 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelative Score Policy Optimization for Diffusion Language Models
May 11, 2026Diffusion large language models (dLLMs) offer a promising route to parallel and efficient text generation, but improving their reasoning ability requires effective post-training. Reinforcement learning with verifiable rewards (RLVR) is a natural choice for this purpose, yet its application to dLLMs is hindered by the absence of tractable sequence-level log-ratios, which are central to standard policy optimization. The lack of tractable sequence-level log-ratios forces existing methods to rely on high-variance ELBO-based approximations, where high verifier rewards can amplify inaccurate score estimates and destabilize RL training. To overcome this issue, we propose \textbf{R}elative \textbf{S}core \textbf{P}olicy \textbf{O}ptimization (RSPO), a simple RLVR method that uses verifiable rewards to calibrate noisy likelihood estimates in dLLMs. The core of our algorithm relies on a key observation: a reward advantage can be interpreted not only as an update direction, but also as a target for the relative log-ratio between the current and reference policies. Accordingly, RSPO calibrates this noisy relative log-ratio estimate by comparing its reward advantage with the reward-implied target relative log-ratio, updating the policy according to the gap between the current estimate and the target rather than the raw advantage alone. Experiments on mathematical reasoning and planning benchmarks show that RSPO yields especially strong gains on planning tasks and competitive mathematical-reasoning performance.
Detecting Transportation Mode Using Dense Smartphone GPS Trajectories and Transformer Models
Feb 27, 2026Transportation mode detection is an important topic within GeoAI and transportation research. In this study, we introduce SpeedTransformer, a novel Transformer-based model that relies solely on speed inputs to infer transportation modes from dense smartphone GPS trajectories. In benchmark experiments, SpeedTransformer outperformed traditional deep learning models, such as the Long Short-Term Memory (LSTM) network. Moreover, the model demonstrated strong flexibility in transfer learning, achieving high accuracy across geographical regions after fine-tuning with small datasets. Finally, we deployed the model in a real-world experiment, where it consistently outperformed baseline models under complex built environments and high data uncertainty. These findings suggest that Transformer architectures, when combined with dense GPS trajectories, hold substantial potential for advancing transportation mode detection and broader mobility-related research.
ProFlow: Zero-Shot Physics-Consistent Sampling via Proximal Flow Guidance
Jan 28, 2026Inferring physical fields from sparse observations while strictly satisfying partial differential equations (PDEs) is a fundamental challenge in computational physics. Recently, deep generative models offer powerful data-driven priors for such inverse problems, yet existing methods struggle to enforce hard physical constraints without costly retraining or disrupting the learned generative prior. Consequently, there is a critical need for a sampling mechanism that can reconcile strict physical consistency and observational fidelity with the statistical structure of the pre-trained prior. To this end, we present ProFlow, a proximal guidance framework for zero-shot physics-consistent sampling, defined as inferring solutions from sparse observations using a fixed generative prior without task-specific retraining. The algorithm employs a rigorous two-step scheme that alternates between: (\romannumeral1) a terminal optimization step, which projects the flow prediction onto the intersection of the physically and observationally consistent sets via proximal minimization; and (\romannumeral2) an interpolation step, which maps the refined state back to the generative trajectory to maintain consistency with the learned flow probability path. This procedure admits a Bayesian interpretation as a sequence of local maximum a posteriori (MAP) updates. Comprehensive benchmarks on Poisson, Helmholtz, Darcy, and viscous Burgers' equations demonstrate that ProFlow achieves superior physical and observational consistency, as well as more accurate distributional statistics, compared to state-of-the-art diffusion- and flow-based baselines.
