 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastive Learning Subspace for Text Clustering
Aug 26, 2024
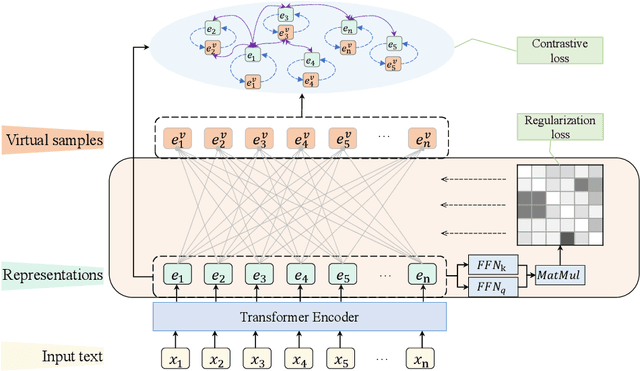
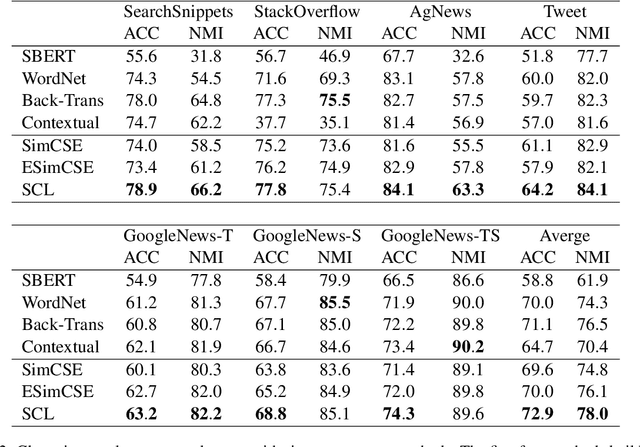
Contrastive learning has been frequently investigated to learn effective representations for text clustering tasks. While existing contrastive learning-based text clustering methods only focus on modeling instance-wise semantic similarity relationships, they ignore contextual information and underlying relationships among all instances that needs to be clustered. In this paper, we propose a novel text clustering approach called Subspace Contrastive Learning (SCL) which models cluster-wise relationships among instances. Specifically, the proposed SCL consists of two main modules: (1) a self-expressive module that constructs virtual positive samples and (2) a contrastive learning module that further learns a discriminative subspace to capture task-specific cluster-wise relationships among texts. Experimental results show that the proposed SCL method not only has achieved superior results on multiple task clustering datasets but also has less complexity in positive sample construction.
G-SPEED: General SParse Efficient Editing MoDel
Oct 16, 2023



Large Language Models~(LLMs) have demonstrated incredible capabilities in understanding, generating, and manipulating languages. Through human-model interactions, LLMs can automatically understand human-issued instructions and output the expected contents, which can significantly increase working efficiency. In various types of real-world demands, editing-oriented tasks account for a considerable proportion, which involves an interactive process that entails the continuous refinement of existing texts to meet specific criteria. Due to the need for multi-round human-model interaction and the generation of complicated editing tasks, there is an emergent need for efficient general editing models. In this paper, we propose \underline{\textbf{G}}eneral \underline{\textbf{SP}}arse \underline{\textbf{E}}fficient \underline{\textbf{E}}diting Mo\underline{\textbf{D}}el~(\textbf{G-SPEED}), which can fulfill diverse editing requirements through a single model while maintaining low computational costs. Specifically, we first propose a novel unsupervised text editing data clustering algorithm to deal with the data scarcity problem. Subsequently, we introduce a sparse editing model architecture to mitigate the inherently limited learning capabilities of small language models. The experimental outcomes indicate that G-SPEED, with its 508M parameters, can surpass LLMs equipped with 175B parameters. Our code and model checkpoints are available at \url{https://github.com/Banner-Z/G-SPEED}.
