 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRethinking Model Efficiency: Multi-Agent Inference with Large Models
Apr 06, 2026Most vision-language models (VLMs) apply a large language model (LLM) as the decoder, where the response tokens are generated sequentially through autoregression. Therefore, the number of output tokens can be the bottleneck of the end-to-end latency. However, different models may require vastly different numbers of output tokens to achieve comparable performance. In this work, we conduct a comprehensive analysis of the latency across different components of VLMs on simulated data. The experiment shows that a large model with fewer output tokens can be more efficient than a small model with a long output sequence. The empirical study on diverse real-world benchmarks confirms the observation that a large model can achieve better or comparable performance as a small model with significantly fewer output tokens. To leverage the efficiency of large models, we propose a multi-agent inference framework that keeps large models with short responses but transfers the key reasoning tokens from the small model when necessary. The comparison on benchmark tasks demonstrates that by reusing the reasoning tokens from small models, it can help approach the performance of a large model with its own reasoning, which confirms the effectiveness of our proposal.
Rare Event Early Detection: A Dataset of Sepsis Onset for Critically Ill Trauma Patients
Feb 03, 2026Sepsis is a major public health concern due to its high morbidity, mortality, and cost. Its clinical outcome can be substantially improved through early detection and timely intervention. By leveraging publicly available datasets, machine learning (ML) has driven advances in both research and clinical practice. However, existing public datasets consider ICU patients (Intensive Care Unit) as a uniform group and neglect the potential challenges presented by critically ill trauma patients in whom injury-related inflammation and organ dysfunction can overlap with the clinical features of sepsis. We propose that a targeted identification of post-traumatic sepsis is necessary in order to develop methods for early detection. Therefore, we introduce a publicly available standardized post-trauma sepsis onset dataset extracted, relabeled using standardized post-trauma clinical facts, and validated from MIMIC-III. Furthermore, we frame early detection of post-trauma sepsis onset according to clinical workflow in ICUs in a daily basis resulting in a new rare event detection problem. We then establish a general benchmark through comprehensive experiments, which shows the necessity of further advancements using this new dataset. The data code is available at https://github.com/ML4UWHealth/SepsisOnset_TraumaCohort.git.
Hierarchy-Aware Fine-Tuning of Vision-Language Models
Dec 25, 2025Vision-Language Models (VLMs) learn powerful multimodal representations through large-scale image-text pretraining, but adapting them to hierarchical classification is underexplored. Standard approaches treat labels as flat categories and require full fine-tuning, which is expensive and produces inconsistent predictions across taxonomy levels. We propose an efficient hierarchy-aware fine-tuning framework that updates a few parameters while enforcing structural consistency. We combine two objectives: Tree-Path KL Divergence (TP-KL) aligns predictions along the ground-truth label path for vertical coherence, while Hierarchy-Sibling Smoothed Cross-Entropy (HiSCE) encourages consistent predictions among sibling classes. Both losses work in the VLM's shared embedding space and integrate with lightweight LoRA adaptation. Experiments across multiple benchmarks show consistent improvements in Full-Path Accuracy and Tree-based Inconsistency Error with minimal parameter overhead. Our approach provides an efficient strategy for adapting VLMs to structured taxonomies.
MMTok: Multimodal Coverage Maximization for Efficient Inference of VLMs
Aug 25, 2025Vision-Language Models (VLMs) demonstrate impressive performance in understanding visual content with language instruction by converting visual input to vision tokens. However, redundancy in vision tokens results in the degenerated inference efficiency of VLMs. While many algorithms have been proposed to reduce the number of vision tokens, most of them apply only unimodal information (i.e., vision/text) for pruning and ignore the inherent multimodal property of vision-language tasks. Moreover, it lacks a generic criterion that can be applied to different modalities. To mitigate this limitation, in this work, we propose to leverage both vision and text tokens to select informative vision tokens by the criterion of coverage. We first formulate the subset selection problem as a maximum coverage problem. Afterward, a subset of vision tokens is optimized to cover the text tokens and the original set of vision tokens, simultaneously. Finally, a VLM agent can be adopted to further improve the quality of text tokens for guiding vision pruning. The proposed method MMTok is extensively evaluated on benchmark datasets with different VLMs. The comparison illustrates that vision and text information are complementary, and combining multimodal information can surpass the unimodal baseline with a clear margin. Moreover, under the maximum coverage criterion on the POPE dataset, our method achieves a 1.87x speedup while maintaining 98.7% of the original performance on LLaVA-NeXT-13B. Furthermore, with only four vision tokens, it still preserves 87.7% of the original performance on LLaVA-1.5-7B. These results highlight the effectiveness of coverage in token selection.
