 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDemystifying Deep Reinforcement Learning-Based Autonomous Vehicle Decision-Making
Mar 18, 2024With the advent of universal function approximators in the domain of reinforcement learning, the number of practical applications leveraging deep reinforcement learning (DRL) has exploded. Decision-making in automated driving tasks has emerged as a chief application among them, taking the sensor data or the higher-order kinematic variables as the input and providing a discrete choice or continuous control output. However, the black-box nature of the models presents an overwhelming limitation that restricts the real-world deployment of DRL in autonomous vehicles (AVs). Therefore, in this research work, we focus on the interpretability of an attention-based DRL framework. We use a continuous proximal policy optimization-based DRL algorithm as the baseline model and add a multi-head attention framework in an open-source AV simulation environment. We provide some analytical techniques for discussing the interpretability of the trained models in terms of explainability and causality for spatial and temporal correlations. We show that the weights in the first head encode the positions of the neighboring vehicles while the second head focuses on the leader vehicle exclusively. Also, the ego vehicle's action is causally dependent on the vehicles in the target lane spatially and temporally. Through these findings, we reliably show that these techniques can help practitioners decipher the results of the DRL algorithms.
Sense, Imagine, Act: Multimodal Perception Improves Model-Based Reinforcement Learning for Head-to-Head Autonomous Racing
May 08, 2023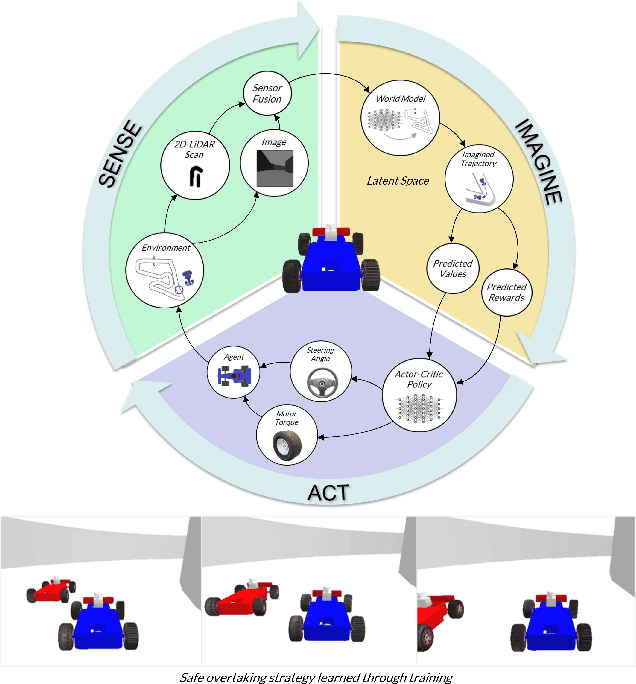
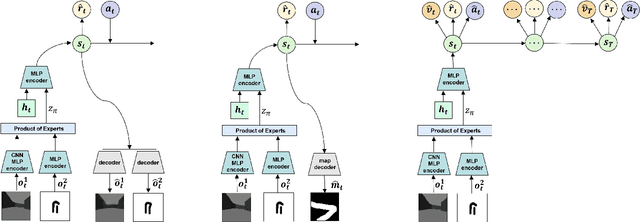

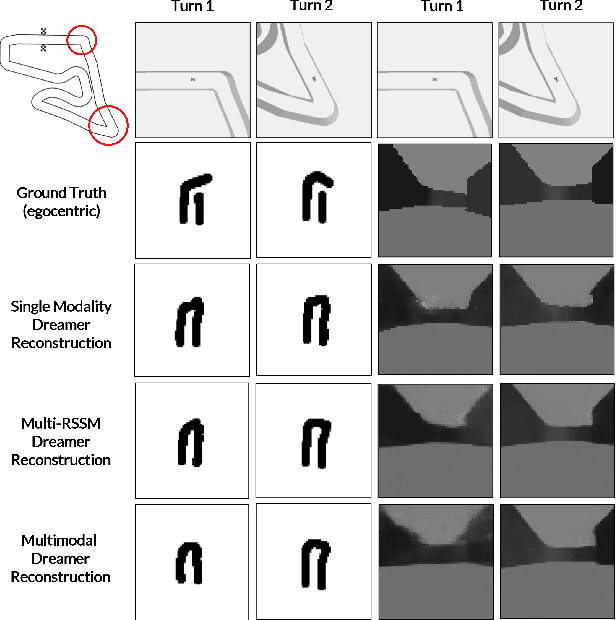
Model-based reinforcement learning (MBRL) techniques have recently yielded promising results for real-world autonomous racing using high-dimensional observations. MBRL agents, such as Dreamer, solve long-horizon tasks by building a world model and planning actions by latent imagination. This approach involves explicitly learning a model of the system dynamics and using it to learn the optimal policy for continuous control over multiple timesteps. As a result, MBRL agents may converge to sub-optimal policies if the world model is inaccurate. To improve state estimation for autonomous racing, this paper proposes a self-supervised sensor fusion technique that combines egocentric LiDAR and RGB camera observations collected from the F1TENTH Gym. The zero-shot performance of MBRL agents is empirically evaluated on unseen tracks and against a dynamic obstacle. This paper illustrates that multimodal perception improves robustness of the world model without requiring additional training data. The resulting multimodal Dreamer agent safely avoided collisions and won the most races compared to other tested baselines in zero-shot head-to-head autonomous racing.