 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDual-Teacher Distillation with Subnetwork Rectification for Black-Box Domain Adaptation
Mar 25, 2026Assuming that neither source data nor the source model is accessible, black box domain adaptation represents a highly practical yet extremely challenging setting, as transferable information is restricted to the predictions of the black box source model, which can only be queried using target samples. Existing approaches attempt to extract transferable knowledge through pseudo label refinement or by leveraging external vision language models (ViLs), but they often suffer from noisy supervision or insufficient utilization of the semantic priors provided by ViLs, which ultimately hinder adaptation performance. To overcome these limitations, we propose a dual teacher distillation with subnetwork rectification (DDSR) model that jointly exploits the specific knowledge embedded in black box source models and the general semantic information of a ViL. DDSR adaptively integrates their complementary predictions to generate reliable pseudo labels for the target domain and introduces a subnetwork driven regularization strategy to mitigate overfitting caused by noisy supervision. Furthermore, the refined target predictions iteratively enhance both the pseudo labels and ViL prompts, enabling more accurate and semantically consistent adaptation. Finally, the target model is further optimized through self training with classwise prototypes. Extensive experiments on multiple benchmark datasets validate the effectiveness of our approach, demonstrating consistent improvements over state of the art methods, including those using source data or models.
Conditional Diffusion Feature Refinement for Continuous Sign Language Recognition
May 05, 2023



In this work, we are dedicated to leveraging the denoising diffusion models' success and formulating feature refinement as the autoencoder-formed diffusion process. The state-of-the-art CSLR framework consists of a spatial module, a visual module, a sequence module, and a sequence learning function. However, this framework has faced sequence module overfitting caused by the objective function and small-scale available benchmarks, resulting in insufficient model training. To overcome the overfitting problem, some CSLR studies enforce the sequence module to learn more visual temporal information or be guided by more informative supervision to refine its representations. In this work, we propose a novel autoencoder-formed conditional diffusion feature refinement~(ACDR) to refine the sequence representations to equip desired properties by learning the encoding-decoding optimization process in an end-to-end way. Specifically, for the ACDR, a noising Encoder is proposed to progressively add noise equipped with semantic conditions to the sequence