 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCurved Beam Enabled Wireless Communications: Modeling, Analysis and Optimization
Jun 08, 2026In this paper, the problem of using curved beams to improve wireless communication performance in the presence of a blockage is studied. In particular, a transmitter equipped with a continuous aperture array can generate curved beams to serve multiple receivers by allowing signals to propagate along both straight and curved paths. To optimize the weighted sum-rate, a curved beam model is developed for controlling the beam steering, beam focusing, and beam curving functions, along with a segmented channel model to characterize practical channels induced by the blockage. Based on the introduced curved beam model, an optimization problem is posed with the goal of maximizing the weighted sum-rate of all users under a transmit power budget and physical constraints of curved beams. To solve this problem, the continuous aperture is first converted into finite summations via a discrete sampling of the continuous coordinate. Then, the performance gap between the ideal continuous aperture design and its practical discrete aperture approximation is analyzed. Based on the above discrete approximation, an iterative algorithm is developed to optimize curved beam control parameters. In particular, the original problem is reformulated as a trackable form via fractional programming (FP). Then, the transformed problem is solved by designing an enhanced block coordinate ascent (BCA) method which determines a surrogate-construction point leveraging the local descent from previous iterations, thereby accelerating convergence. Then, a proximal regularization term is included into the surrogate function to control the update magnitude and suppress aggressive update, thereby improving updates stability. Finally, the beam amplitudes are computed based on the effective channel gains. Simulation results show that the proposed method can improve the weighted sum-rate compared to using only straight beam.
Why Keep Your Doubts to Yourself? Trading Visual Uncertainties in Multi-Agent Bandit Systems
Jan 26, 2026Vision-Language Models (VLMs) enable powerful multi-agent systems, but scaling them is economically unsustainable: coordinating heterogeneous agents under information asymmetry often spirals costs. Existing paradigms, such as Mixture-of-Agents and knowledge-based routers, rely on heuristic proxies that ignore costs and collapse uncertainty structure, leading to provably suboptimal coordination. We introduce Agora, a framework that reframes coordination as a decentralized market for uncertainty. Agora formalizes epistemic uncertainty into a structured, tradable asset (perceptual, semantic, inferential), and enforces profitability-driven trading among agents based on rational economic rules. A market-aware broker, extending Thompson Sampling, initiates collaboration and guides the system toward cost-efficient equilibria. Experiments on five multimodal benchmarks (MMMU, MMBench, MathVision, InfoVQA, CC-OCR) show that Agora outperforms strong VLMs and heuristic multi-agent strategies, e.g., achieving +8.5% accuracy over the best baseline on MMMU while reducing cost by over 3x. These results establish market-based coordination as a principled and scalable paradigm for building economically viable multi-agent visual intelligence systems.
UrbanGraph: Physics-Informed Spatio-Temporal Dynamic Heterogeneous Graphs for Urban Microclimate Prediction
Oct 01, 2025With rapid urbanization, predicting urban microclimates has become critical, as it affects building energy demand and public health risks. However, existing generative and homogeneous graph approaches fall short in capturing physical consistency, spatial dependencies, and temporal variability. To address this, we introduce UrbanGraph, a physics-informed framework integrating heterogeneous and dynamic spatio-temporal graphs. It encodes key physical processes -- vegetation evapotranspiration, shading, and convective diffusion -- while modeling complex spatial dependencies among diverse urban entities and their temporal evolution. We evaluate UrbanGraph on UMC4/12, a physics-based simulation dataset covering diverse urban configurations and climates. Results show that UrbanGraph improves $R^2$ by up to 10.8% and reduces FLOPs by 17.0% over all baselines, with heterogeneous and dynamic graphs contributing 3.5% and 7.1% gains. Our dataset provides the first high-resolution benchmark for spatio-temporal microclimate modeling, and our method extends to broader urban heterogeneous dynamic computing tasks.
RIS-Assisted Passive Localization (RAPL): An Efficient Zero-Overhead Framework Using Conditional Sample Mean
Mar 25, 2025



