 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint decoding method for controllable contextual speech recognition based on Speech LLM
Aug 12, 2025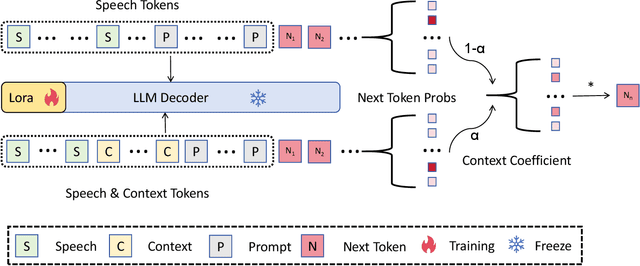
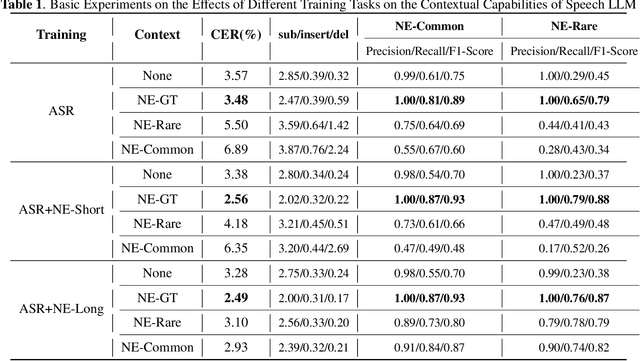
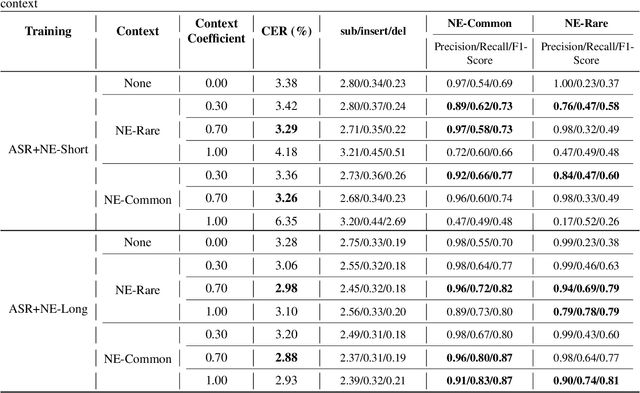
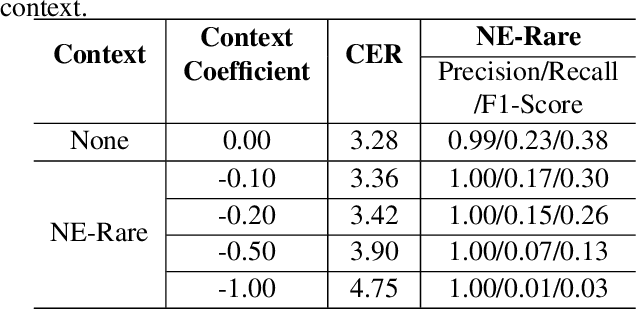
Contextual speech recognition refers to the ability to identify preferences for specific content based on contextual information. Recently, leveraging the contextual understanding capabilities of Speech LLM to achieve contextual biasing by injecting contextual information through prompts have emerged as a research hotspot.However, the direct information injection method via prompts relies on the internal attention mechanism of the model, making it impossible to explicitly control the extent of information injection. To address this limitation, we propose a joint decoding method to control the contextual information. This approach enables explicit control over the injected contextual information and achieving superior recognition performance. Additionally, Our method can also be used for sensitive word suppression recognition.Furthermore, experimental results show that even Speech LLM not pre-trained on long contextual data can acquire long contextual capabilities through our method.
