 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHiPRAG: Hierarchical Process Rewards for Efficient Agentic Retrieval Augmented Generation
Oct 09, 2025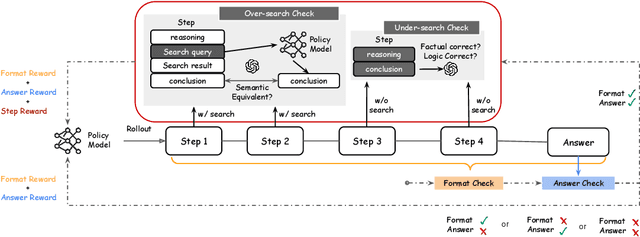
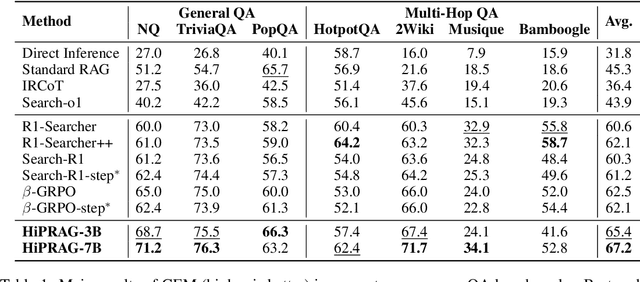
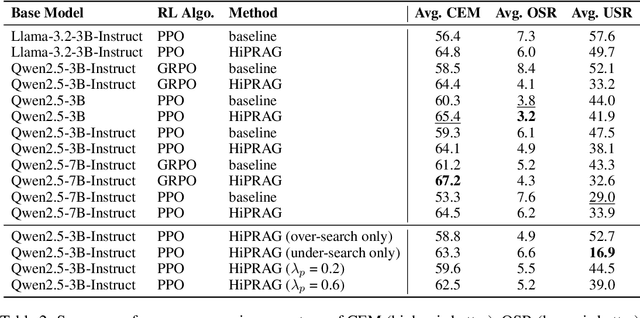
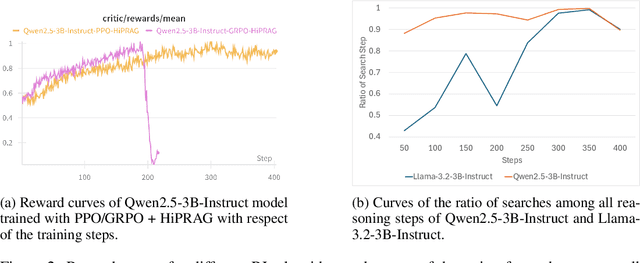
Agentic RAG is a powerful technique for incorporating external information that LLMs lack, enabling better problem solving and question answering. However, suboptimal search behaviors exist widely, such as over-search (retrieving information already known) and under-search (failing to search when necessary), which leads to unnecessary overhead and unreliable outputs. Current training methods, which typically rely on outcome-based rewards in a RL framework, lack the fine-grained control needed to address these inefficiencies. To overcome this, we introduce Hierarchical Process Rewards for Efficient agentic RAG (HiPRAG), a training methodology that incorporates a fine-grained, knowledge-grounded process reward into the RL training. Our approach evaluates the necessity of each search decision on-the-fly by decomposing the agent's reasoning trajectory into discrete, parsable steps. We then apply a hierarchical reward function that provides an additional bonus based on the proportion of optimal search and non-search steps, on top of commonly used outcome and format rewards. Experiments on the Qwen2.5 and Llama-3.2 models across seven diverse QA benchmarks show that our method achieves average accuracies of 65.4% (3B) and 67.2% (7B). This is accomplished while improving search efficiency, reducing the over-search rate to just 2.3% and concurrently lowering the under-search rate. These results demonstrate the efficacy of optimizing the reasoning process itself, not just the final outcome. Further experiments and analysis demonstrate that HiPRAG shows good generalizability across a wide range of RL algorithms, model families, sizes, and types. This work demonstrates the importance and potential of fine-grained control through RL, for improving the efficiency and optimality of reasoning for search agents.