Customized Multiple Clustering via Multi-Modal Subspace Proxy Learning
Nov 06, 2024



Multiple clustering aims to discover various latent structures of data from different aspects. Deep multiple clustering methods have achieved remarkable performance by exploiting complex patterns and relationships in data. However, existing works struggle to flexibly adapt to diverse user-specific needs in data grouping, which may require manual understanding of each clustering. To address these limitations, we introduce Multi-Sub, a novel end-to-end multiple clustering approach that incorporates a multi-modal subspace proxy learning framework in this work. Utilizing the synergistic capabilities of CLIP and GPT-4, Multi-Sub aligns textual prompts expressing user preferences with their corresponding visual representations. This is achieved by automatically generating proxy words from large language models that act as subspace bases, thus allowing for the customized representation of data in terms specific to the user's interests. Our method consistently outperforms existing baselines across a broad set of datasets in visual multiple clustering tasks. Our code is available at https://github.com/Alexander-Yao/Multi-Sub.
SimInversion: A Simple Framework for Inversion-Based Text-to-Image Editing
Sep 16, 2024



Diffusion models demonstrate impressive image generation performance with text guidance. Inspired by the learning process of diffusion, existing images can be edited according to text by DDIM inversion. However, the vanilla DDIM inversion is not optimized for classifier-free guidance and the accumulated error will result in the undesired performance. While many algorithms are developed to improve the framework of DDIM inversion for editing, in this work, we investigate the approximation error in DDIM inversion and propose to disentangle the guidance scale for the source and target branches to reduce the error while keeping the original framework. Moreover, a better guidance scale (i.e., 0.5) than default settings can be derived theoretically. Experiments on PIE-Bench show that our proposal can improve the performance of DDIM inversion dramatically without sacrificing efficiency.
Text-Guided Mixup Towards Long-Tailed Image Categorization
Sep 05, 2024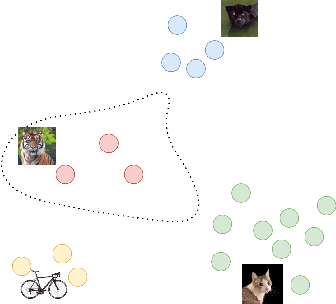
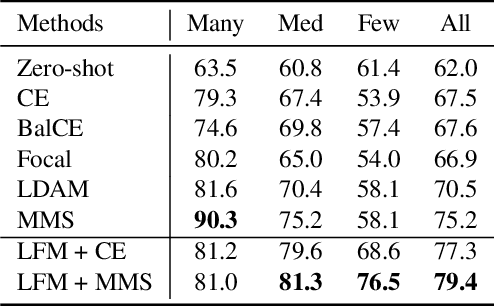
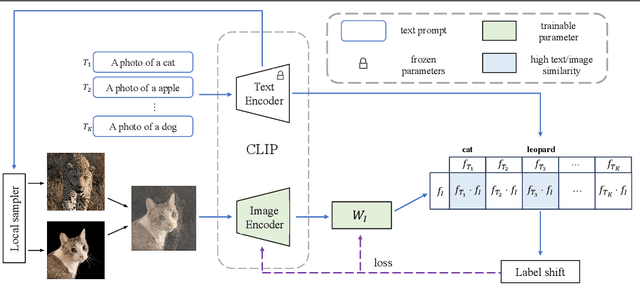
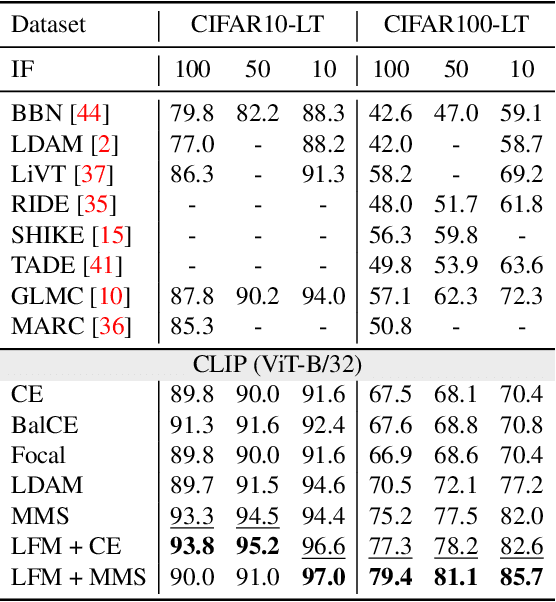
In many real-world applications, the frequency distribution of class labels for training data can exhibit a long-tailed distribution, which challenges traditional approaches of training deep neural networks that require heavy amounts of balanced data. Gathering and labeling data to balance out the class label distribution can be both costly and time-consuming. Many existing solutions that enable ensemble learning, re-balancing strategies, or fine-tuning applied to deep neural networks are limited by the inert problem of few class samples across a subset of classes. Recently, vision-language models like CLIP have been observed as effective solutions to zero-shot or few-shot learning by grasping a similarity between vision and language features for image and text pairs. Considering that large pre-trained vision-language models may contain valuable side textual information for minor classes, we propose to leverage text supervision to tackle the challenge of long-tailed learning. Concretely, we propose a novel text-guided mixup technique that takes advantage of the semantic relations between classes recognized by the pre-trained text encoder to help alleviate the long-tailed problem. Our empirical study on benchmark long-tailed tasks demonstrates the effectiveness of our proposal with a theoretical guarantee. Our code is available at https://github.com/rsamf/text-guided-mixup.
