 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhen to Trust Tools? Adaptive Tool Trust Calibration For Tool-Integrated Math Reasoning
Apr 09, 2026Large reasoning models (LRMs) have achieved strong performance enhancement through scaling test time computation, but due to the inherent limitations of the underlying language models, they still have shortcomings in tasks that require precise computation and extensive knowledge reserves. Tool-Integrated Reasoning (TIR) has emerged as a promising paradigm that incorporates tool call and execution within the reasoning trajectory. Although recent works have released some powerful open-source TIR models, our analysis reveals that these models still suffer from critical deficiencies. We find that when the reasoning of the model conflicts with the tool results, the model tends to believe in its own reasoning. And there are cases where the tool results are correct but are ignored by the model, resulting in incorrect answers, which we define as "Tool Ignored''. This indicates that the model does not know when to trust or ignore the tool. To overcome these limitations, We introduce Adaptive Tool Trust Calibration (ATTC), a novel framework that guides the model to adaptively choose to trust or ignore the tool results based on the confidence score of generated code blocks. The experimental results from various open-source TIR models of different sizes and across multiple datasets demonstrate that ATTC effectively reduces the "Tool Ignored" issue, resulting in a performance increase of 4.1% to 7.5%.
Multi-Faceted Self-Consistent Preference Alignment for Query Rewriting in Conversational Search
Apr 08, 2026Conversational Query Rewriting (CQR) aims to rewrite ambiguous queries to achieve more efficient conversational search. Early studies have predominantly focused on the rewriting in isolation, ignoring the feedback from query rewrite, passage retrieval and response generation in the rewriting process. To address this issue, we propose Multi-Faceted Self-Consistent Preference Aligned CQR (MSPA-CQR). Specifically, we first construct self-consistent preference alignment data from three dimensions (rewriting, retrieval, and response) to generate more diverse rewritten queries. Then we propose prefix guided multi-faceted direct preference optimization to learn preference information from three different dimensions. The experimental results show that our MSPA-CQR is effective in both in- and out-of-distribution scenarios.
