 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabEmbed: Benchmarking and Learning Generalist Embeddings for Tabular Understanding
May 06, 2026Foundation models have established unified representations for natural language processing, yet this paradigm remains largely unexplored for tabular data. Existing methods face fundamental limitations: LLM-based approaches lack retrieval-compatible vector outputs, whereas text embedding models often fail to capture tabular structure and numerical semantics. To bridge this gap, we first introduce the Tabular Embedding Benchmark (TabBench), a comprehensive suite designed to evaluate the tabular understanding capability of embedding models. We then propose TabEmbed, the first generalist embedding model that unifies tabular classification and retrieval within a shared embedding space. By reformulating diverse tabular tasks as semantic matching problems, TabEmbed leverages large-scale contrastive learning with positive-aware hard negative mining to discern fine-grained structural and numerical nuances. Experimental results on TabBench demonstrate that TabEmbed significantly outperforms state-of-the-art text embedding models, establishing a new baseline for universal tabular representation learning. Code and datasets are publicly available at https://github.com/qiangminjie27/TabEmbed and https://huggingface.co/datasets/qiangminjie27/TabBench.
PCoKG: Personality-aware Commonsense Reasoning with Debate
Jan 09, 2026Most commonsense reasoning models overlook the influence of personality traits, limiting their effectiveness in personalized systems such as dialogue generation. To address this limitation, we introduce the Personality-aware Commonsense Knowledge Graph (PCoKG), a structured dataset comprising 521,316 quadruples. We begin by employing three evaluators to score and filter events from the ATOMIC dataset, selecting those that are likely to elicit diverse reasoning patterns across different personality types. For knowledge graph construction, we leverage the role-playing capabilities of large language models (LLMs) to perform reasoning tasks. To enhance the quality of the generated knowledge, we incorporate a debate mechanism consisting of a proponent, an opponent, and a judge, which iteratively refines the outputs through feedback loops. We evaluate the dataset from multiple perspectives and conduct fine-tuning and ablation experiments using multiple LLM backbones to assess PCoKG's robustness and the effectiveness of its construction pipeline. Our LoRA-based fine-tuning results indicate a positive correlation between model performance and the parameter scale of the base models. Finally, we apply PCoKG to persona-based dialogue generation, where it demonstrates improved consistency between generated responses and reference outputs. This work bridges the gap between commonsense reasoning and individual cognitive differences, enabling the development of more personalized and context-aware AI systems.
Exploring Model Editing for LLM-based Aspect-Based Sentiment Classification
Mar 19, 2025



Model editing aims at selectively updating a small subset of a neural model's parameters with an interpretable strategy to achieve desired modifications. It can significantly reduce computational costs to adapt to large language models (LLMs). Given its ability to precisely target critical components within LLMs, model editing shows great potential for efficient fine-tuning applications. In this work, we investigate model editing to serve an efficient method for adapting LLMs to solve aspect-based sentiment classification. Through causal interventions, we trace and determine which neuron hidden states are essential for the prediction of the model. By performing interventions and restorations on each component of an LLM, we identify the importance of these components for aspect-based sentiment classification. Our findings reveal that a distinct set of mid-layer representations is essential for detecting the sentiment polarity of given aspect words. Leveraging these insights, we develop a model editing approach that focuses exclusively on these critical parts of the LLM, leading to a more efficient method for adapting LLMs. Our in-domain and out-of-domain experiments demonstrate that this approach achieves competitive results compared to the currently strongest methods with significantly fewer trainable parameters, highlighting a more efficient and interpretable fine-tuning strategy.
Constituency Parsing using LLMs
Oct 31, 2023Constituency parsing is a fundamental yet unsolved natural language processing task. In this paper, we explore the potential of recent large language models (LLMs) that have exhibited remarkable performance across various domains and tasks to tackle this task. We employ three linearization strategies to transform output trees into symbol sequences, such that LLMs can solve constituency parsing by generating linearized trees. We conduct experiments using a diverse range of LLMs, including ChatGPT, GPT-4, OPT, LLaMA, and Alpaca, comparing their performance against the state-of-the-art constituency parsers. Our experiments encompass zero-shot, few-shot, and full-training learning settings, and we evaluate the models on one in-domain and five out-of-domain test datasets. Our findings reveal insights into LLMs' performance, generalization abilities, and challenges in constituency parsing.
Opinion Tree Parsing for Aspect-based Sentiment Analysis
Jun 15, 2023Extracting sentiment elements using pre-trained generative models has recently led to large improvements in aspect-based sentiment analysis benchmarks. However, these models always need large-scale computing resources, and they also ignore explicit modeling of structure between sentiment elements. To address these challenges, we propose an opinion tree parsing model, aiming to parse all the sentiment elements from an opinion tree, which is much faster, and can explicitly reveal a more comprehensive and complete aspect-level sentiment structure. In particular, we first introduce a novel context-free opinion grammar to normalize the opinion tree structure. We then employ a neural chart-based opinion tree parser to fully explore the correlations among sentiment elements and parse them into an opinion tree structure. Extensive experiments show the superiority of our proposed model and the capacity of the opinion tree parser with the proposed context-free opinion grammar. More importantly, the results also prove that our model is much faster than previous models.
