 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast-ARDiff: An Entropy-informed Acceleration Framework for Continuous Space Autoregressive Generation
Dec 09, 2025
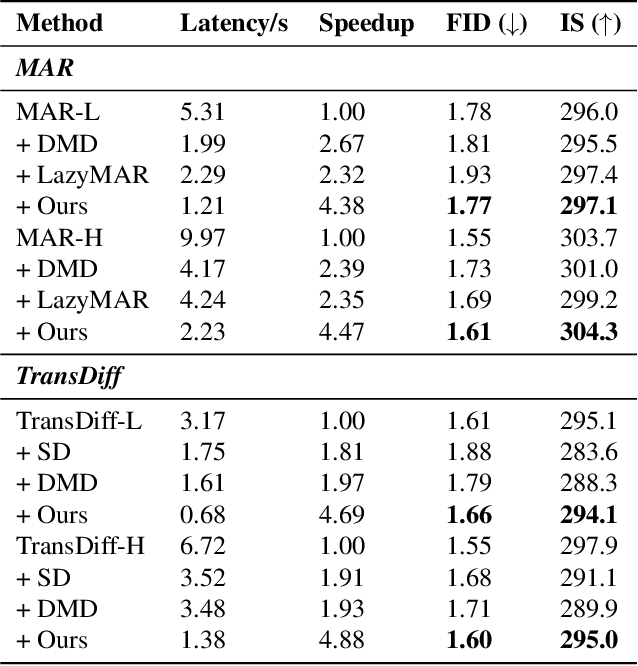
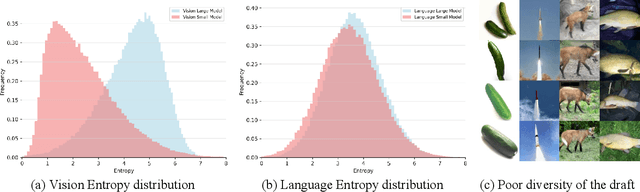
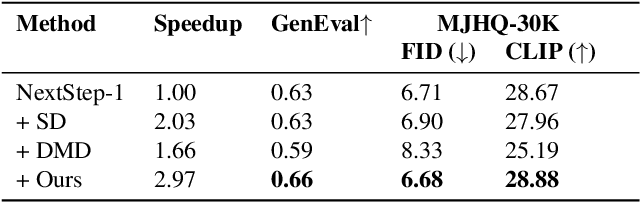
Autoregressive(AR)-diffusion hybrid paradigms combine AR's structured modeling with diffusion's photorealistic synthesis, yet suffer from high latency due to sequential AR generation and iterative denoising. In this work, we tackle this bottleneck and propose a unified AR-diffusion framework Fast-ARDiff that jointly optimizes both components, accelerating AR speculative decoding while simultaneously facilitating faster diffusion decoding. Specifically: (1) The entropy-informed speculative strategy encourages draft model to produce higher-entropy representations aligned with target model's entropy characteristics, mitigating entropy mismatch and high rejection rates caused by draft overconfidence. (2) For diffusion decoding, rather than treating it as an independent module, we integrate it into the same end-to-end framework using a dynamic scheduler that prioritizes AR optimization to guide the diffusion part in further steps. The diffusion part is optimized through a joint distillation framework combining trajectory and distribution matching, ensuring stable training and high-quality synthesis with extremely few steps. During inference, shallow feature entropy from AR module is used to pre-filter low-entropy drafts, avoiding redundant computation and improving latency. Fast-ARDiff achieves state-of-the-art acceleration across diverse models: on ImageNet 256$\times$256, TransDiff attains 4.3$\times$ lossless speedup, and NextStep-1 achieves 3$\times$ acceleration on text-conditioned generation. Code will be available at https://github.com/aSleepyTree/Fast-ARDiff.
From Structure to Detail: Hierarchical Distillation for Efficient Diffusion Model
Nov 12, 2025The inference latency of diffusion models remains a critical barrier to their real-time application. While trajectory-based and distribution-based step distillation methods offer solutions, they present a fundamental trade-off. Trajectory-based methods preserve global structure but act as a "lossy compressor", sacrificing high-frequency details. Conversely, distribution-based methods can achieve higher fidelity but often suffer from mode collapse and unstable training. This paper recasts them from independent paradigms into synergistic components within our novel Hierarchical Distillation (HD) framework. We leverage trajectory distillation not as a final generator, but to establish a structural ``sketch", providing a near-optimal initialization for the subsequent distribution-based refinement stage. This strategy yields an ideal initial distribution that enhances the ceiling of overall performance. To further improve quality, we introduce and refine the adversarial training process. We find standard discriminator structures are ineffective at refining an already high-quality generator. To overcome this, we introduce the Adaptive Weighted Discriminator (AWD), tailored for the HD pipeline. By dynamically allocating token weights, AWD focuses on local imperfections, enabling efficient detail refinement. Our approach demonstrates state-of-the-art performance across diverse tasks. On ImageNet $256\times256$, our single-step model achieves an FID of 2.26, rivaling its 250-step teacher. It also achieves promising results on the high-resolution text-to-image MJHQ benchmark, proving its generalizability. Our method establishes a robust new paradigm for high-fidelity, single-step diffusion models.