Low-Resource Domain Adaptation for Speech LLMs via Text-Only Fine-Tuning
Jun 06, 2025



Recent advances in automatic speech recognition (ASR) have combined speech encoders with large language models (LLMs) through projection, forming Speech LLMs with strong performance. However, adapting them to new domains remains challenging, especially in low-resource settings where paired speech-text data is scarce. We propose a text-only fine-tuning strategy for Speech LLMs using unpaired target-domain text without requiring additional audio. To preserve speech-text alignment, we introduce a real-time evaluation mechanism during fine-tuning. This enables effective domain adaptation while maintaining source-domain performance. Experiments on LibriSpeech, SlideSpeech, and Medical datasets show that our method achieves competitive recognition performance, with minimal degradation compared to full audio-text fine-tuning. It also improves generalization to new domains without catastrophic forgetting, highlighting the potential of text-only fine-tuning for low-resource domain adaptation of ASR.
Fewer Hallucinations, More Verification: A Three-Stage LLM-Based Framework for ASR Error Correction
May 30, 2025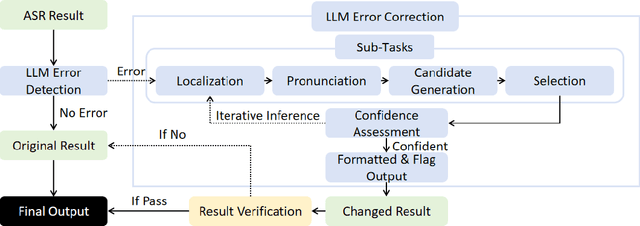
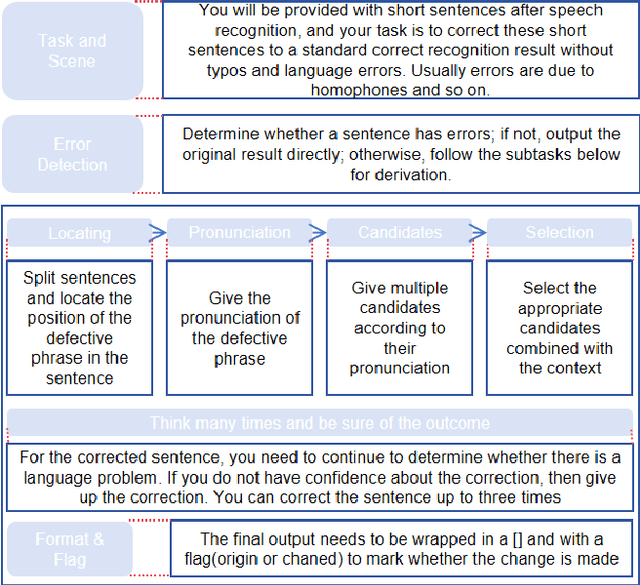
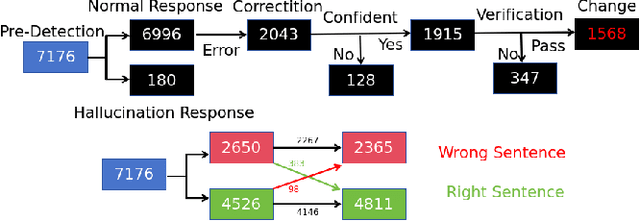
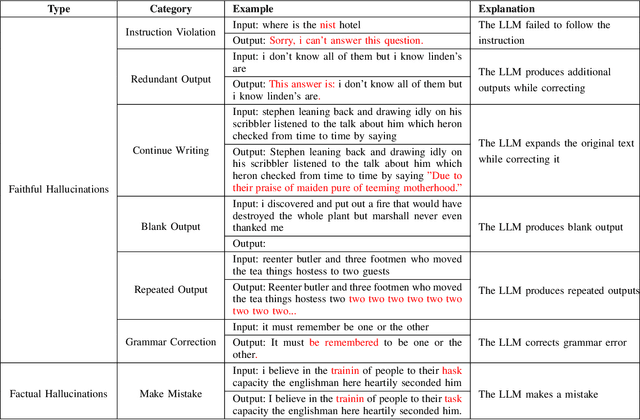
Automatic Speech Recognition (ASR) error correction aims to correct recognition errors while preserving accurate text. Although traditional approaches demonstrate moderate effectiveness, LLMs offer a paradigm that eliminates the need for training and labeled data. However, directly using LLMs will encounter hallucinations problem, which may lead to the modification of the correct text. To address this problem, we propose the Reliable LLM Correction Framework (RLLM-CF), which consists of three stages: (1) error pre-detection, (2) chain-of-thought sub-tasks iterative correction, and (3) reasoning process verification. The advantage of our method is that it does not require additional information or fine-tuning of the model, and ensures the correctness of the LLM correction under multi-pass programming. Experiments on AISHELL-1, AISHELL-2, and Librispeech show that the GPT-4o model enhanced by our framework achieves 21%, 11%, 9%, and 11.4% relative reductions in CER/WER.
