correlate more closely with downstream task performance.
MMTok: Multimodal Coverage Maximization for Efficient Inference of VLMs
Aug 25, 2025Vision-Language Models (VLMs) demonstrate impressive performance in understanding visual content with language instruction by converting visual input to vision tokens. However, redundancy in vision tokens results in the degenerated inference efficiency of VLMs. While many algorithms have been proposed to reduce the number of vision tokens, most of them apply only unimodal information (i.e., vision/text) for pruning and ignore the inherent multimodal property of vision-language tasks. Moreover, it lacks a generic criterion that can be applied to different modalities. To mitigate this limitation, in this work, we propose to leverage both vision and text tokens to select informative vision tokens by the criterion of coverage. We first formulate the subset selection problem as a maximum coverage problem. Afterward, a subset of vision tokens is optimized to cover the text tokens and the original set of vision tokens, simultaneously. Finally, a VLM agent can be adopted to further improve the quality of text tokens for guiding vision pruning. The proposed method MMTok is extensively evaluated on benchmark datasets with different VLMs. The comparison illustrates that vision and text information are complementary, and combining multimodal information can surpass the unimodal baseline with a clear margin. Moreover, under the maximum coverage criterion on the POPE dataset, our method achieves a 1.87x speedup while maintaining 98.7% of the original performance on LLaVA-NeXT-13B. Furthermore, with only four vision tokens, it still preserves 87.7% of the original performance on LLaVA-1.5-7B. These results highlight the effectiveness of coverage in token selection.
Complex Logical Instruction Generation
Aug 12, 2025Instruction following has catalyzed the recent era of Large Language Models (LLMs) and is the foundational skill underpinning more advanced capabilities such as reasoning and agentic behaviors. As tasks grow more challenging, the logic structures embedded in natural language instructions becomes increasingly intricate. However, how well LLMs perform on such logic-rich instructions remains under-explored. We propose LogicIFGen and LogicIFEval. LogicIFGen is a scalable, automated framework for generating verifiable instructions from code functions, which can naturally express rich logic such as conditionals, nesting, recursion, and function calls. We further curate a collection of complex code functions and use LogicIFGen to construct LogicIFEval, a benchmark comprising 426 verifiable logic-rich instructions. Our experiments demonstrate that current state-of-the-art LLMs still struggle to correctly follow the instructions in LogicIFEval. Most LLMs can only follow fewer than 60% of the instructions, revealing significant deficiencies in the instruction-following ability. Code and Benchmark: https://github.com/mianzhang/LogicIF
LLM-ML Teaming: Integrated Symbolic Decoding and Gradient Search for Valid and Stable Generative Feature Transformation
Jun 10, 2025

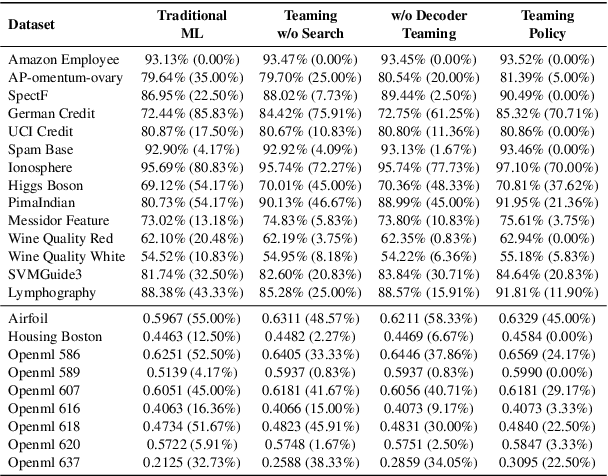
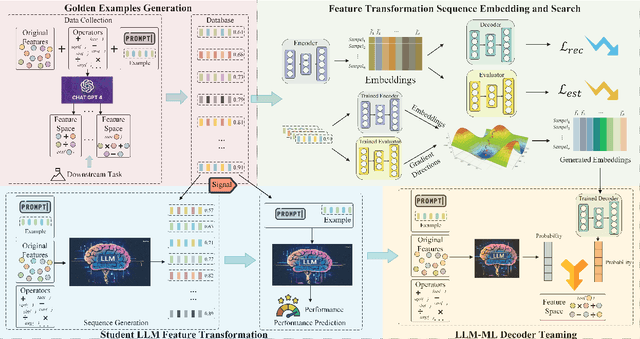
Feature transformation enhances data representation by deriving new features from the original data. Generative AI offers potential for this task, but faces challenges in stable generation (consistent outputs) and valid generation (error-free sequences). Existing methods--traditional MLs' low validity and LLMs' instability--fail to resolve both. We find that LLMs ensure valid syntax, while ML's gradient-steered search stabilizes performance. To bridge this gap, we propose a teaming framework combining LLMs' symbolic generation with ML's gradient optimization. This framework includes four steps: (1) golden examples generation, aiming to prepare high-quality samples with the ground knowledge of the teacher LLM; (2) feature transformation sequence embedding and search, intending to uncover potentially superior embeddings within the latent space; (3) student LLM feature transformation, aiming to distill knowledge from the teacher LLM; (4) LLM-ML decoder teaming, dedicating to combine ML and the student LLM probabilities for valid and stable generation. The experiments on various datasets show that the teaming policy can achieve 5\% improvement in downstream performance while reducing nearly half of the error cases. The results also demonstrate the efficiency and robustness of the teaming policy. Additionally, we also have exciting findings on LLMs' capacity to understand the original data.
Efficient Post-Training Refinement of Latent Reasoning in Large Language Models
Jun 10, 2025



