 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCertifiably Safe Manipulation of Deformable Linear Objects via Joint Shape and Tension Prediction
May 20, 2025



Manipulating deformable linear objects (DLOs) is challenging due to their complex dynamics and the need for safe interaction in contact-rich environments. Most existing models focus on shape prediction alone and fail to account for contact and tension constraints, which can lead to damage to both the DLO and the robot. In this work, we propose a certifiably safe motion planning and control framework for DLO manipulation. At the core of our method is a predictive model that jointly estimates the DLO's future shape and tension. These predictions are integrated into a real-time trajectory optimizer based on polynomial zonotopes, allowing us to enforce safety constraints throughout the execution. We evaluate our framework on a simulated wire harness assembly task using a 7-DOF robotic arm. Compared to state-of-the-art methods, our approach achieves a higher task success rate while avoiding all safety violations. The results demonstrate that our method enables robust and safe DLO manipulation in contact-rich environments.
XPG-RL: Reinforcement Learning with Explainable Priority Guidance for Efficiency-Boosted Mechanical Search
Apr 29, 2025Mechanical search (MS) in cluttered environments remains a significant challenge for autonomous manipulators, requiring long-horizon planning and robust state estimation under occlusions and partial observability. In this work, we introduce XPG-RL, a reinforcement learning framework that enables agents to efficiently perform MS tasks through explainable, priority-guided decision-making based on raw sensory inputs. XPG-RL integrates a task-driven action prioritization mechanism with a learned context-aware switching strategy that dynamically selects from a discrete set of action primitives such as target grasping, occlusion removal, and viewpoint adjustment. Within this strategy, a policy is optimized to output adaptive threshold values that govern the discrete selection among action primitives. The perception module fuses RGB-D inputs with semantic and geometric features to produce a structured scene representation for downstream decision-making. Extensive experiments in both simulation and real-world settings demonstrate that XPG-RL consistently outperforms baseline methods in task success rates and motion efficiency, achieving up to 4.5$\times$ higher efficiency in long-horizon tasks. These results underscore the benefits of integrating domain knowledge with learnable decision-making policies for robust and efficient robotic manipulation.
Multi-Modal Fusion of In-Situ Video Data and Process Parameters for Online Forecasting of Cookie Drying Readiness
Apr 22, 2025
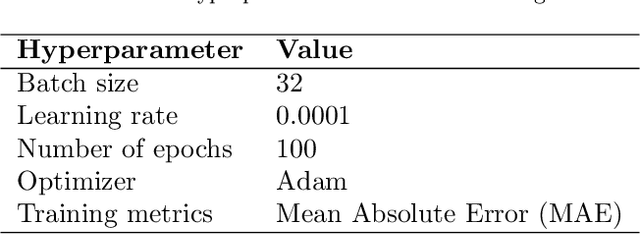
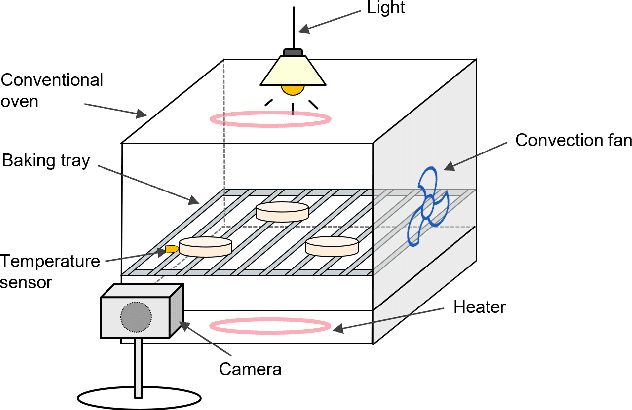
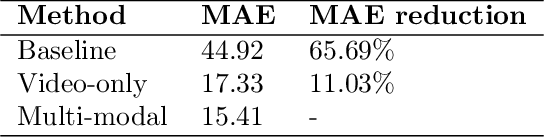
Food drying is essential for food production, extending shelf life, and reducing transportation costs. Accurate real-time forecasting of drying readiness is crucial for minimizing energy consumption, improving productivity, and ensuring product quality. However, this remains challenging due to the dynamic nature of drying, limited data availability, and the lack of effective predictive analytical methods. To address this gap, we propose an end-to-end multi-modal data fusion framework that integrates in-situ video data with process parameters for real-time food drying readiness forecasting. Our approach leverages a new encoder-decoder architecture with modality-specific encoders and a transformer-based decoder to effectively extract features while preserving the unique structure of each modality. We apply our approach to sugar cookie drying, where time-to-ready is predicted at each timestamp. Experimental results demonstrate that our model achieves an average prediction error of only 15 seconds, outperforming state-of-the-art data fusion methods by 65.69% and a video-only model by 11.30%. Additionally, our model balances prediction accuracy, model size, and computational efficiency, making it well-suited for heterogenous industrial datasets. The proposed model is extensible to various other industrial modality fusion tasks for online decision-making.