AB-Cache: Training-Free Acceleration of Diffusion Models via Adams-Bashforth Cached Feature Reuse
Apr 13, 2025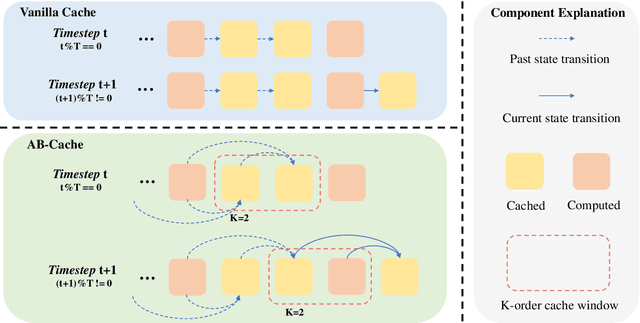
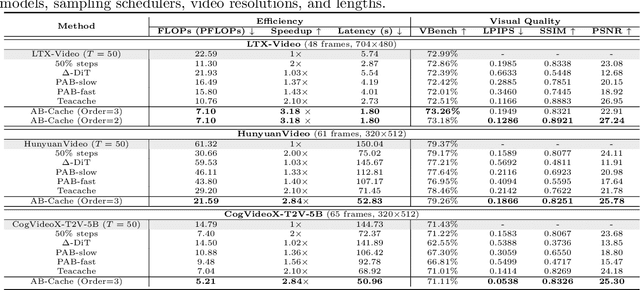
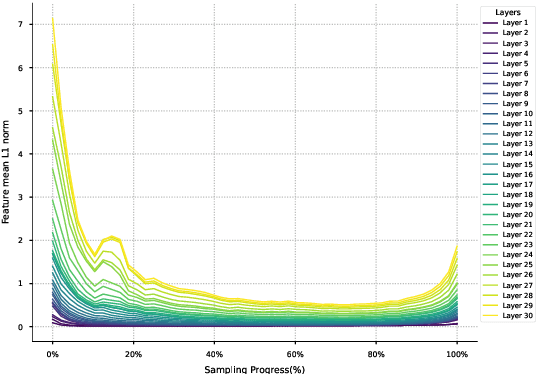
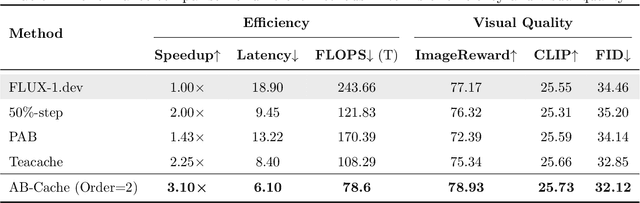
Diffusion models have demonstrated remarkable success in generative tasks, yet their iterative denoising process results in slow inference, limiting their practicality. While existing acceleration methods exploit the well-known U-shaped similarity pattern between adjacent steps through caching mechanisms, they lack theoretical foundation and rely on simplistic computation reuse, often leading to performance degradation. In this work, we provide a theoretical understanding by analyzing the denoising process through the second-order Adams-Bashforth method, revealing a linear relationship between the outputs of consecutive steps. This analysis explains why the outputs of adjacent steps exhibit a U-shaped pattern. Furthermore, extending Adams-Bashforth method to higher order, we propose a novel caching-based acceleration approach for diffusion models, instead of directly reusing cached results, with a truncation error bound of only \(O(h^k)\) where $h$ is the step size. Extensive validation across diverse image and video diffusion models (including HunyuanVideo and FLUX.1-dev) with various schedulers demonstrates our method's effectiveness in achieving nearly $3\times$ speedup while maintaining original performance levels, offering a practical real-time solution without compromising generation quality.