SGPT: Semantic Graphs based Pre-training for Aspect-based Sentiment Analysis
May 26, 2021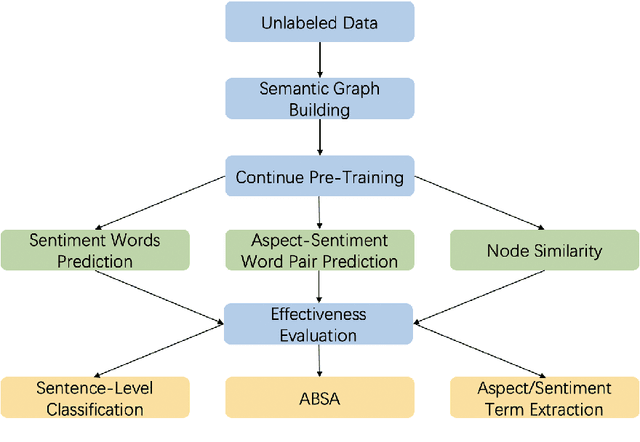
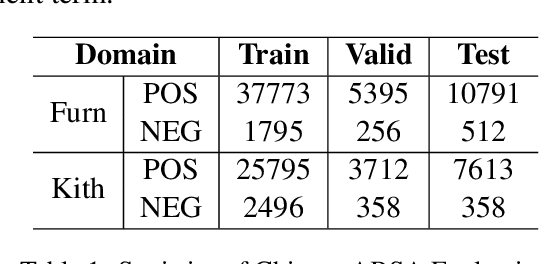
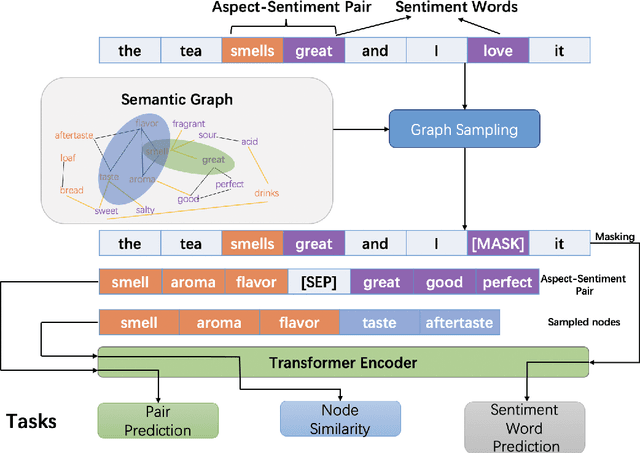
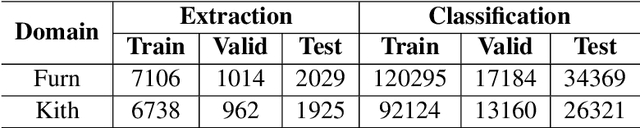
Previous studies show effective of pre-trained language models for sentiment analysis. However, most of these studies ignore the importance of sentimental information for pre-trained models.Therefore, we fully investigate the sentimental information for pre-trained models and enhance pre-trained language models with semantic graphs for sentiment analysis.In particular, we introduce Semantic Graphs based Pre-training(SGPT) using semantic graphs to obtain synonym knowledge for aspect-sentiment pairs and similar aspect/sentiment terms.We then optimize the pre-trained language model with the semantic graphs.Empirical studies on several downstream tasks show that proposed model outperforms strong pre-trained baselines. The results also show the effectiveness of proposed semantic graphs for pre-trained model.
