 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Zero-Shot Classification with CLIP
Paper and Code
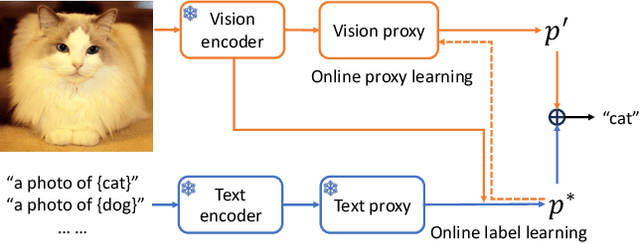
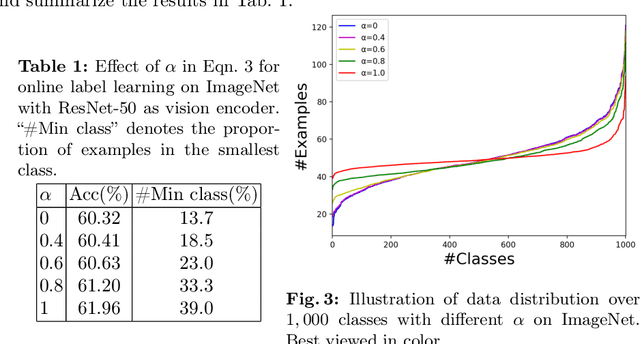


Vision-language pre-training such as CLIP enables zero-shot transfer that can classify images according to the candidate class names. While CLIP demonstrates an impressive zero-shot performance on diverse downstream tasks, the distribution from the target data has not been leveraged sufficiently. In this work, we study a novel online zero-shot transfer scenario, where each image arrives in a random order for classification and is visited only once to obtain prediction immediately without storing its representation. Compared with the vanilla zero-shot classification, the proposed framework preserves its flexibility for online service while considering the statistics of the arrived images as the side information to capture the distribution of target data, which can help improve the performance of real-world applications. To tackle the challenge of effective online optimization, we first develop online label learning to model the target data distribution. Then, the proxy of each class in the vision space is further optimized with the proposed online proxy learning method to mitigate the modality gap between images and text. The convergence of both online strategies can be theoretically guaranteed. By combining the predicted label from the online label learning and proxy learning, our online zero-shot transfer method (OnZeta) achieves $78.94\%$ accuracy on ImageNet without accessing the entire data set. Moreover, extensive experiments on other 13 downstream tasks with different vision encoders show a more than $3\%$ improvement on average, which demonstrates the effectiveness of our proposal. Code is available at \url{https://github.com/idstcv/OnZeta}.