Towards Privacy-preserved Pre-training of Remote Sensing Foundation Models with Federated Mutual-guidance Learning
Mar 14, 2025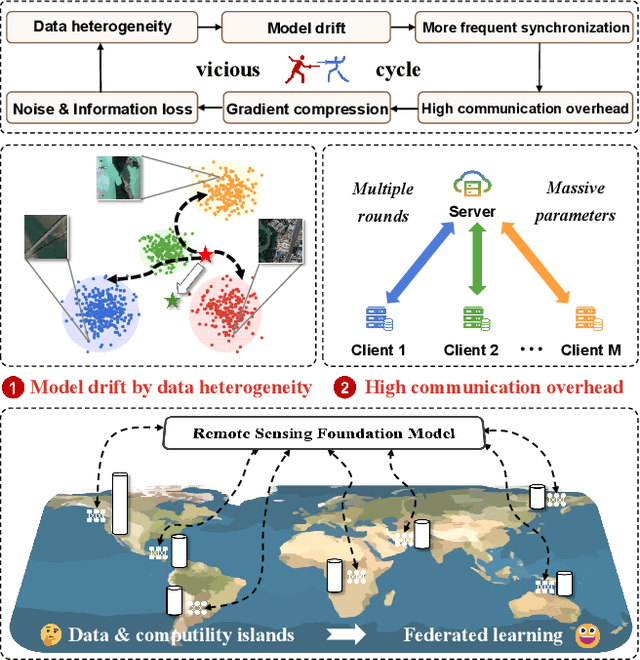
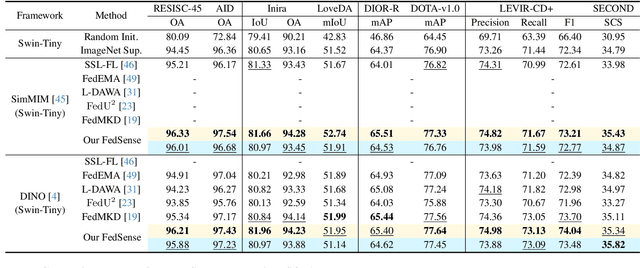
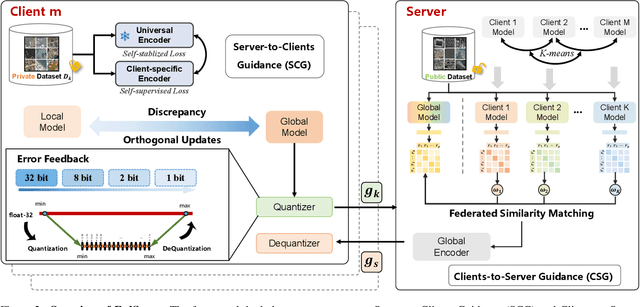
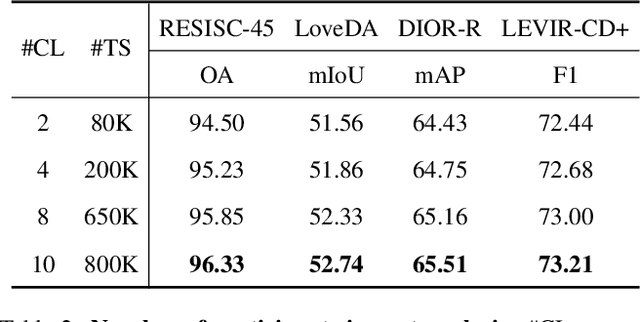
Traditional Remote Sensing Foundation models (RSFMs) are pre-trained with a data-centralized paradigm, through self-supervision on large-scale curated remote sensing data. For each institution, however, pre-training RSFMs with limited data in a standalone manner may lead to suboptimal performance, while aggregating remote sensing data from multiple institutions for centralized pre-training raises privacy concerns. Seeking for collaboration is a promising solution to resolve this dilemma, where multiple institutions can collaboratively train RSFMs without sharing private data. In this paper, we propose a novel privacy-preserved pre-training framework (FedSense), which enables multiple institutions to collaboratively train RSFMs without sharing private data. However, it is a non-trivial task hindered by a vicious cycle, which results from model drift by remote sensing data heterogeneity and high communication overhead. To break this vicious cycle, we introduce Federated Mutual-guidance Learning. Specifically, we propose a Server-to-Clients Guidance (SCG) mechanism to guide clients updates towards global-flatness optimal solutions. Additionally, we propose a Clients-to-Server Guidance (CSG) mechanism to inject local knowledge into the server by low-bit communication. Extensive experiments on four downstream tasks demonstrate the effectiveness of our FedSense in both full-precision and communication-reduced scenarios, showcasing remarkable communication efficiency and performance gains.
Enhancing Traffic Signal Control through Model-based Reinforcement Learning and Policy Reuse
Mar 11, 2025



Multi-agent reinforcement learning (MARL) has shown significant potential in traffic signal control (TSC). However, current MARL-based methods often suffer from insufficient generalization due to the fixed traffic patterns and road network conditions used during training. This limitation results in poor adaptability to new traffic scenarios, leading to high retraining costs and complex deployment. To address this challenge, we propose two algorithms: PLight and PRLight. PLight employs a model-based reinforcement learning approach, pretraining control policies and environment models using predefined source-domain traffic scenarios. The environment model predicts the state transitions, which