Emotion Detection with Neural Personal Discrimination
Aug 28, 2019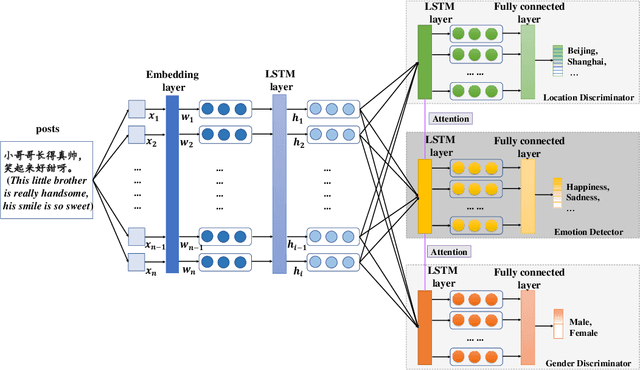
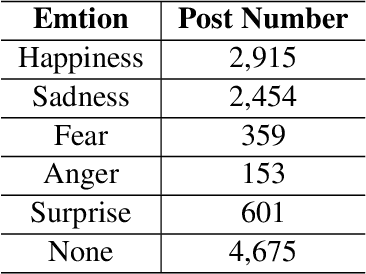
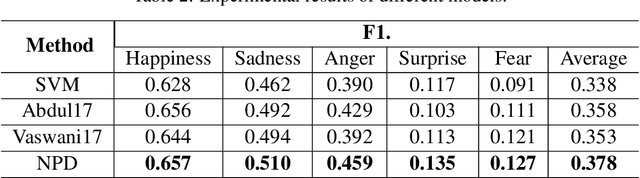
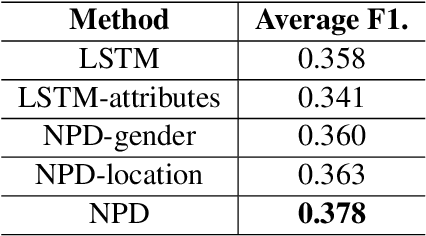
There have been a recent line of works to automatically predict the emotions of posts in social media. Existing approaches consider the posts individually and predict their emotions independently. Different from previous researches, we explore the dependence among relevant posts via the authors' backgrounds, since the authors with similar backgrounds, e.g., gender, location, tend to express similar emotions. However, such personal attributes are not easy to obtain in most social media websites, and it is hard to capture attributes-aware words to connect similar people. Accordingly, we propose a Neural Personal Discrimination (NPD) approach to address above challenges by determining personal attributes from posts, and connecting relevant posts with similar attributes to jointly learn their emotions. In particular, we employ adversarial discriminators to determine the personal attributes, with attention mechanisms to aggregate attributes-aware words. In this way, social correlationship among different posts can be better addressed. Experimental results show the usefulness of personal attributes, and the effectiveness of our proposed NPD approach in capturing such personal attributes with significant gains over the state-of-the-art models.
Opinion Recommendation using Neural Memory Model
Feb 06, 2017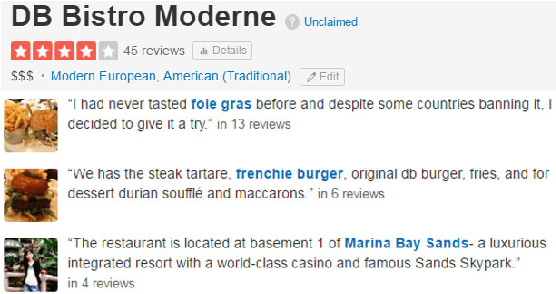
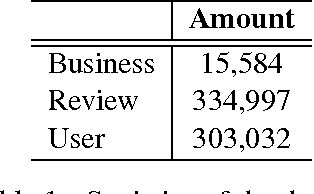
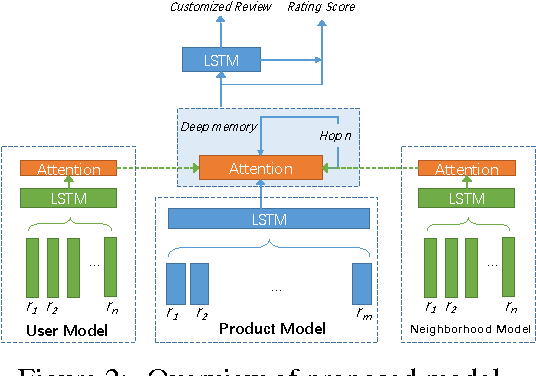
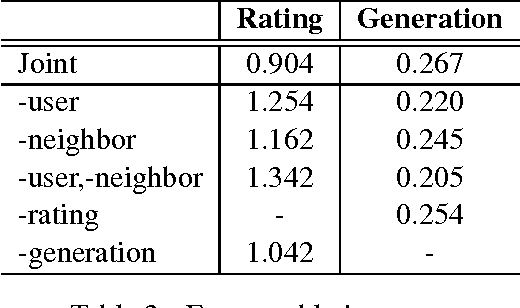
We present opinion recommendation, a novel task of jointly predicting a custom review with a rating score that a certain user would give to a certain product or service, given existing reviews and rating scores to the product or service by other users, and the reviews that the user has given to other products and services. A characteristic of opinion recommendation is the reliance of multiple data sources for multi-task joint learning, which is the strength of neural models. We use a single neural network to model users and products, capturing their correlation and generating customised product representations using a deep memory network, from which customised ratings and reviews are constructed jointly. Results show that our opinion recommendation system gives ratings that are closer to real user ratings on Yelp.com data compared with Yelp's own ratings, and our methods give better results compared to several pipelines baselines using state-of-the-art sentiment rating and summarization systems.