Reconfigurable Intelligent Surface (RIS) has been recognized as a promising solution for enhancing localization accuracy. Traditional RIS-based localization methods typically rely on prior channel knowledge, beam scanning, and pilot-based assistance. These approaches often result in substantial energy and computational overhead, and require real-time coordination between the base station (BS) and the RIS. To address these challenges, in this work, we move beyond conventional methods and introduce a novel data-driven, multiple RISs-assisted passive localization approach (RAPL). The proposed method includes two stages, the angle-of-directions (AoDs) between the RISs and the user is estimated by using the conditional sample mean in the first stage, and then the user's position is determined based on the estimated multiple AoD pairs in the second stage. This approach only utilizes the existing communication signals between the user and the BS, relying solely on the measurement of received signal power at each BS antenna for a set of randomly generated phase shifts across all RISs. Moreover, by obviating the need for real-time RIS phase shift optimization or user-to-BS pilot transmissions, the method introduces no additional communication overhead, making it highly suitable for deployment in real-world networks. The proposed scheme is then extended to multi-RIS scenarios considering both parallel and cascaded RIS topologies. Numerical results show that the proposed RAPL improves localization accuracy while significantly reducing energy and signaling overhead compared to conventional methods.
RIS-Assisted Localization: A Novel Conditional Sample Mean Approach without CSI
Mar 24, 2025


Reconfigurable intelligent surface (RIS) has been recognized as a promising solution for enhancing localization accuracy. Traditional RIS-based localization methods typically rely on prior channel knowledge, beam scanning, and pilot-based assistance. These approaches often result in substantial energy and computational overhead, and require real-time coordination between the base station (BS) and the RIS. In this work, we propose a novel multiple RISs aided localization approach to address these challenges. The proposed method first estimates the angle-of-directions (AoDs) between the RISs and the user using the conditional sample mean approach, and then uses the estimated multiple AoD pairs to determine the user's position. This approach only requires measuring the received signal strength at the BS for a set of randomly generated phase shifts across all RISs, thereby eliminating the need for real-time RIS phase shift design or user-to-BS pilot transmissions. Numerical results show that the proposed localization approach improves localization accuracy while significantly reducing energy and signaling overhead compared to conventional methods.
KABB: Knowledge-Aware Bayesian Bandits for Dynamic Expert Coordination in Multi-Agent Systems
Feb 11, 2025



As scaling large language models faces prohibitive costs, multi-agent systems emerge as a promising alternative, though challenged by static knowledge assumptions and coordination inefficiencies. We introduces Knowledge-Aware Bayesian Bandits (KABB), a novel framework that enhances multi-agent system coordination through semantic understanding and dynamic adaptation. The framework features three key innovations: a three-dimensional knowledge distance model for deep semantic understanding, a dual-adaptation mechanism for continuous expert optimization, and a knowledge-aware Thompson Sampling strategy for efficient expert selection. Extensive evaluation demonstrates KABB achieves an optimal cost-performance balance, maintaining high performance while keeping computational demands relatively low in multi-agent coordination.
Customized Multiple Clustering via Multi-Modal Subspace Proxy Learning
Nov 06, 2024