MMTok: Multimodal Coverage Maximization for Efficient Inference of VLMs
Aug 25, 2025Vision-Language Models (VLMs) demonstrate impressive performance in understanding visual content with language instruction by converting visual input to vision tokens. However, redundancy in vision tokens results in the degenerated inference efficiency of VLMs. While many algorithms have been proposed to reduce the number of vision tokens, most of them apply only unimodal information (i.e., vision/text) for pruning and ignore the inherent multimodal property of vision-language tasks. Moreover, it lacks a generic criterion that can be applied to different modalities. To mitigate this limitation, in this work, we propose to leverage both vision and text tokens to select informative vision tokens by the criterion of coverage. We first formulate the subset selection problem as a maximum coverage problem. Afterward, a subset of vision tokens is optimized to cover the text tokens and the original set of vision tokens, simultaneously. Finally, a VLM agent can be adopted to further improve the quality of text tokens for guiding vision pruning. The proposed method MMTok is extensively evaluated on benchmark datasets with different VLMs. The comparison illustrates that vision and text information are complementary, and combining multimodal information can surpass the unimodal baseline with a clear margin. Moreover, under the maximum coverage criterion on the POPE dataset, our method achieves a 1.87x speedup while maintaining 98.7% of the original performance on LLaVA-NeXT-13B. Furthermore, with only four vision tokens, it still preserves 87.7% of the original performance on LLaVA-1.5-7B. These results highlight the effectiveness of coverage in token selection.
Complex Logical Instruction Generation
Aug 12, 2025Instruction following has catalyzed the recent era of Large Language Models (LLMs) and is the foundational skill underpinning more advanced capabilities such as reasoning and agentic behaviors. As tasks grow more challenging, the logic structures embedded in natural language instructions becomes increasingly intricate. However, how well LLMs perform on such logic-rich instructions remains under-explored. We propose LogicIFGen and LogicIFEval. LogicIFGen is a scalable, automated framework for generating verifiable instructions from code functions, which can naturally express rich logic such as conditionals, nesting, recursion, and function calls. We further curate a collection of complex code functions and use LogicIFGen to construct LogicIFEval, a benchmark comprising 426 verifiable logic-rich instructions. Our experiments demonstrate that current state-of-the-art LLMs still struggle to correctly follow the instructions in LogicIFEval. Most LLMs can only follow fewer than 60% of the instructions, revealing significant deficiencies in the instruction-following ability. Code and Benchmark: https://github.com/mianzhang/LogicIF
