 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMultimodal Fake News Video Explanation Generation
Jan 15, 2025Multi-modal explanation involves the assessment of the veracity of a variety of different content, and relies on multiple information modalities to comprehensively consider the relevance and consistency between modalities. Most existing fake news video detection methods focus on improving accuracy while ignoring the importance of providing explanations. In this paper, we propose a novel problem - Fake News Video Explanation (FNVE) - Given a multimodal news containing both video and caption text, we aim to generate natural language explanations to reveal the truth of predictions. To this end, we develop FakeNVE, a new dataset of explanations for truthfully multimodal posts, where each explanation is a natural language (English) sentence describing the attribution of a news thread. We benchmark FakeNVE by using a multimodal transformer-based architecture. Subsequently, a BART-based autoregressive decoder is used as the generator. Empirical results show compelling results for various baselines (applicable to FNVE) across multiple evaluation metrics. We also perform human evaluation on explanation generation, achieving high scores for both adequacy and fluency.
Official-NV: A News Video Dataset for Multimodal Fake News Detection
Jul 28, 2024


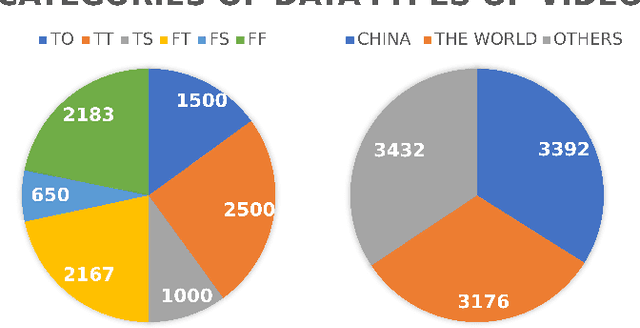
News media, especially video news media, have penetrated into every aspect of daily life, which also brings the risk of fake news. Therefore, multimodal fake news detection has recently received more attention. However, the number of fake news detection data sets for video modal is small, and these data sets are composed of unofficial videos uploaded by users, so there is too much useless data. To solve this problem, we present in this paper a dataset named Official-NV, which consists of officially published news videos on Xinhua. We crawled videos on Xinhua, and then extended the data set using LLM generation and manual modification. In addition, we benchmarked the data set presented in this paper using a baseline model to demonstrate the advantage of Official-NV in multimodal fake news detection.