An Elementary Approach to Scheduling in Generative Diffusion Models
Jan 20, 2026An elementary approach to characterizing the impact of noise scheduling and time discretization in generative diffusion models is developed. Considering a simplified model where the source distribution is multivariate Gaussian with a given covariance matrix, the explicit closed-form evolution trajectory of the distributions across reverse sampling steps is derived, and consequently, the Kullback-Leibler (KL) divergence between the source distribution and the reverse sampling output is obtained. The effect of the number of time discretization steps on the convergence of this KL divergence is studied via the Euler-Maclaurin expansion. An optimization problem is formulated, and its solution noise schedule is obtained via calculus of variations, shown to follow a tangent law whose coefficient is determined by the eigenvalues of the source covariance matrix. For an alternative scenario, more realistic in practice, where pretrained models have been obtained for some given noise schedules, the KL divergence also provides a measure to compare different time discretization strategies in reverse sampling. Experiments across different datasets and pretrained models demonstrate that the time discretization strategy selected by our approach consistently outperforms baseline and search-based strategies, particularly when the budget on the number of function evaluations is very tight.
OpenPathNet: An Open-Source RF Multipath Data Generator for AI-Driven Wireless Systems
Dec 19, 2025The convergence of artificial intelligence (AI) and sixth-generation (6G) wireless technologies is driving an urgent need for large-scale, high-fidelity, and reproducible radio frequency (RF) datasets. Existing resources, such as CKMImageNet, primarily provide preprocessed and image-based channel representations, which conceal the fine-grained physical characteristics of signal propagation that are essential for effective AI modeling. To bridge this gap, we present OpenPathNet, an open-source RF multipath data generator accompanied by a publicly released dataset for AI-driven wireless research. Distinct from prior datasets, OpenPathNet offers disaggregated and physically consistent multipath parameters, including per-path gain, time of arrival (ToA), and