A Pairing Enhancement Approach for Aspect Sentiment Triplet Extraction
Jun 11, 2023



Aspect Sentiment Triplet Extraction (ASTE) aims to extract the triplet of an aspect term, an opinion term, and their corresponding sentiment polarity from the review texts. Due to the complexity of language and the existence of multiple aspect terms and opinion terms in a single sentence, current models often confuse the connections between an aspect term and the opinion term describing it. To address this issue, we propose a pairing enhancement approach for ASTE, which incorporates contrastive learning during the training stage to inject aspect-opinion pairing knowledge into the triplet extraction model. Experimental results demonstrate that our approach performs well on four ASTE datasets (i.e., 14lap, 14res, 15res and 16res) compared to several related classical and state-of-the-art triplet extraction methods. Moreover, ablation studies conduct an analysis and verify the advantage of contrastive learning over other pairing enhancement approaches.
Friend-training: Learning from Models of Different but Related Tasks
Jan 31, 2023
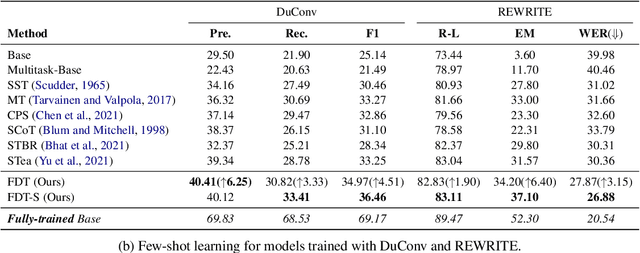


Current self-training methods such as standard self-training, co-training, tri-training, and others often focus on improving model performance on a single task, utilizing differences in input features, model architectures, and training processes. However, many tasks in natural language processing are about different but related aspects of language, and models trained for one task can be great teachers for other related tasks. In this work, we propose friend-training, a cross-task self-training framework, where models trained to do different tasks are used in an iterative training, pseudo-labeling, and retraining process to help each other for better selection of pseudo-labels. With two dialogue understanding tasks, conversational semantic role labeling and dialogue rewriting, chosen for a case study, we show that the models trained with the friend-training framework achieve the best performance compared to strong baselines.
Towards Accurate and Consistent Evaluation: A Dataset for Distantly-Supervised Relation Extraction
Oct 30, 2020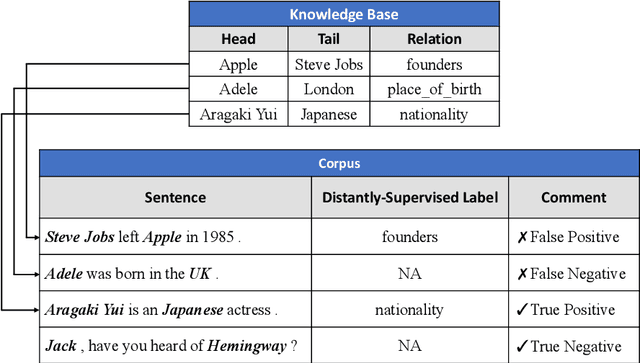

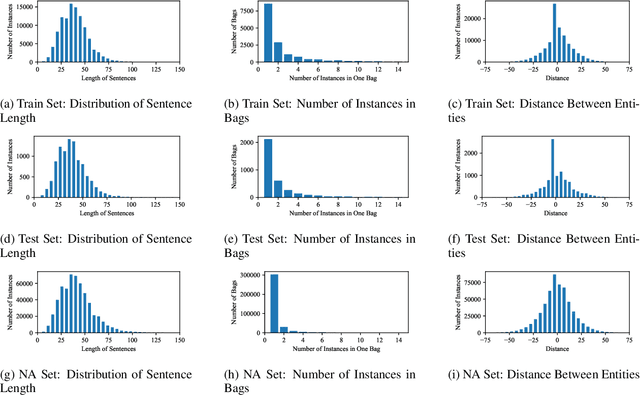
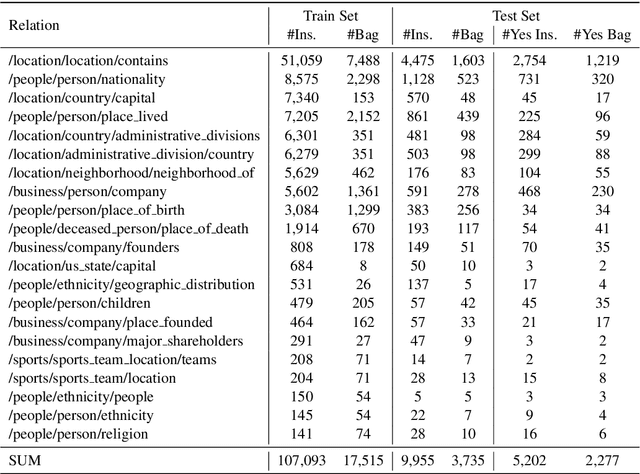
In recent years, distantly-supervised relation extraction has achieved a certain success by using deep neural networks. Distant Supervision (DS) can automatically generate large-scale annotated data by aligning entity pairs from Knowledge Bases (KB) to sentences. However, these DS-generated datasets inevitably have wrong labels that result in incorrect evaluation scores during testing, which may mislead the researchers. To solve this problem, we build a new dataset NYTH, where we use the DS-generated data as training data and hire annotators to label test data. Compared with the previous datasets, NYT-H has a much larger test set and then we can perform more accurate and consistent evaluation. Finally, we present the experimental results of several widely used systems on NYT-H. The experimental results show that the ranking lists of the comparison systems on the DS-labelled test data and human-annotated test data are different. This indicates that our human-annotated data is necessary for evaluation of distantly-supervised relation extraction.