Discourse Coherence and Response-Guided Context Rewriting for Multi-Party Dialogue Generation
Apr 08, 2026Previous research on multi-party dialogue generation has predominantly leveraged structural information inherent in dialogues to directly inform the generation process. However, the prevalence of colloquial expressions and incomplete utterances in dialogues often impedes comprehension and weakens the fidelity of dialogue structure representations, which is particularly pronounced in multi-party dialogues. In this work, we propose a novel framework DRCR (Discourse coherence and Response-guided Context Rewriting) to improve multi-party dialogue generation through dialogue context rewriting. Specifically, DRCR employs two complementary feedback signals, discourse coherence and response quality, to construct preference data for both context rewriting and response generation. Moreover, we propose a dynamic self-evolution learning method that allows the rewriter and responder to continuously enhance their capabilities through mutual interaction in an iterative training loop. Comprehensive experiments conducted on four multi-party dialogue datasets substantiate the effectiveness of DRCR.
ICR: Iterative Clarification and Rewriting for Conversational Search
Sep 05, 2025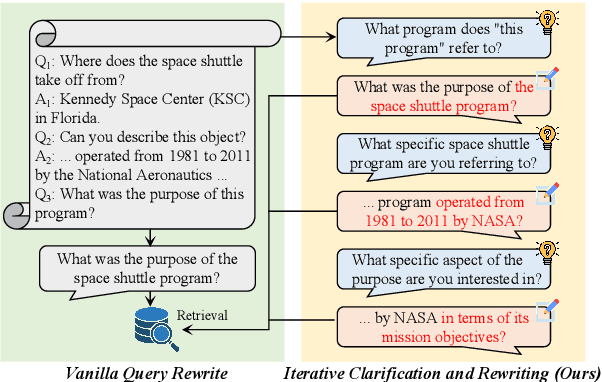
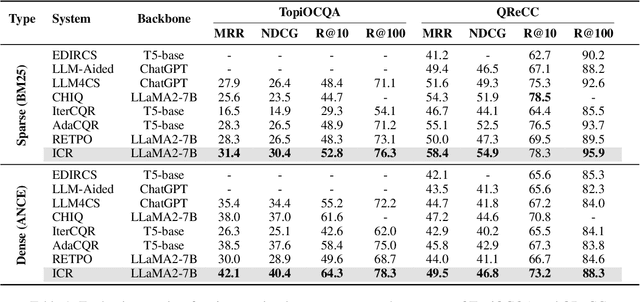
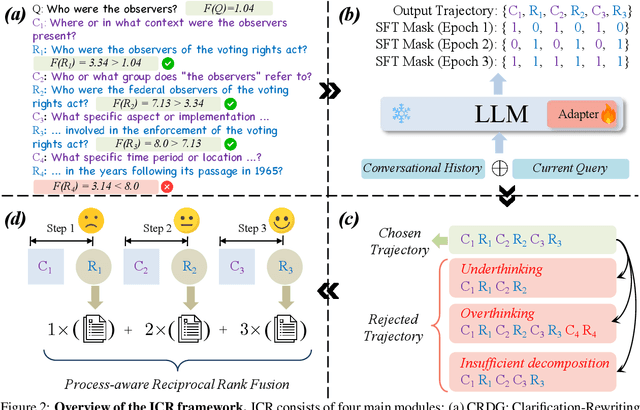
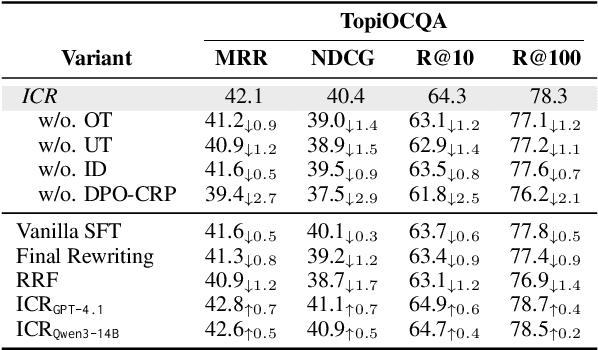
Most previous work on Conversational Query Rewriting employs an end-to-end rewriting paradigm. However, this approach is hindered by the issue of multiple fuzzy expressions within the query, which complicates the simultaneous identification and rewriting of multiple positions. To address this issue, we propose a novel framework ICR (Iterative Clarification and Rewriting), an iterative rewriting scheme that pivots on clarification