spatial angles, derived from high-precision ray tracing simulations constructed on real-world environment maps. By adopting a modular, parameterized pipeline, OpenPathNet enables reproducible generation of multipath data and can be readily extended to new environments and configurations, improving scalability and transparency. The released generator and accompanying dataset provide an extensible testbed that holds promise for advancing studies on channel modeling, beam prediction, environment-aware communication, and integrated sensing in AI-enabled 6G systems. The source code and dataset are publicly available at https://github.com/liu-lz/OpenPathNet.
PINN and GNN-based RF Map Construction for Wireless Communication Systems
Jul 30, 2025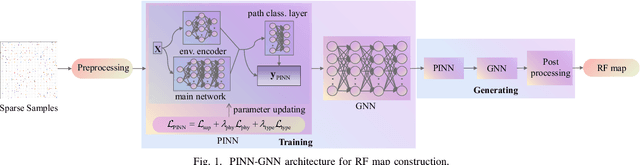
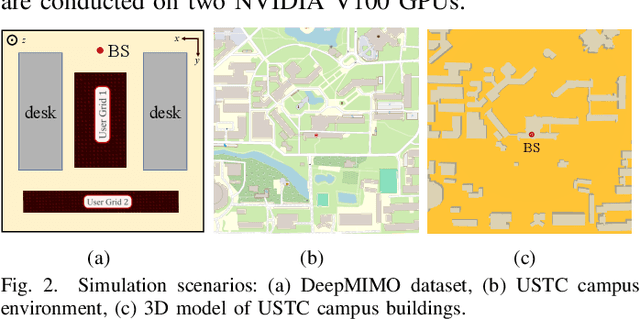
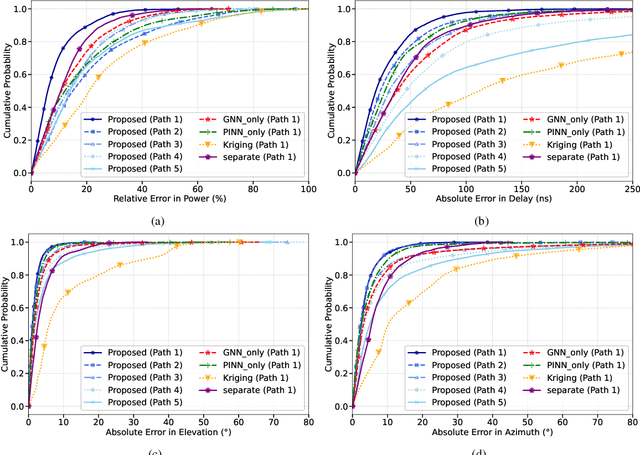
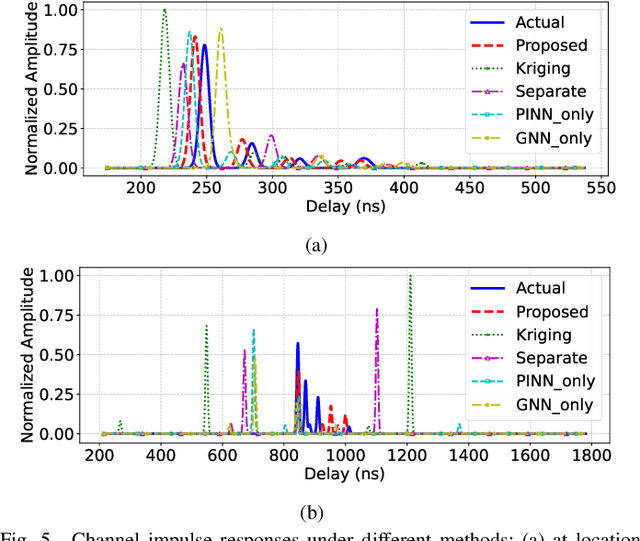
Radio frequency (RF) map is a promising technique for capturing the characteristics of multipath signal propagation, offering critical support for channel modeling, coverage analysis, and beamforming in wireless communication networks. This paper proposes a novel RF map construction method based on a combination of physics-informed neural network (PINN) and graph neural network (GNN). The PINN incorporates physical constraints derived from electromagnetic propagation laws to guide the learning process, while the GNN models spatial correlations among receiver locations. By parameterizing multipath signals into received power, delay, and angle of arrival (AoA), and integrating both physical priors and spatial dependencies, the proposed method achieves accurate prediction of multipath parameters. Experimental results demonstrate that the method enables high-precision RF map construction under sparse sampling conditions and delivers robust performance in both indoor and complex outdoor environments, outperforming baseline methods in terms of generalization and accuracy.
PATFinger: Prompt-Adapted Transferable Fingerprinting against Unauthorized Multimodal Dataset Usage
Apr 15, 2025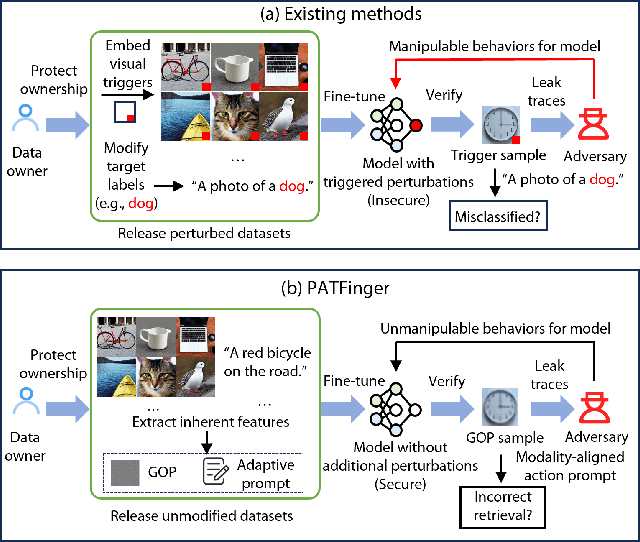
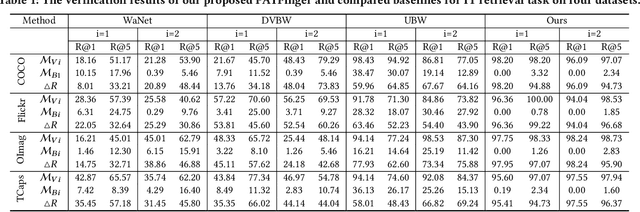
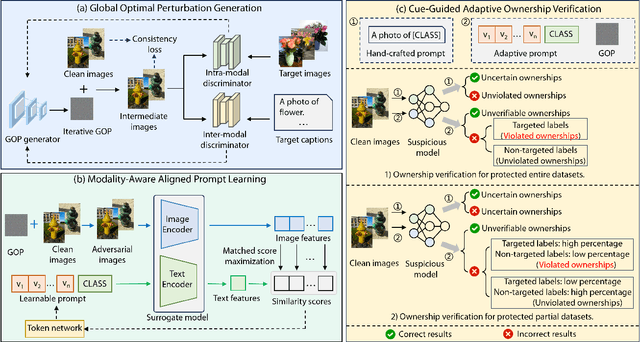
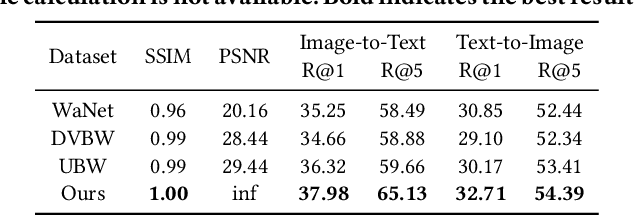