Emotion Detection with Neural Personal Discrimination
Aug 28, 2019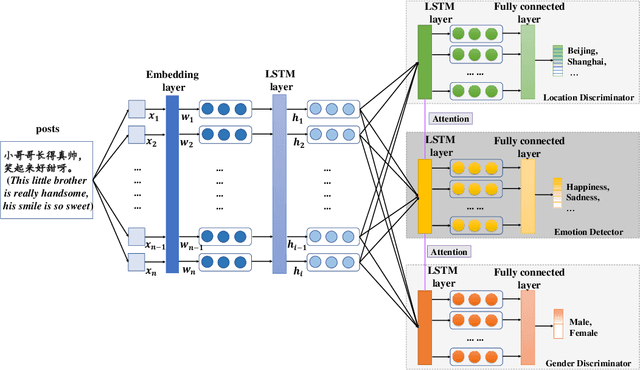
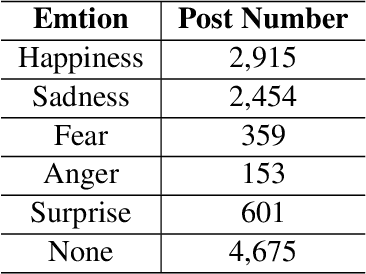
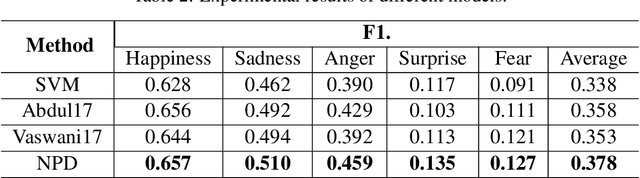
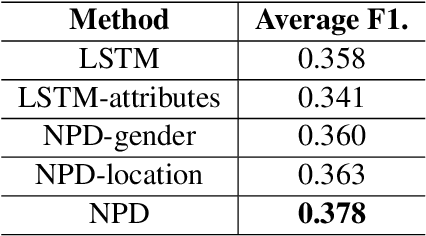
There have been a recent line of works to automatically predict the emotions of posts in social media. Existing approaches consider the posts individually and predict their emotions independently. Different from previous researches, we explore the dependence among relevant posts via the authors' backgrounds, since the authors with similar backgrounds, e.g., gender, location, tend to express similar emotions. However, such personal attributes are not easy to obtain in most social media websites, and it is hard to capture attributes-aware words to connect similar people. Accordingly, we propose a Neural Personal Discrimination (NPD) approach to address above challenges by determining personal attributes from posts, and connecting relevant posts with similar attributes to jointly learn their emotions. In particular, we employ adversarial discriminators to determine the personal attributes, with attention mechanisms to aggregate attributes-aware words. In this way, social correlationship among different posts can be better addressed. Experimental results show the usefulness of personal attributes, and the effectiveness of our proposed NPD approach in capturing such personal attributes with significant gains over the state-of-the-art models.