Adaptive Dropout: Unleashing Dropout across Layers for Generalizable Image Super-Resolution
Jun 15, 2025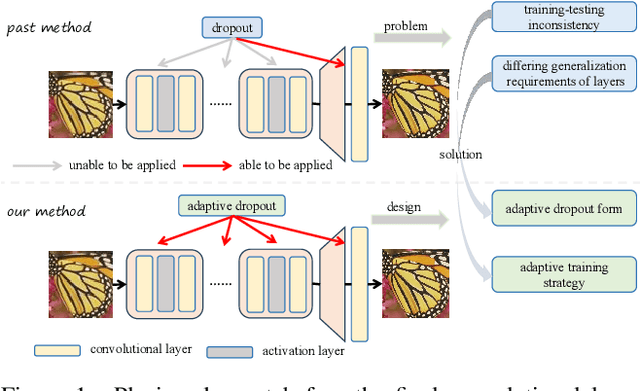



Blind Super-Resolution (blind SR) aims to enhance the model's generalization ability with unknown degradation, yet it still encounters severe overfitting issues. Some previous methods inspired by dropout, which enhances generalization by regularizing features, have shown promising results in blind SR. Nevertheless, these methods focus solely on regularizing features before the final layer and overlook the need for generalization in features at intermediate layers. Without explicit regularization of features at intermediate layers, the blind SR network struggles to obtain well-generalized feature representations. However, the key challenge is that directly applying dropout to intermediate layers leads to a significant performance drop, which we attribute to the inconsistency in training-testing and across layers it introduced. Therefore, we propose Adaptive Dropout, a new regularization method for blind SR models, which mitigates the inconsistency and facilitates application across intermediate layers of networks. Specifically, for training-testing inconsistency, we re-design the form of dropout and integrate the features before and after dropout adaptively. For inconsistency in generalization requirements across different layers, we innovatively design an adaptive training strategy to strengthen feature propagation by layer-wise annealing. Experimental results show that our method outperforms all past regularization methods on both synthetic and real-world benchmark datasets, also highly effective in other image restoration tasks. Code is available at \href{https://github.com/xuhang07/Adpative-Dropout}{https://github.com/xuhang07/Adpative-Dropout}.
AB-Cache: Training-Free Acceleration of Diffusion Models via Adams-Bashforth Cached Feature Reuse
Apr 13, 2025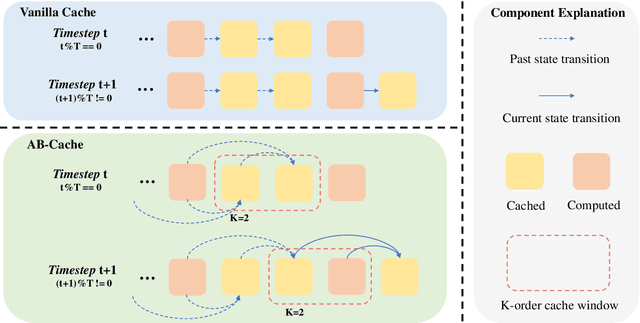
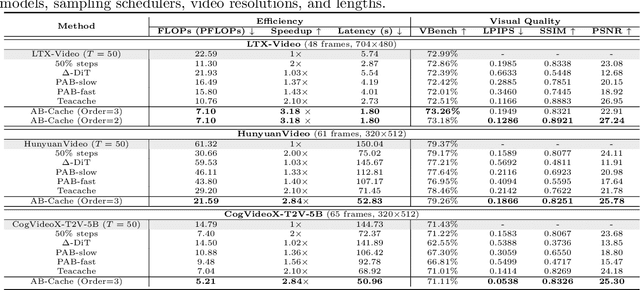
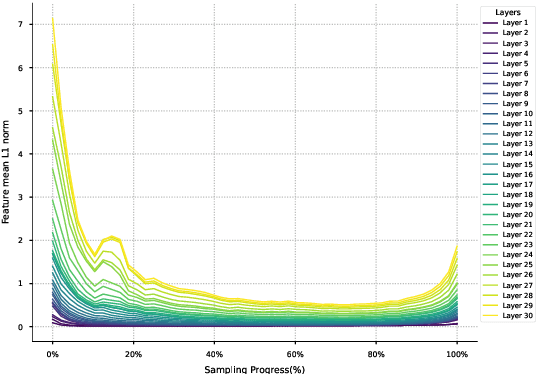
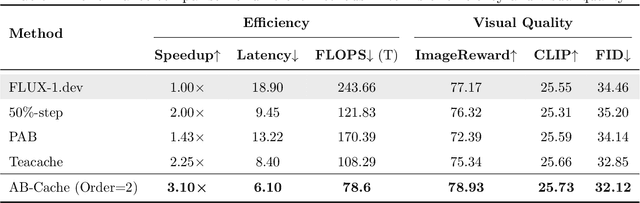
Diffusion models have demonstrated remarkable success in generative tasks, yet their iterative denoising process results in slow inference, limiting their practicality. While existing acceleration methods exploit the well-known U-shaped similarity pattern between adjacent steps through caching mechanisms, they lack theoretical foundation and rely on simplistic computation reuse, often leading to performance degradation. In this work, we provide a theoretical understanding by analyzing the denoising process through the second-order Adams-Bashforth method, revealing a linear relationship between the outputs of consecutive steps. This analysis explains why the outputs of adjacent steps exhibit a U-shaped pattern. Furthermore, extending Adams-Bashforth method to higher order, we propose a novel caching-based acceleration approach for diffusion models, instead of directly reusing cached results, with a truncation error bound of only \(O(h^k)\) where $h$ is the step size. Extensive validation across diverse image and video diffusion models (including HunyuanVideo and FLUX.1-dev) with various schedulers demonstrates our method's effectiveness in achieving nearly $3\times$ speedup while maintaining original performance levels, offering a practical real-time solution without compromising generation quality.