The multimodal datasets can be leveraged to pre-train large-scale vision-language models by providing cross-modal semantics. Current endeavors for determining the usage of datasets mainly focus on single-modal dataset ownership verification through intrusive methods and non-intrusive techniques, while cross-modal approaches remain under-explored. Intrusive methods can adapt to multimodal datasets but degrade model accuracy, while non-intrusive methods rely on label-driven decision boundaries that fail to guarantee stable behaviors for verification. To address these issues, we propose a novel prompt-adapted transferable fingerprinting scheme from a training-free perspective, called PATFinger, which incorporates the global optimal perturbation (GOP) and the adaptive prompts to capture dataset-specific distribution characteristics. Our scheme utilizes inherent dataset attributes as fingerprints instead of compelling the model to learn triggers. The GOP is derived from the sample distribution to maximize embedding drifts between different modalities. Subsequently, our PATFinger re-aligns the adaptive prompt with GOP samples to capture the cross-modal interactions on the carefully crafted surrogate model. This allows the dataset owner to check the usage of datasets by observing specific prediction behaviors linked to the PATFinger during retrieval queries. Extensive experiments demonstrate the effectiveness of our scheme against unauthorized multimodal dataset usage on various cross-modal retrieval architectures by 30% over state-of-the-art baselines.
AB-Cache: Training-Free Acceleration of Diffusion Models via Adams-Bashforth Cached Feature Reuse
Apr 13, 2025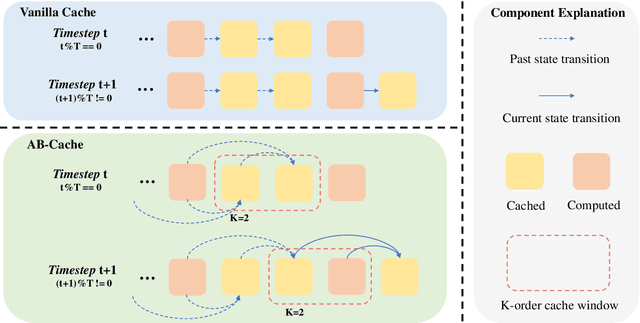
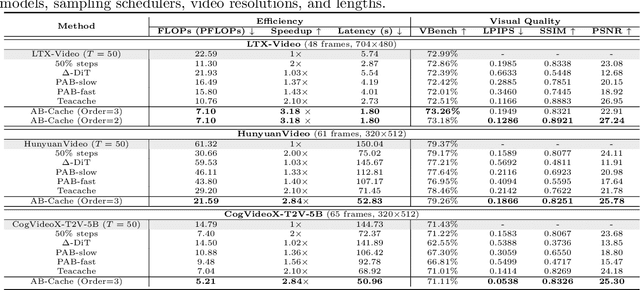
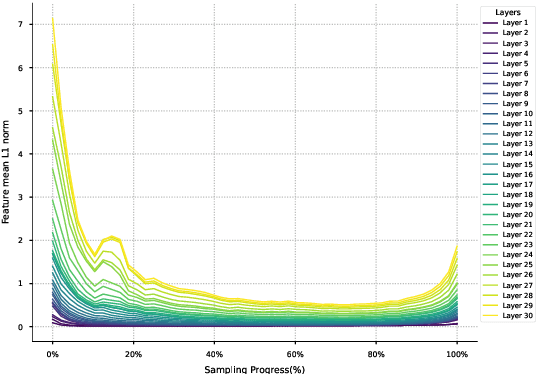
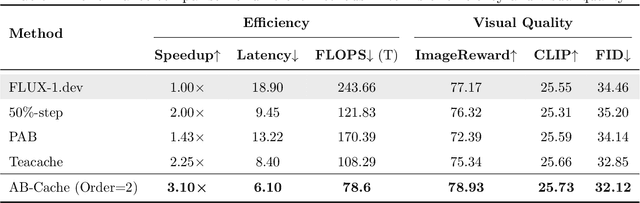
Diffusion models have demonstrated remarkable success in generative tasks, yet their iterative denoising process results in slow inference, limiting their practicality. While existing acceleration methods exploit the well-known U-shaped similarity pattern between adjacent steps through caching mechanisms, they lack theoretical foundation and rely on simplistic computation reuse, often leading to performance degradation. In this work, we provide a theoretical understanding by analyzing the denoising process through the second-order Adams-Bashforth