 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeXPG-RL: Reinforcement Learning with Explainable Priority Guidance for Efficiency-Boosted Mechanical Search
Apr 29, 2025Mechanical search (MS) in cluttered environments remains a significant challenge for autonomous manipulators, requiring long-horizon planning and robust state estimation under occlusions and partial observability. In this work, we introduce XPG-RL, a reinforcement learning framework that enables agents to efficiently perform MS tasks through explainable, priority-guided decision-making based on raw sensory inputs. XPG-RL integrates a task-driven action prioritization mechanism with a learned context-aware switching strategy that dynamically selects from a discrete set of action primitives such as target grasping, occlusion removal, and viewpoint adjustment. Within this strategy, a policy is optimized to output adaptive threshold values that govern the discrete selection among action primitives. The perception module fuses RGB-D inputs with semantic and geometric features to produce a structured scene representation for downstream decision-making. Extensive experiments in both simulation and real-world settings demonstrate that XPG-RL consistently outperforms baseline methods in task success rates and motion efficiency, achieving up to 4.5$\times$ higher efficiency in long-horizon tasks. These results underscore the benefits of integrating domain knowledge with learnable decision-making policies for robust and efficient robotic manipulation.
Sense, Imagine, Act: Multimodal Perception Improves Model-Based Reinforcement Learning for Head-to-Head Autonomous Racing
May 08, 2023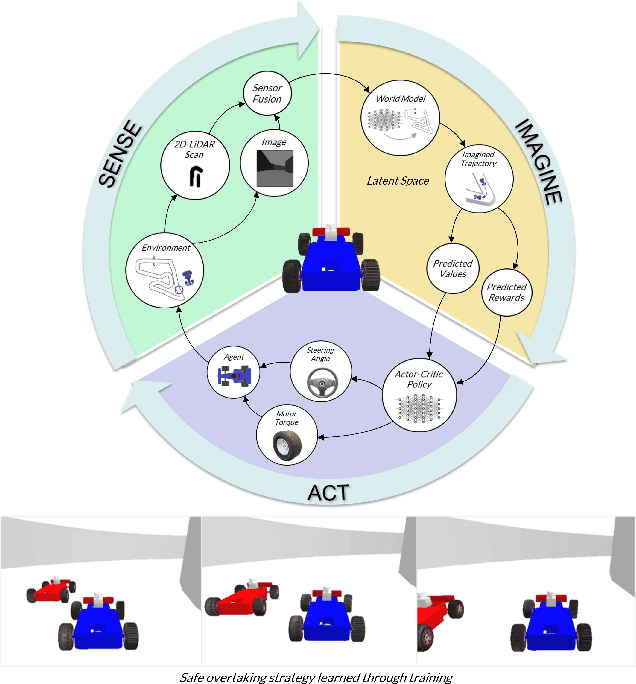
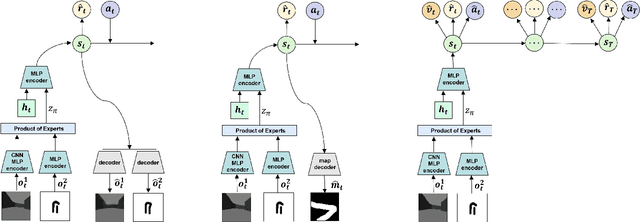

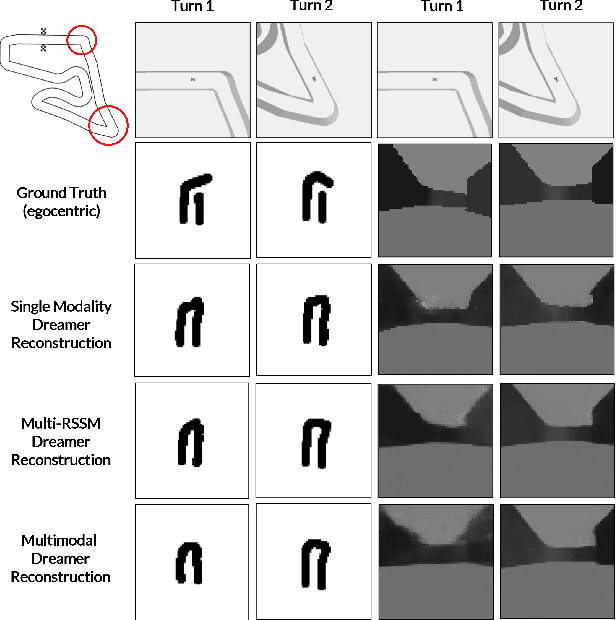
Model-based reinforcement learning (MBRL) techniques have recently yielded promising results for real-world autonomous racing using high-dimensional observations. MBRL agents, such as Dreamer, solve long-horizon tasks by building a world model and planning actions by latent imagination. This approach involves explicitly learning a model of the system dynamics and using it to learn the optimal policy for continuous control over multiple timesteps. As a result, MBRL agents may converge to sub-optimal policies if the world model is inaccurate. To improve state estimation for autonomous racing, this paper proposes a self-supervised sensor fusion technique that combines egocentric LiDAR and RGB camera observations collected from the F1TENTH Gym. The zero-shot performance of MBRL agents is empirically evaluated on unseen tracks and against a dynamic obstacle. This paper illustrates that multimodal perception improves robustness of the world model without requiring additional training data. The resulting multimodal Dreamer agent safely avoided collisions and won the most races compared to other tested baselines in zero-shot head-to-head autonomous racing.