facilitates the comparison of environmental features. PRLight further enhances adaptability by adaptively selecting pre-trained PLight agents based on the similarity between the source and target domains to accelerate the learning process in the target domain. We evaluated the algorithms through two transfer settings: (1) adaptability to different traffic scenarios within the same road network, and (2) generalization across different road networks. The results show that PRLight significantly reduces the adaptation time compared to learning from scratch in new TSC scenarios, achieving optimal performance using similarities between available and target scenarios.
Using a single actor to output personalized policy for different intersections
Mar 10, 2025



Recently, with the development of Multi-agent reinforcement learning (MARL), adaptive traffic signal control (ATSC) has achieved satisfactory results. In traffic scenarios with multiple intersections, MARL treats each intersection as an agent and optimizes traffic signal control strategies through learning and real-time decision-making. Considering that observation distributions of intersections might be different in real-world scenarios, shared parameter methods might lack diversity and thus lead to high generalization requirements in the shared-policy network. A typical solution is to increase the size of network parameters. However, simply increasing the scale of the network does not necessarily improve policy generalization, which is validated in our experiments. Accordingly, an approach that considers both the personalization of intersections and the efficiency of parameter sharing is required. To this end, we propose Hyper-Action Multi-Head Proximal Policy Optimization (HAMH-PPO), a Centralized Training with Decentralized Execution (CTDE) MARL method that utilizes a shared PPO policy network to deliver personalized policies for intersections with non-iid observation distributions. The centralized critic in HAMH-PPO uses graph attention units to calculate the graph representations of all intersections and outputs a set of value estimates with multiple output heads for each intersection. The decentralized execution actor takes the local observation history as input and output distributions of action as well as a so-called hyper-action to balance the multiple values estimated from the centralized critic to further guide the updating of TSC policies. The combination of hyper-action and multi-head values enables multiple agents to share a single actor-critic while achieving personalized policies.