method, revealing a linear relationship between the outputs of consecutive steps. This analysis explains why the outputs of adjacent steps exhibit a U-shaped pattern. Furthermore, extending Adams-Bashforth method to higher order, we propose a novel caching-based acceleration approach for diffusion models, instead of directly reusing cached results, with a truncation error bound of only \(O(h^k)\) where $h$ is the step size. Extensive validation across diverse image and video diffusion models (including HunyuanVideo and FLUX.1-dev) with various schedulers demonstrates our method's effectiveness in achieving nearly $3\times$ speedup while maintaining original performance levels, offering a practical real-time solution without compromising generation quality.
A Survey of Foundation Models for Music Understanding
Sep 15, 2024
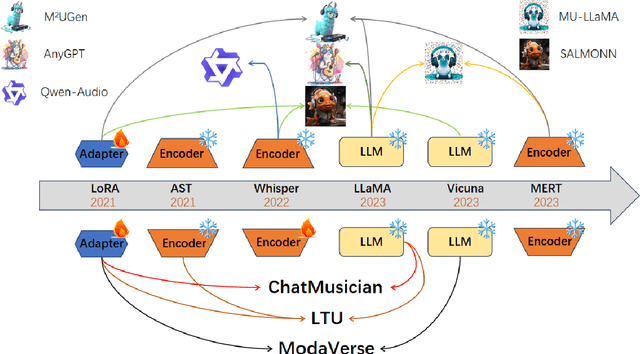
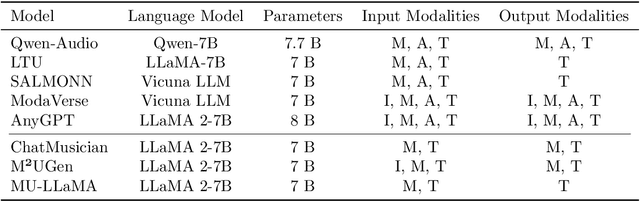
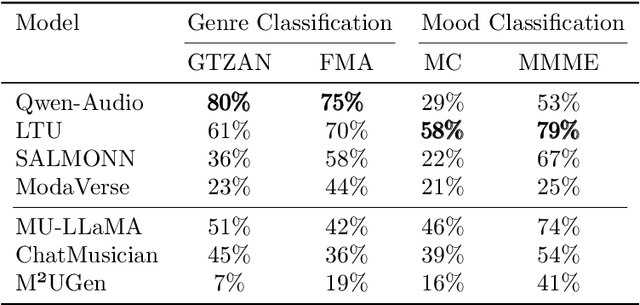
Music is essential in daily life, fulfilling emotional and entertainment needs, and connecting us personally, socially, and culturally. A better understanding of music can enhance our emotions, cognitive skills, and cultural connections. The rapid advancement of artificial intelligence (AI) has introduced new ways to analyze music, aiming to replicate human understanding of music and provide related services. While the traditional models focused on audio features and simple tasks, the recent development of large language models (LLMs) and foundation models (FMs), which excel in various fields by integrating semantic information and demonstrating strong reasoning abilities, could capture complex musical features and patterns, integrate music with language and incorporate rich musical, emotional and psychological knowledge. Therefore, they have the potential in handling complex music understanding tasks from a semantic perspective, producing outputs closer to human perception. This work, to our best knowledge, is one of the early reviews of the intersection of AI techniques and music understanding. We investigated, analyzed, and tested recent large-scale music foundation models in respect of their music comprehension abilities. We also discussed their limitations and proposed possible future directions, offering insights for researchers in this field.