SeA: Semantic Adversarial Augmentation for Last Layer Features from Unsupervised Representation Learning
Aug 23, 2024Deep features extracted from certain layers of a pre-trained deep model show superior performance over the conventional hand-crafted features. Compared with fine-tuning or linear probing that can explore diverse augmentations, \eg, random crop/flipping, in the original input space, the appropriate augmentations for learning with fixed deep features are more challenging and have been less investigated, which degenerates the performance. To unleash the potential of fixed deep features, we propose a novel semantic adversarial augmentation (SeA) in the feature space for optimization. Concretely, the adversarial direction implied by the gradient will be projected to a subspace spanned by other examples to preserve the semantic information. Then, deep features will be perturbed with the semantic direction, and augmented features will be applied to learn the classifier. Experiments are conducted on $11$ benchmark downstream classification tasks with $4$ popular pre-trained models. Our method is $2\%$ better than the deep features without SeA on average. Moreover, compared to the expensive fine-tuning that is expected to give good performance, SeA shows a comparable performance on $6$ out of $11$ tasks, demonstrating the effectiveness of our proposal in addition to its efficiency. Code is available at \url{https://github.com/idstcv/SeA}.
Online Zero-Shot Classification with CLIP
Aug 23, 2024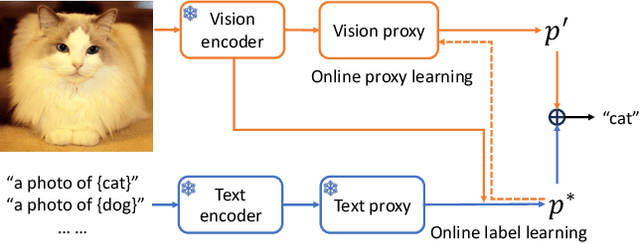
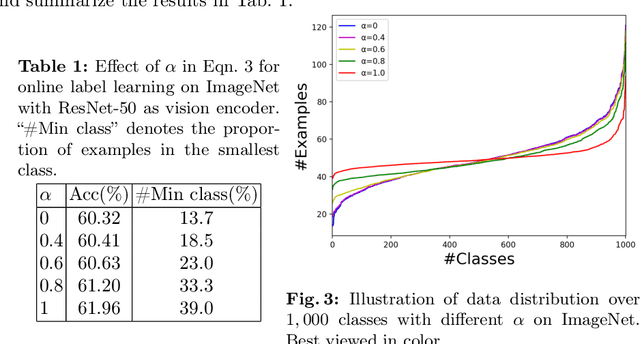


Vision-language pre-training such as CLIP enables zero-shot transfer that can classify images according to the candidate class names. While CLIP demonstrates an impressive zero-shot performance on diverse downstream tasks, the distribution from the target data has not been leveraged sufficiently. In this work, we study a novel online zero-shot transfer scenario, where each image arrives in a random order for classification and is visited only once to obtain prediction immediately without storing its representation. Compared with the vanilla zero-shot classification, the proposed framework preserves its flexibility for online service while considering the statistics of the arrived images as the side information to capture the distribution of target data, which can help improve the performance of real-world applications. To tackle the challenge of effective online optimization, we first develop online label learning to model the target data distribution. Then, the proxy of each class in the vision space is further optimized with the proposed online proxy learning method to mitigate the modality gap between images and text. The convergence of both online strategies can be theoretically guaranteed. By combining the predicted label from the online label learning and proxy learning, our online zero-shot transfer method (OnZeta) achieves $78.94\%$ accuracy on ImageNet without accessing the entire data set. Moreover, extensive experiments on other 13 downstream tasks with different vision encoders show a more than $3\%$ improvement on average, which demonstrates the effectiveness of our proposal. Code is available at \url{https://github.com/idstcv/OnZeta}.
Multi-Modal Proxy Learning Towards Personalized Visual Multiple Clustering
Apr 24, 2024Multiple clustering has gained significant attention in recent years due to its potential to reveal multiple hidden structures of data from different perspectives. The advent of deep multiple clustering techniques has notably advanced the performance by uncovering complex patterns and relationships within large datasets. However, a major challenge arises as users often do not need all the clusterings that algorithms generate, and figuring out the one needed requires a substantial understanding of each clustering result. Traditionally, aligning a user's brief keyword of interest with the corresponding vision components was challenging, but the emergence of multi-modal and large language models (LLMs) has begun to bridge this gap. In response, given unlabeled target visual data, we propose Multi-MaP, a novel method employing a multi-modal proxy learning process. It leverages CLIP encoders to extract coherent text and image embeddings, with GPT-4 integrating users' interests to formulate effective textual contexts. Moreover, reference word constraint and concept-level constraint are designed to learn the optimal text proxy according to the user's interest. Multi-MaP not only adeptly captures a user's interest via a keyword but also facilitates identifying relevant clusterings. Our extensive experiments show that Multi-MaP consistently outperforms state-of-the-art methods in all benchmark multi-clustering vision tasks. Our code is available at https://github.com/Alexander-Yao/Multi-MaP.