Representation Purification for End-to-End Speech Translation
Dec 05, 2024



Speech-to-text translation (ST) is a cross-modal task that involves converting spoken language into text in a different language. Previous research primarily focused on enhancing speech translation by facilitating knowledge transfer from machine translation, exploring various methods to bridge the gap between speech and text modalities. Despite substantial progress made, factors in speech that are not relevant to translation content, such as timbre and rhythm, often limit the efficiency of knowledge transfer. In this paper, we conceptualize speech representation as a combination of content-agnostic and content-relevant factors. We examine the impact of content-agnostic factors on translation performance through preliminary experiments and observe a significant performance deterioration when content-agnostic perturbations are introduced to speech signals. To address this issue, we propose a \textbf{S}peech \textbf{R}epresentation \textbf{P}urification with \textbf{S}upervision \textbf{E}nhancement (SRPSE) framework, which excludes the content-agnostic components within speech representations to mitigate their negative impact on ST. Experiments on MuST-C and CoVoST-2 datasets demonstrate that SRPSE significantly improves translation performance across all translation directions in three settings and achieves preeminent performance under a \textit{transcript-free} setting.
DeSiRe-GS: 4D Street Gaussians for Static-Dynamic Decomposition and Surface Reconstruction for Urban Driving Scenes
Nov 18, 2024



We present DeSiRe-GS, a self-supervised gaussian splatting representation, enabling effective static-dynamic decomposition and high-fidelity surface reconstruction in complex driving scenarios. Our approach employs a two-stage optimization pipeline of dynamic street Gaussians. In the first stage, we extract 2D motion masks based on the observation that 3D Gaussian Splatting inherently can reconstruct only the static regions in dynamic environments. These extracted 2D motion priors are then mapped into the Gaussian space in a differentiable manner, leveraging an efficient formulation of dynamic Gaussians in the second stage. Combined with the introduced geometric regularizations, our method are able to address the over-fitting issues caused by data sparsity in autonomous driving, reconstructing physically plausible Gaussians that align with object surfaces rather than floating in air. Furthermore, we introduce temporal cross-view consistency to ensure coherence across time and viewpoints, resulting in high-quality surface reconstruction. Comprehensive experiments demonstrate the efficiency and effectiveness of DeSiRe-GS, surpassing prior self-supervised arts and achieving accuracy comparable to methods relying on external 3D bounding box annotations. Code is available at \url{https://github.com/chengweialan/DeSiRe-GS}
Transfer Learning across Different Chemical Domains: Virtual Screening of Organic Materials with Deep Learning Models Pretrained on Small Molecule and Chemical Reaction Data
Nov 30, 2023Machine learning prediction of organic materials properties is an efficient virtual screening method ahead of more expensive screening methods. However, this approach has suffered from insufficient labeled data on organic materials to train state-of-the-art machine learning models. In this study, we demonstrate that drug-like small molecule and chemical reaction databases can be used to pretrain the BERT model for the virtual screening of organic materials. Among the BERT models fine-tuned by five virtual screening tasks on organic materials, the USPTO-SMILES pretrained BERT model had R2 > 0.90 for two tasks and R2 > 0.82 for one, which was generally superior to the same models pretrained by the small molecule or organic materials databases, as well as to the other three traditional machine learning models trained directly on the virtual screening task data. The superior performance of the USPTO-SMILES pretrained BERT model is due to the greater variety of organic building blocks in the USPTO database and the broader coverage of the chemical space. The even better performance of the BERT model pretrained externally from a chemical reaction database with additional sources of chemical reactions strengthens our proof of concept that transfer learning across different chemical domains is practical for the virtual screening of organic materials.