Search Wisely: Mitigating Sub-optimal Agentic Searches By Reducing Uncertainty
May 22, 2025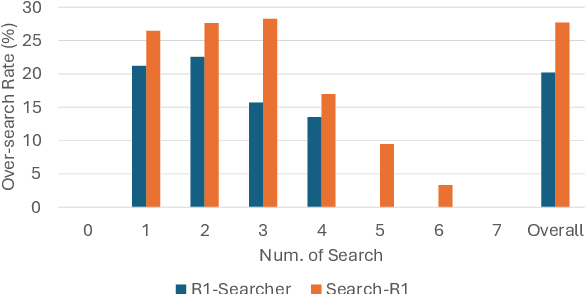
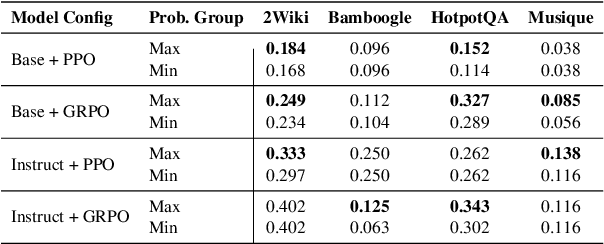
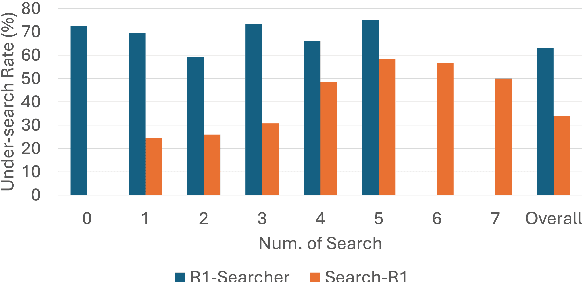
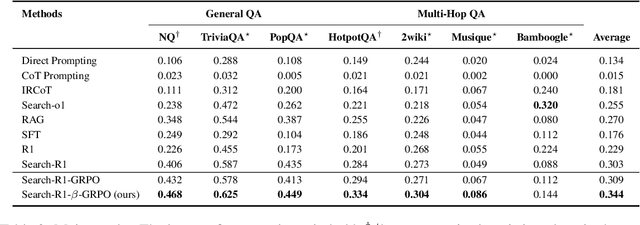
Agentic Retrieval-Augmented Generation (RAG) systems enhance Large Language Models (LLMs) by enabling dynamic, multi-step reasoning and information retrieval. However, these systems often exhibit sub-optimal search behaviors like over-search (retrieving redundant information) and under-search (failing to retrieve necessary information), which hinder efficiency and reliability. This work formally defines and quantifies these behaviors, revealing their prevalence across multiple QA datasets and agentic RAG systems (e.g., one model could have avoided searching in 27.7% of its search steps). Furthermore, we demonstrate a crucial link between these inefficiencies and the models' uncertainty regarding their own knowledge boundaries, where response accuracy correlates with model's uncertainty in its search decisions. To address this, we propose $\beta$-GRPO, a reinforcement learning-based training method that incorporates confidence threshold to reward high-certainty search decisions. Experiments on seven QA benchmarks show that $\beta$-GRPO enable a 3B model with better agentic RAG ability, outperforming other strong baselines with a 4% higher average exact match score.
Preference Learning Unlocks LLMs' Psycho-Counseling Skills
Feb 27, 2025
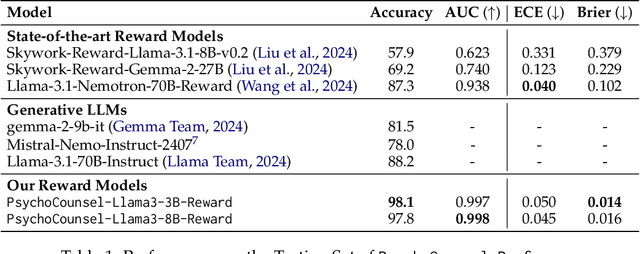
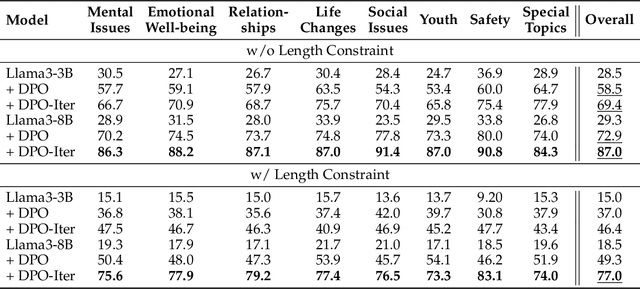
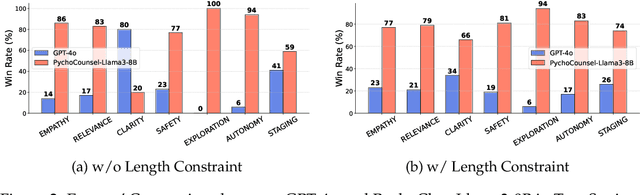
Applying large language models (LLMs) to assist in psycho-counseling is an emerging and meaningful approach, driven by the significant gap between patient needs and the availability of mental health support. However, current LLMs struggle to consistently provide effective responses to client speeches, largely due to the lack of supervision from high-quality real psycho-counseling data, whose content is typically inaccessible due to client privacy concerns. Furthermore, the quality of therapists' responses in available sessions can vary significantly based on their professional training and