Reasoning is a key component of language understanding in Large Language Models. While Chain-of-Thought prompting enhances performance via explicit intermediate steps, it suffers from sufficient token overhead and a fixed reasoning trajectory, preventing step-wise refinement. Recent advances in latent reasoning address these limitations by refining internal reasoning processes directly in the model's latent space, without producing explicit outputs. However, a key challenge remains: how to effectively update reasoning embeddings during post-training to guide the model toward more accurate solutions. To overcome this challenge, we propose a lightweight post-training framework that refines latent reasoning trajectories using two novel strategies: 1) Contrastive reasoning feedback, which compares reasoning embeddings against strong and weak baselines to infer effective update directions via embedding enhancement; 2) Residual embedding refinement, which stabilizes updates by progressively integrating current and historical gradients, enabling fast yet controlled convergence. Extensive experiments and case studies are conducted on five reasoning benchmarks to demonstrate the effectiveness of the proposed framework. Notably, a 5\% accuracy gain on MathQA without additional training.
Agentic Feature Augmentation: Unifying Selection and Generation with Teaming, Planning, and Memories
May 21, 2025As a widely-used and practical tool, feature engineering transforms raw data into discriminative features to advance AI model performance. However, existing methods usually apply feature selection and generation separately, failing to strive a balance between reducing redundancy and adding meaningful dimensions. To fill this gap, we propose an agentic feature augmentation concept, where the unification of feature generation and selection is modeled as agentic teaming and planning. Specifically, we develop a Multi-Agent System with Long and Short-Term Memory (MAGS), comprising a selector agent to eliminate redundant features, a generator agent to produce informative new dimensions, and a router agent that strategically coordinates their actions. We leverage in-context learning with short-term memory for immediate feedback refinement and long-term memory for globally optimal guidance. Additionally, we employ offline Proximal Policy Optimization (PPO) reinforcement fine-tuning to train the router agent for effective decision-making to navigate a vast discrete feature space. Extensive experiments demonstrate that this unified agentic framework consistently achieves superior task performance by intelligently orchestrating feature selection and generation.
Brownian Bridge Augmented Surrogate Simulation and Injection Planning for Geological CO$_2$ Storage
May 21, 2025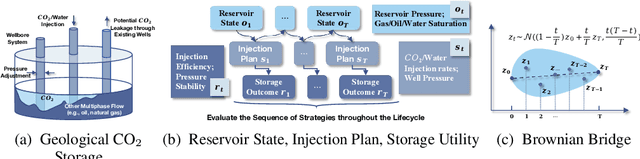
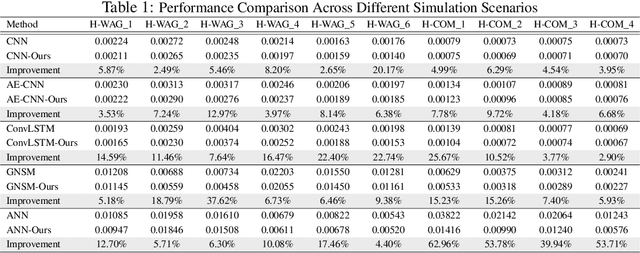
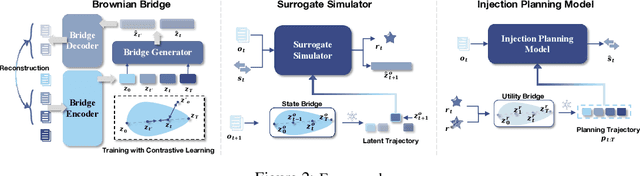

Geological CO2 storage (GCS) involves injecting captured CO2 into deep subsurface formations to support climate goals. The effective management of GCS relies on adaptive injection planning to dynamically control injection rates and well pressures to balance both storage safety and efficiency. Prior literature, including numerical optimization methods and surrogate-optimization methods, is limited by real-world GCS requirements of smooth state transitions and goal-directed planning within limited time. To address these limitations, we propose a Brownian Bridge-augmented framework for surrogate simulation and injection planning in GCS and develop two insights: (i) Brownian bridge as a smooth state regularizer for better surrogate simulation; (ii) Brownian bridge as goal-time-conditioned planning guidance for improved injection planning. Our method has three stages: (i) learning deep Brownian bridge representations with contrastive and reconstructive losses from historical reservoir and utility trajectories, (ii) incorporating Brownian bridge-based next state interpolation for simulator regularization, and (iii) guiding injection planning with Brownian utility-conditioned trajectories to generate high-quality injection plans. Experimental results across multiple datasets collected from diverse GCS settings demonstrate that our framework consistently improves simulation fidelity and planning effectiveness while maintaining low computational overhead.