questions. Within this framework, the model alternates between generating clarification questions and rewritten queries. The experimental results show that our ICR can continuously improve retrieval performance in the clarification-rewriting iterative process, thereby achieving state-of-the-art performance on two popular datasets.
Improving Dialogue Discourse Parsing through Discourse-aware Utterance Clarification
Jun 18, 2025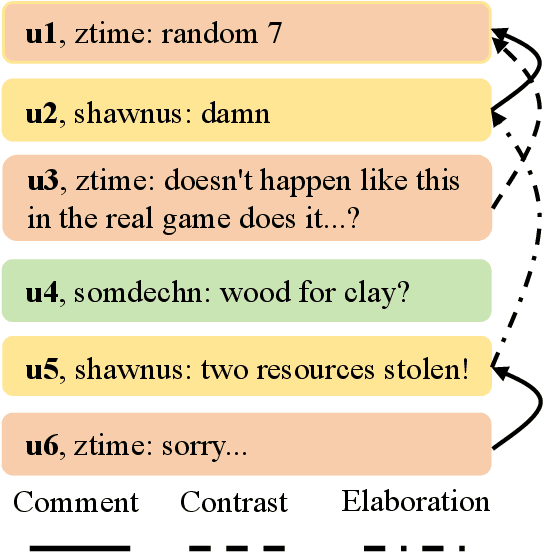
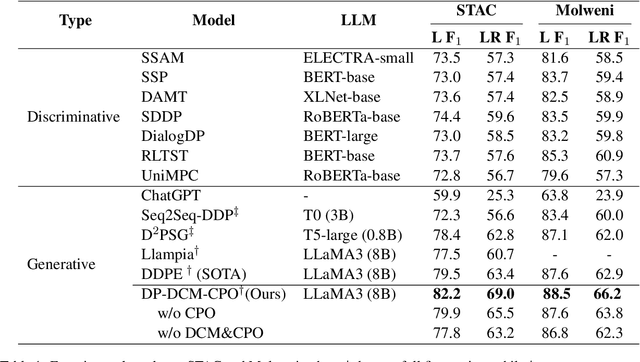
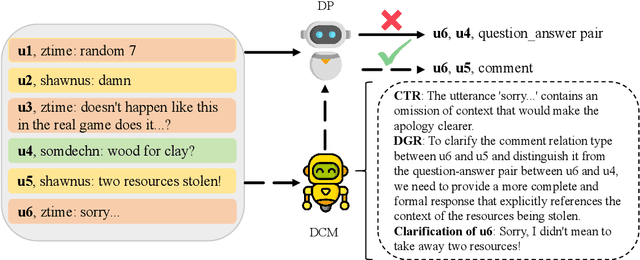
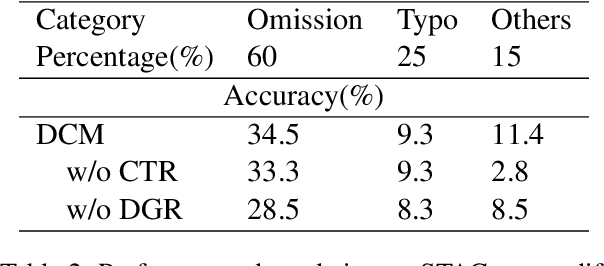
Dialogue discourse parsing aims to identify and analyze discourse relations between the utterances within dialogues. However, linguistic features in dialogues, such as omission and idiom, frequently introduce ambiguities that obscure the intended discourse relations, posing significant challenges for parsers. To address this issue, we propose a Discourse-aware Clarification Module (DCM) to enhance the performance of the dialogue discourse parser. DCM employs two distinct reasoning processes: clarification type reasoning and discourse goal reasoning. The former analyzes linguistic features, while the latter distinguishes the intended relation from the ambiguous one. Furthermore, we introduce Contribution-aware Preference Optimization (CPO) to mitigate the risk of erroneous clarifications, thereby reducing cascading errors. CPO enables the parser to assess the contributions of the clarifications from DCM and provide feedback to optimize the DCM, enhancing its adaptability and alignment with the parser's requirements. Extensive experiments on the STAC and Molweni datasets demonstrate that our approach effectively resolves ambiguities and significantly outperforms the state-of-the-art (SOTA) baselines.
Enhancing Goal-oriented Proactive Dialogue Systems via Consistency Reflection and Correction
Jun 16, 2025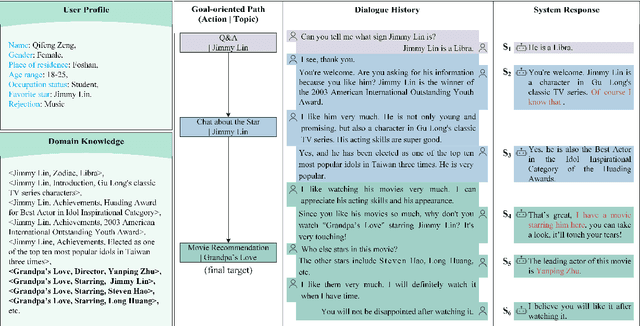
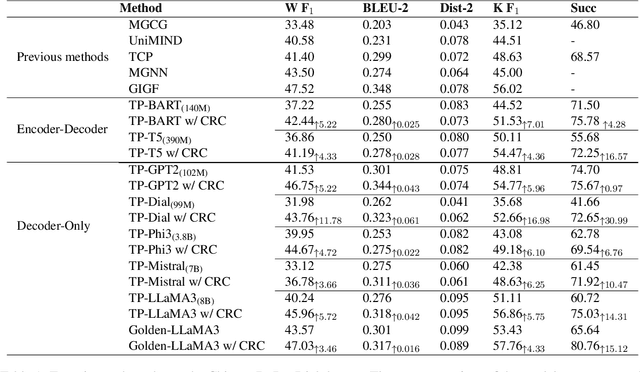
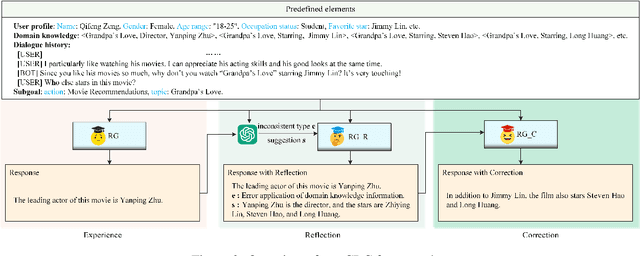
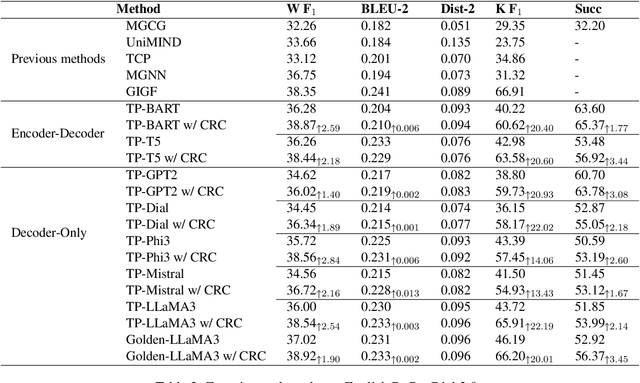
This paper proposes a consistency reflection and correction method for goal-oriented dialogue systems.