Rethinking the Key Factors for the Generalization of Remote Sensing Stereo Matching Networks
Aug 14, 2024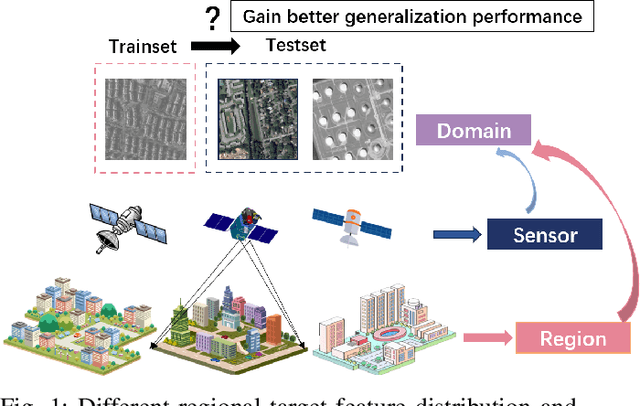
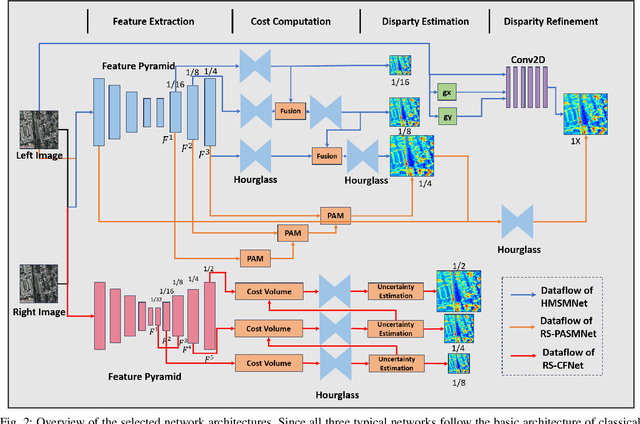


Stereo matching, a critical step of 3D reconstruction, has fully shifted towards deep learning due to its strong feature representation of remote sensing images. However, ground truth for stereo matching task relies on expensive airborne LiDAR data, thus making it difficult to obtain enough samples for supervised learning. To improve the generalization ability of stereo matching networks on cross-domain data from different sensors and scenarios, in this paper, we dedicate to study key training factors from three perspectives. (1) For the selection of training dataset, it is important to select data with similar regional target distribution as the test set instead of utilizing data from the same sensor. (2) For model structure, cascaded structure that flexibly adapts to different sizes of features is preferred. (3) For training manner, unsupervised methods generalize better than supervised methods, and we design an unsupervised early-stop strategy to help retain the best model with pre-trained weights as the basis. Extensive experiments are conducted to support the previous findings, on the basis of which we present an unsupervised stereo matching network with good generalization performance. We release the source code and the datasets at https://github.com/Elenairene/RKF_RSSM to reproduce the results and encourage future work.