Multi-Modal Data Fusion for Moisture Content Prediction in Apple Drying
Apr 10, 2025

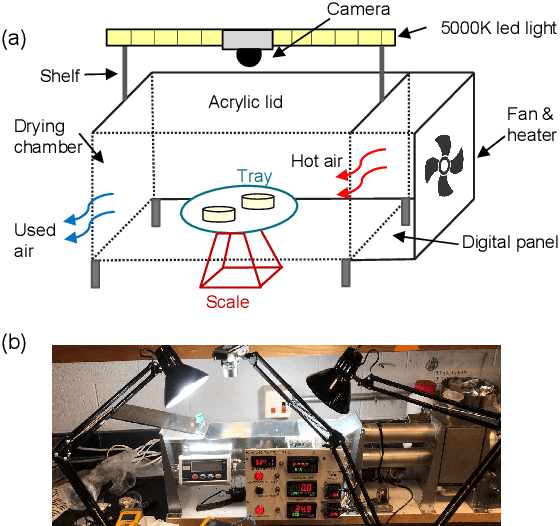
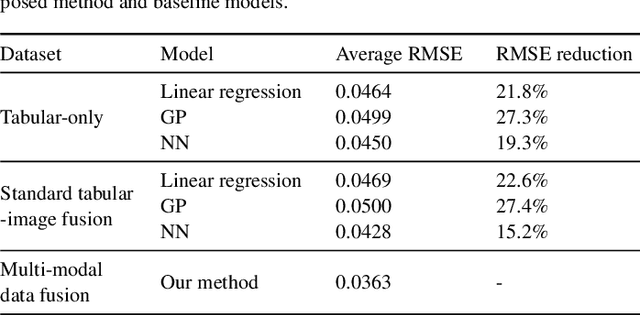
Fruit drying is widely used in food manufacturing to reduce product moisture, ensure product safety, and extend product shelf life. Accurately predicting final moisture content (MC) is critically needed for quality control of drying processes. State-of-the-art methods can build deterministic relationships between process parameters and MC, but cannot adequately account for inherent process variabilities that are ubiquitous in fruit drying. To address this gap, this paper presents a novel multi-modal data fusion framework to effectively fuse two modalities of data: tabular data (process parameters) and high-dimensional image data (images of dried apple slices) to enable accurate MC prediction. The proposed modeling architecture permits flexible adjustment of information portion from tabular and image data modalities. Experimental validation shows that the multi-modal approach improves predictive accuracy substantially compared to state-of-the-art methods. The proposed method reduces root-mean-squared errors by 19.3%, 24.2%, and 15.2% over tabular-only, image-only, and standard tabular-image fusion models, respectively. Furthermore, it is demonstrated that our method is robust in varied tabular-image ratios and capable of effectively capturing inherent small-scale process variabilities. The proposed framework is extensible to a variety of other drying technologies.
Exploring Model Editing for LLM-based Aspect-Based Sentiment Classification
Mar 19, 2025



Model editing aims at selectively updating a small subset of a neural model's parameters with an interpretable strategy to achieve desired modifications. It can significantly reduce computational costs to adapt to large language models (LLMs). Given its ability to precisely target critical components within LLMs, model editing shows great potential for efficient fine-tuning applications. In this work, we investigate model editing to serve an efficient method for adapting LLMs to solve aspect-based sentiment classification. Through causal interventions, we trace and determine which neuron hidden states are essential for the prediction of the model. By performing interventions and restorations on each component of an LLM, we identify the importance of these components for aspect-based sentiment classification. Our findings reveal that a distinct set of mid-layer representations is essential for detecting the sentiment polarity of given aspect words. Leveraging these insights, we develop a model editing approach that focuses exclusively on these critical parts of the LLM, leading to a more efficient method for adapting LLMs. Our in-domain and out-of-domain experiments demonstrate that this approach achieves competitive results compared to the currently strongest methods with significantly fewer trainable parameters, highlighting a more efficient and interpretable fine-tuning strategy.