FMNV: A Dataset of Media-Published News Videos for Fake News Detection
Apr 10, 2025News media, particularly video-based platforms, have become deeply embedded in daily life, concurrently amplifying risks of misinformation dissemination. Consequently, multimodal fake news detection has garnered significant research attention. However, existing datasets predominantly comprise user-generated videos characterized by crude editing and limited public engagement, whereas professionally crafted fake news videos disseminated by media outlets often politically or virally motivated pose substantially greater societal harm. To address this gap, we construct FMNV, a novel dataset exclusively composed of news videos published by media organizations. Through empirical analysis of existing datasets and our curated collection, we categorize fake news videos into four distinct types. Building upon this taxonomy, we employ Large Language Models (LLMs) to automatically generate deceptive content by manipulating authentic media-published news videos. Furthermore, we propose FMNVD, a baseline model featuring a dual-stream architecture integrating CLIP and Faster R-CNN for video feature extraction, enhanced by co-attention mechanisms for feature refinement and multimodal aggregation. Comparative experiments demonstrate both the generalization capability of FMNV across multiple baselines and the superior detection efficacy of FMNVD. This work establishes critical benchmarks for detecting high-impact fake news in media ecosystems while advancing methodologies for cross-modal inconsistency analysis.
Incomplete Utterance Rewriting with Editing Operation Guidance and Utterance Augmentation
Mar 20, 2025Although existing fashionable generation methods on Incomplete Utterance Rewriting (IUR) can generate coherent utterances, they often result in the inclusion of irrelevant and redundant tokens in rewritten utterances due to their inability to focus on critical tokens in dialogue context. Furthermore, the limited size of the training datasets also contributes to the insufficient training of the IUR model. To address the first issue, we propose a multi-task learning framework EO-IUR (Editing Operation-guided Incomplete Utterance Rewriting) that introduces the editing operation labels generated by sequence labeling module to guide generation model to focus on critical tokens. Furthermore, we introduce a token-level heterogeneous graph to represent dialogues. To address the second issue, we propose a two-dimensional utterance augmentation strategy, namely editing operation-based incomplete utterance augmentation and LLM-based historical utterance augmentation. The experimental results on three datasets demonstrate that our EO-IUR outperforms previous state-of-the-art (SOTA) baselines in both open-domain and task-oriented dialogue. The code will be available at https://github.com/Dewset/EO-IUR.
Two-stage Incomplete Utterance Rewriting on Editing Operation
Mar 20, 2025Previous work on Incomplete Utterance Rewriting (IUR) has primarily focused on generating rewritten utterances based solely on dialogue context, ignoring the widespread phenomenon of coreference and ellipsis in dialogues. To address this issue, we propose a novel framework called TEO (\emph{Two-stage approach on Editing Operation}) for IUR, in which the first stage generates editing operations and the second stage rewrites incomplete utterances utilizing the generated editing operations and the dialogue context. Furthermore, an adversarial perturbation strategy is proposed to mitigate cascading errors and exposure bias caused by the inconsistency between training and inference in the second stage. Experimental results on three IUR datasets show that our TEO outperforms the SOTA models significantly.
Exploring Model Editing for LLM-based Aspect-Based Sentiment Classification
Mar 19, 2025



Model editing aims at selectively updating a small subset of a neural model's parameters with an interpretable strategy to achieve desired modifications. It can significantly reduce computational costs to adapt to large language models (LLMs). Given its ability to precisely target critical components within LLMs, model editing shows great potential for efficient fine-tuning applications. In this work, we investigate model editing to serve an efficient method for adapting LLMs to solve aspect-based sentiment classification. Through causal interventions, we trace and determine which neuron hidden states are essential for the prediction of the model. By performing interventions and restorations on each component of an LLM, we identify the importance of these components for aspect-based sentiment classification. Our findings reveal that a distinct set of mid-layer representations is essential for detecting the sentiment polarity of given aspect words. Leveraging these insights, we develop a model editing approach that focuses exclusively on these critical parts of the LLM, leading to a more efficient method for adapting LLMs. Our in-domain and out-of-domain experiments demonstrate that this approach achieves competitive results compared to the currently strongest methods with significantly fewer trainable parameters, highlighting a more efficient and interpretable fine-tuning strategy.