Exposure Bias Reduction for Enhancing Diffusion Transformer Feature Caching
Mar 10, 2025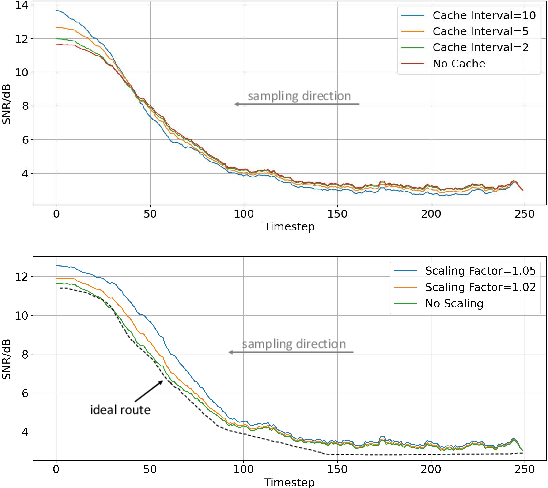
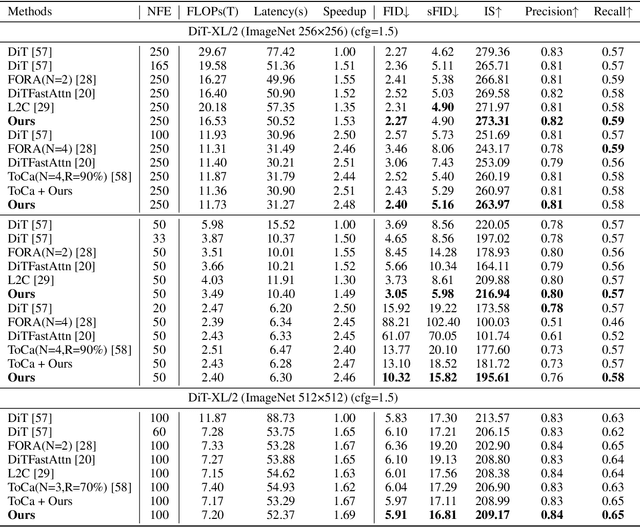
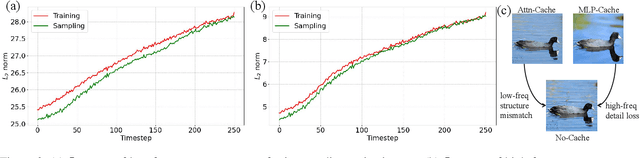
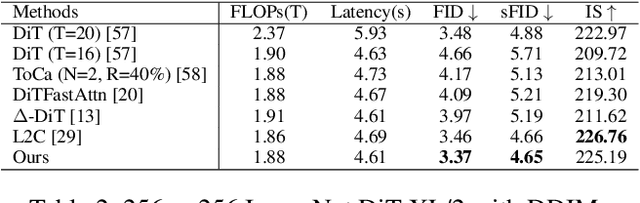
Diffusion Transformer (DiT) has exhibited impressive generation capabilities but faces great challenges due to its high computational complexity. To address this problem, various methods, notably feature caching, have been introduced. However, these approaches focus on aligning non-cache diffusion without analyzing the impact of caching on the generation of intermediate processes. So the lack of exploration provides us with room for analysis and improvement. In this paper, we analyze the impact of caching on the SNR of the diffusion process and discern that feature caching intensifies the denoising procedure, and we further identify this as a more severe exposure bias issue. Drawing on this insight, we introduce EB-Cache, a joint cache strategy that aligns the Non-exposure bias (which gives us a higher performance ceiling) diffusion process. Our approach incorporates a comprehensive understanding of caching mechanisms and offers a novel perspective on leveraging caches to expedite diffusion processes. Empirical results indicate that EB-Cache optimizes model performance while concurrently facilitating acceleration. Specifically, in the 50-step generation process, EB-Cache achieves 1.49$\times$ acceleration with 0.63 FID reduction from 3.69, surpassing prior acceleration methods. Code will be available at \href{https://github.com/aSleepyTree/EB-Cache}{https://github.com/aSleepyTree/EB-Cache}.