Self-Training with Direct Preference Optimization Improves Chain-of-Thought Reasoning
Jul 25, 2024



Effective training of language models (LMs) for mathematical reasoning tasks demands high-quality supervised fine-tuning data. Besides obtaining annotations from human experts, a common alternative is sampling from larger and more powerful LMs. However, this knowledge distillation approach can be costly and unstable, particularly when relying on closed-source, proprietary LMs like GPT-4, whose behaviors are often unpredictable. In this work, we demonstrate that the reasoning abilities of small-scale LMs can be enhanced through self-training, a process where models learn from their own outputs. We also show that the conventional self-training can be further augmented by a preference learning algorithm called Direct Preference Optimization (DPO). By integrating DPO into self-training, we leverage preference data to guide LMs towards more accurate and diverse chain-of-thought reasoning. We evaluate our method across various mathematical reasoning tasks using different base models. Our experiments show that this approach not only improves LMs' reasoning performance but also offers a more cost-effective and scalable solution compared to relying on large proprietary LMs.
An Unsupervised Learning Method with Convolutional Auto-Encoder for Vessel Trajectory Similarity Computation
Jan 10, 2021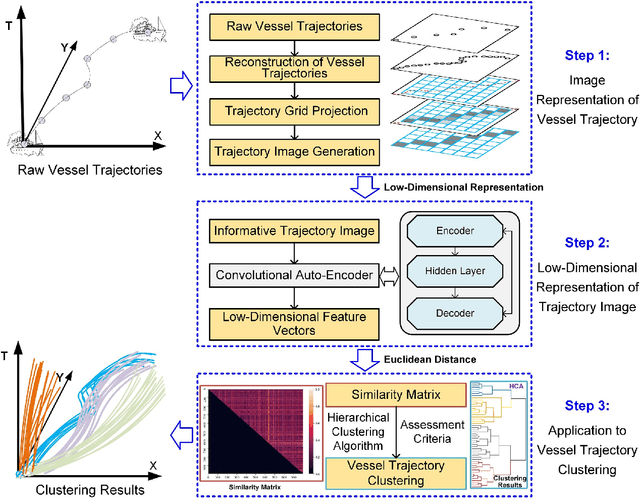
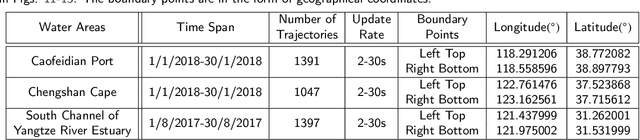
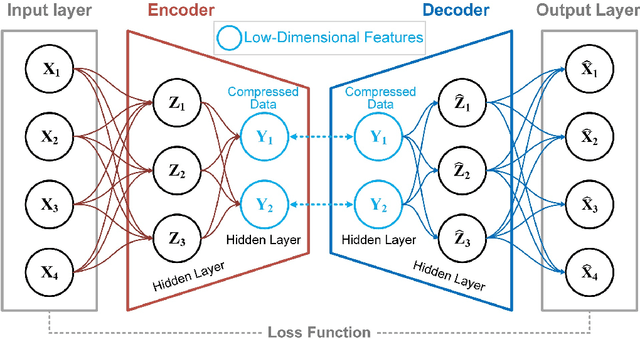
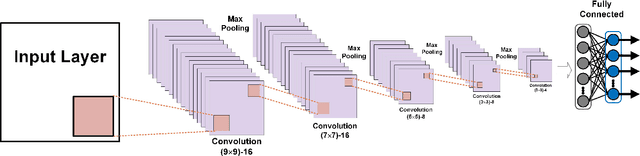
To achieve reliable mining results for massive vessel trajectories, one of the most important challenges is how to efficiently compute the similarities between different vessel trajectories. The computation of vessel trajectory similarity has recently attracted increasing attention in the maritime data mining research community. However, traditional shape- and warping-based methods often suffer from several drawbacks such as high computational cost and sensitivity to unwanted artifacts and non-uniform sampling rates, etc. To eliminate these drawbacks, we propose an unsupervised learning method which automatically extracts low-dimensional features through a convolutional auto-encoder (CAE). In particular, we first generate the informative trajectory images by remapping the raw vessel trajectories into two-dimensional matrices while maintaining the spatio-temporal properties. Based on the massive vessel trajectories collected, the CAE can learn the low-dimensional representations of informative trajectory images in an unsupervised manner. The trajectory similarity is finally equivalent to efficiently computing the similarities between the learned low-dimensional features, which strongly correlate with the raw vessel trajectories. Comprehensive experiments on realistic data sets have demonstrated that the proposed method largely outperforms traditional trajectory similarity computation methods in terms of efficiency and effectiveness. The high-quality trajectory clustering performance could also be guaranteed according to the CAE-based trajectory similarity computation results.