Multiple clustering aims to discover various latent structures of data from different aspects. Deep multiple clustering methods have achieved remarkable performance by exploiting complex patterns and relationships in data. However, existing works struggle to flexibly adapt to diverse user-specific needs in data grouping, which may require manual understanding of each clustering. To address these limitations, we introduce Multi-Sub, a novel end-to-end multiple clustering approach that incorporates a multi-modal subspace proxy learning framework in this work. Utilizing the synergistic capabilities of CLIP and GPT-4, Multi-Sub aligns textual prompts expressing user preferences with their corresponding visual representations. This is achieved by automatically generating proxy words from large language models that act as subspace bases, thus allowing for the customized representation of data in terms specific to the user's interests. Our method consistently outperforms existing baselines across a broad set of datasets in visual multiple clustering tasks. Our code is available at https://github.com/Alexander-Yao/Multi-Sub.
Swift Sampler: Efficient Learning of Sampler by 10 Parameters
Oct 08, 2024Data selection is essential for training deep learning models. An effective data sampler assigns proper sampling probability for training data and helps the model converge to a good local minimum with high performance. Previous studies in data sampling are mainly based on heuristic rules or learning through a huge amount of time-consuming trials. In this paper, we propose an automatic \textbf{swift sampler} search algorithm, \textbf{SS}, to explore automatically learning effective samplers efficiently. In particular, \textbf{SS} utilizes a novel formulation to map a sampler to a low dimension of hyper-parameters and uses an approximated local minimum to quickly examine the quality of a sampler. Benefiting from its low computational expense, \textbf{SS} can be applied on large-scale data sets with high efficiency. Comprehensive experiments on various tasks demonstrate that \textbf{SS} powered sampling can achieve obvious improvements (e.g., 1.5\% on ImageNet) and transfer among different neural networks. Project page: https://github.com/Alexander-Yao/Swift-Sampler.
Text-Guided Mixup Towards Long-Tailed Image Categorization
Sep 05, 2024
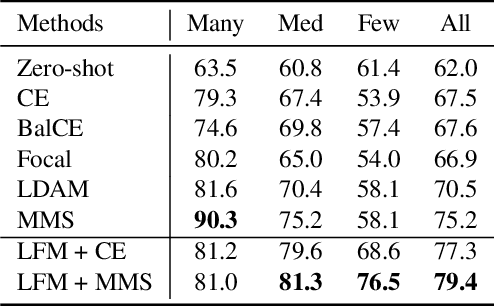
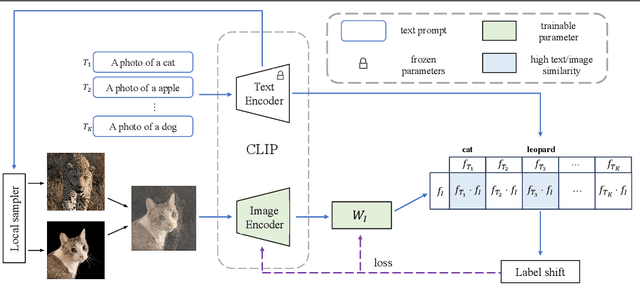
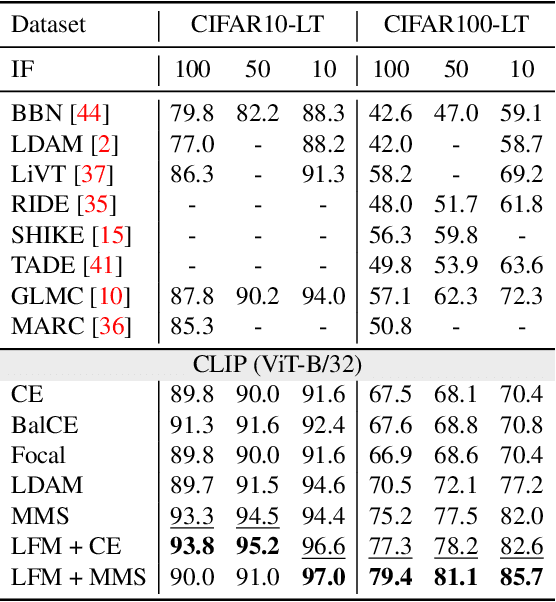
In many real-world applications, the frequency distribution of class labels for training data can exhibit a long-tailed distribution, which challenges traditional approaches of training deep neural networks that require heavy amounts of balanced data. Gathering and labeling data to balance out the class label distribution can be both costly and time-consuming. Many existing solutions that enable ensemble learning, re-balancing strategies, or fine-tuning applied to deep neural networks are limited by the inert problem of few class samples across a subset of classes. Recently, vision-language models like CLIP have been observed as effective solutions to zero-shot or few-shot learning by grasping a similarity between vision and language features for image and text pairs. Considering that large pre-trained vision-language models may contain valuable side textual information for minor classes, we propose to leverage text supervision to tackle the challenge of long-tailed learning. Concretely, we propose a novel text-guided mixup technique that takes advantage of the semantic relations between classes recognized by the pre-trained text encoder to help alleviate the long-tailed problem. Our empirical study on benchmark long-tailed tasks demonstrates the effectiveness of our proposal with a theoretical guarantee. Our code is available at https://github.com/rsamf/text-guided-mixup.
Blind Beamforming for Coverage Enhancement with Intelligent Reflecting Surface
Jul 17, 2024



Conventional policy for configuring an intelligent reflecting surface (IRS) typically requires channel state information (CSI), thus incurring substantial overhead costs and facing incompatibility with the current network protocols. This paper proposes a blind beamforming strategy in the absence of CSI, aiming to boost the minimum signal-to-noise ratio (SNR) among all the receiver positions, namely the coverage enhancement. Although some existing works already consider the IRS-assisted coverage enhancement without CSI, they assume certain position-channel models through which the channels can be recovered from the geographic locations. In contrast, our approach solely relies on the received signal power data, not assuming any position-channel model. We examine the achievability and converse of the proposed blind beamforming method. If the IRS has $N$ reflective elements and there are $U$ receiver positions, then our method guarantees the minimum SNR of $\Omega(N^2/U)$ -- which is fairly close to the upper bound $O(N+N^2\sqrt{\ln (NU)}/\sqrt[4]{U})$. Aside from the simulation results, we justify the practical use of blind beamforming in a field test at 2.6 GHz. According to the real-world experiment, the proposed blind beamforming method boosts the minimum SNR across seven random positions in a conference room by 18.22 dB, while the position-based method yields a boost of 12.08 dB.