experience. Assessing the quality of therapists' responses remains an open challenge. In this work, we address these challenges by first proposing a set of professional and comprehensive principles to evaluate therapists' responses to client speeches. Using these principles, we create a preference dataset, PsychoCounsel-Preference, which contains 36k high-quality preference comparison pairs. This dataset aligns with the preferences of professional psychotherapists, providing a robust foundation for evaluating and improving LLMs in psycho-counseling. Experiments on reward modeling and preference learning demonstrate that PsychoCounsel-Preference is an excellent resource for LLMs to acquire essential skills for responding to clients in a counseling session. Our best-aligned model, PsychoCounsel-Llama3-8B, achieves an impressive win rate of 87% against GPT-4o. We release PsychoCounsel-Preference, PsychoCounsel-Llama3-8B and the reward model PsychoCounsel Llama3-8B-Reward to facilitate the research of psycho-counseling with LLMs at: https://hf.co/Psychotherapy-LLM.
CBT-Bench: Evaluating Large Language Models on Assisting Cognitive Behavior Therapy
Oct 17, 2024
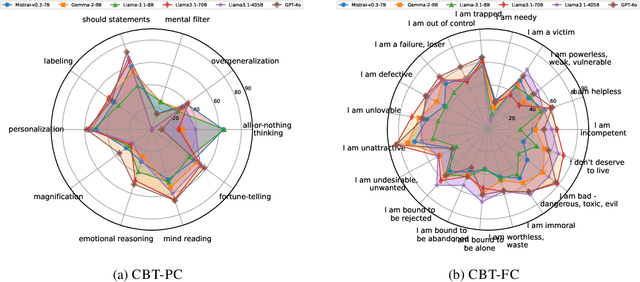

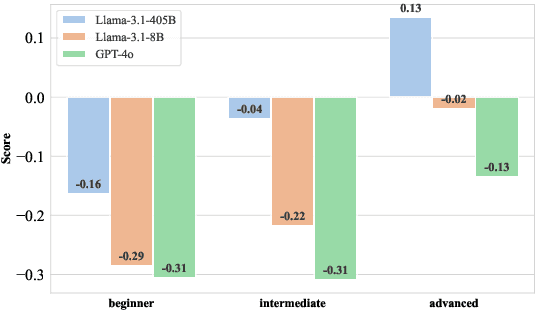
There is a significant gap between patient needs and available mental health support today. In this paper, we aim to thoroughly examine the potential of using Large Language Models (LLMs) to assist professional psychotherapy. To this end, we propose a new benchmark, CBT-BENCH, for the systematic evaluation of cognitive behavioral therapy (CBT) assistance. We include three levels of tasks in CBT-BENCH: I: Basic CBT knowledge acquisition, with the task of multiple-choice questions; II: Cognitive model understanding, with the tasks of cognitive distortion classification, primary core belief classification, and fine-grained core belief classification; III: Therapeutic response generation, with the task of generating responses to patient speech in CBT therapy sessions. These tasks encompass key aspects of CBT that could potentially be enhanced through AI assistance, while also outlining a hierarchy of capability requirements, ranging from basic knowledge recitation to engaging in real therapeutic conversations. We evaluated representative LLMs on our benchmark. Experimental results indicate that while LLMs perform well in reciting CBT knowledge, they fall short in complex real-world scenarios requiring deep analysis of patients' cognitive structures and generating effective responses, suggesting potential future work.
Large Language Models for Disease Diagnosis: A Scoping Review
Aug 27, 2024Automatic disease diagnosis has become increasingly valuable in clinical practice. The advent of large language models (LLMs) has catalyzed a paradigm shift in artificial intelligence, with growing evidence supporting the efficacy of LLMs in diagnostic tasks. Despite the growing attention in this field, many critical research questions remain under-explored. For instance, what diseases and LLM techniques have been investigated for diagnostic tasks? How can suitable LLM techniques and evaluation methods be selected for clinical decision-making? To answer these questions, we performed a comprehensive analysis of LLM-based methods for disease diagnosis. This scoping review examined the types of diseases, associated organ systems, relevant clinical data, LLM techniques, and evaluation methods reported in existing studies. Furthermore, we offered guidelines for data preprocessing and the selection of appropriate LLM techniques and evaluation strategies for diagnostic tasks. We also assessed the limitations of current research and delineated the challenges and future directions in this research field. In summary, our review outlined a blueprint for LLM-based disease diagnosis, helping to streamline and guide future research endeavors.
Inconsistent dialogue responses and how to recover from them
Jan 18, 2024One critical issue for chat systems is to stay consistent about preferences, opinions, beliefs and facts of itself, which has been shown a difficult problem. In this work, we study methods to assess and bolster utterance consistency of chat systems. A dataset is first developed for studying the inconsistencies, where inconsistent dialogue responses, explanations of the inconsistencies, and recovery utterances are authored by annotators. This covers the life span of inconsistencies, namely introduction, understanding, and resolution. Building on this, we introduce a set of tasks centered on dialogue consistency, specifically focused on its detection and resolution. Our experimental findings indicate that our dataset significantly helps the progress in identifying and resolving conversational inconsistencies, and current popular large language models like ChatGPT which are good at resolving inconsistencies however still struggle with detection.
A Pairing Enhancement Approach for Aspect Sentiment Triplet Extraction
Jun 11, 2023



Aspect Sentiment Triplet Extraction (ASTE) aims to extract the triplet of an aspect term, an opinion term, and their corresponding sentiment polarity from the review texts. Due to the complexity of language and the existence of multiple aspect terms and opinion terms in a single sentence, current models often confuse the connections between an aspect term and the opinion term describing it. To address this issue, we propose a pairing enhancement approach for ASTE, which incorporates contrastive learning during the training stage to inject aspect-opinion pairing knowledge into the triplet extraction model. Experimental results demonstrate that our approach performs well on four ASTE datasets (i.e., 14lap, 14res, 15res and 16res) compared to several related classical and state-of-the-art triplet extraction methods. Moreover, ablation studies conduct an analysis and verify the advantage of contrastive learning over other pairing enhancement approaches.
Friend-training: Learning from Models of Different but Related Tasks
Jan 31, 2023
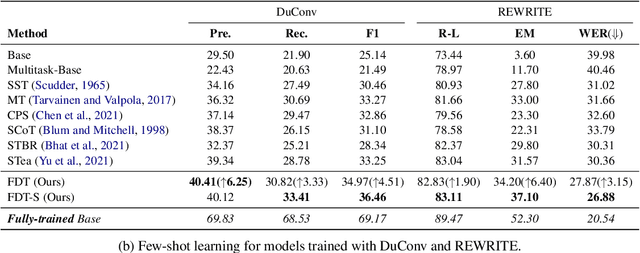


Current self-training methods such as standard self-training, co-training, tri-training, and others often focus on improving model performance on a single task, utilizing differences in input features, model architectures, and training processes. However, many tasks in natural language processing are about different but related aspects of language, and models trained for one task can be great teachers for other related tasks. In this work, we propose friend-training, a cross-task self-training framework, where models trained to do different tasks are used in an iterative training, pseudo-labeling, and retraining process to help each other for better selection of pseudo-labels. With two dialogue understanding tasks, conversational semantic role labeling and dialogue rewriting, chosen for a case study, we show that the models trained with the friend-training framework achieve the best performance compared to strong baselines.