representations. And a denoising Decoder is proposed to progressively denoise the noisy sequence representations with semantic conditions. Therefore, the sequence representations can be imbued with the semantics of provided semantic conditions. Further, a semantic constraint is employed to prevent the denoised sequence representations from semantic corruption. Extensive experiments are conducted to validate the effectiveness of our ACDR, benefiting state-of-the-art methods and achieving a notable gain on three benchmarks.
DARTSRepair: Core-failure-set Guided DARTS for Network Robustness to Common Corruptions
Sep 21, 2022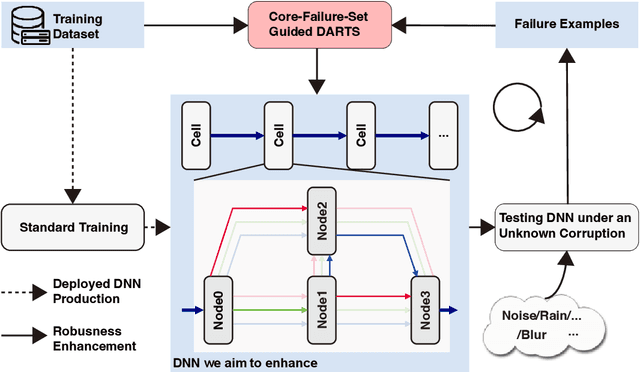

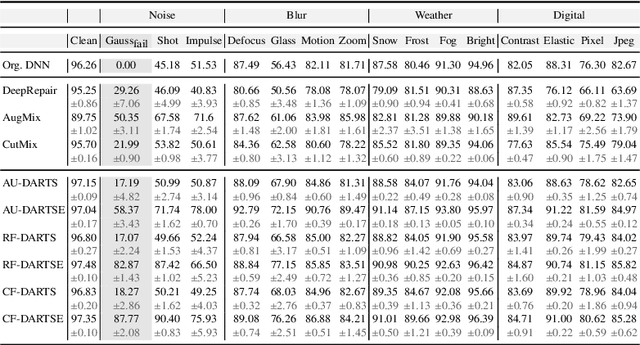
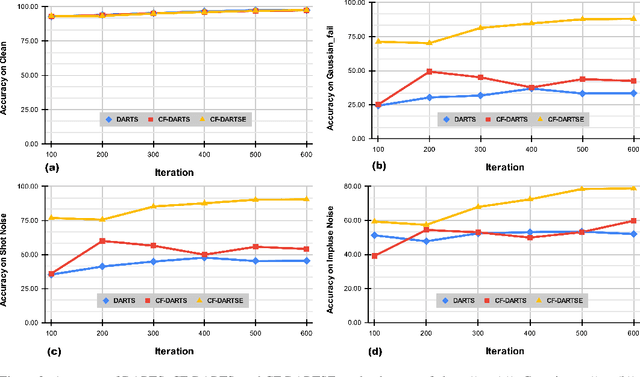
Network architecture search (NAS), in particular the differentiable architecture search (DARTS) method, has shown a great power to learn excellent model architectures on the specific dataset of interest. In contrast to using a fixed dataset, in this work, we focus on a different but important scenario for NAS: how to refine a deployed network's model architecture to enhance its robustness with the guidance of a few collected and misclassified examples that are degraded by some real-world unknown corruptions having a specific pattern (e.g., noise, blur, etc.). To this end, we first conduct an empirical study to validate that the model architectures can be definitely related to the corruption patterns. Surprisingly, by just adding a few corrupted and misclassified examples (e.g., $10^3$ examples) to the clean training dataset (e.g., $5.0 \times 10^4$ examples), we can refine the model architecture and enhance the robustness significantly. To make it more practical, the key problem, i.e., how to select the proper failure examples for the effective NAS guidance, should be carefully investigated. Then, we propose a novel core-failure-set guided DARTS that embeds a K-center-greedy algorithm for DARTS to select suitable corrupted failure examples to refine the model architecture. We use our method for DARTS-refined DNNs on the clean as well as 15 corruptions with the guidance of four specific real-world corruptions. Compared with the state-of-the-art NAS as well as data-augmentation-based enhancement methods, our final method can achieve higher accuracy on both corrupted datasets and the original clean dataset. On some of the corruption patterns, we can achieve as high as over 45% absolute accuracy improvements.
DeepMix: Online Auto Data Augmentation for Robust Visual Object Tracking
May 03, 2021
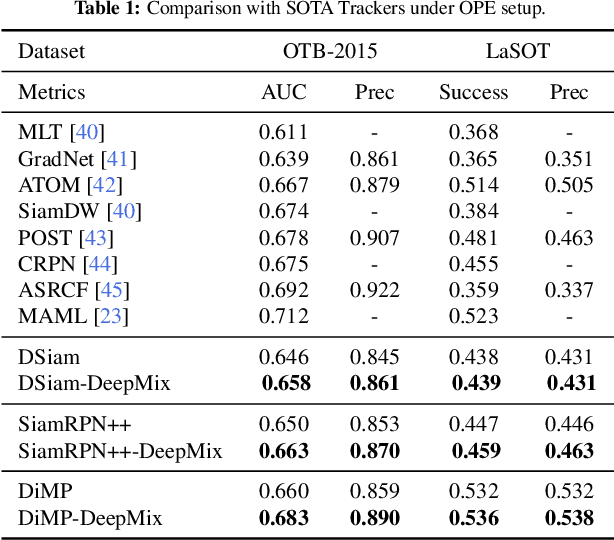
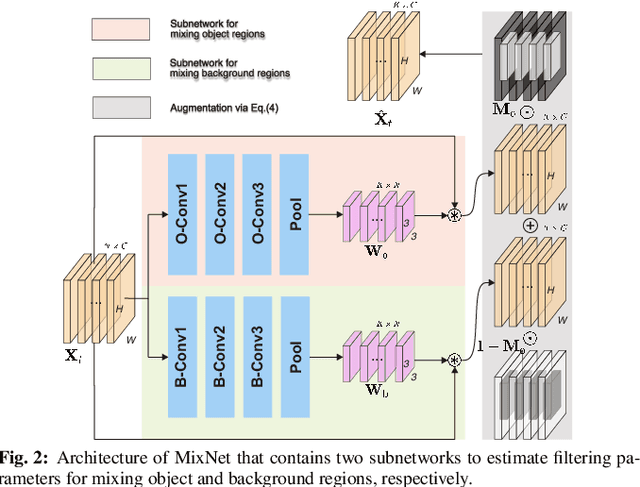
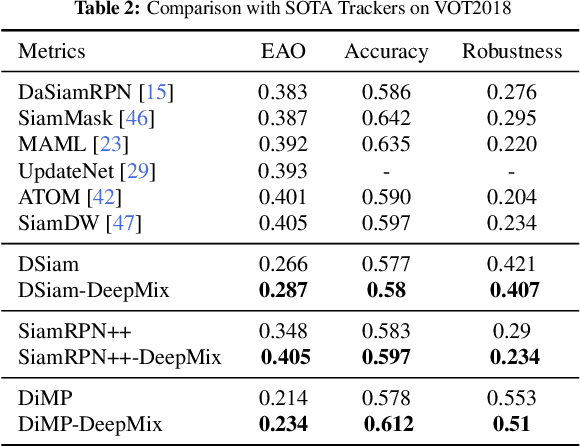
Online updating of the object model via samples from historical frames is of great importance for accurate visual object tracking. Recent works mainly focus on constructing effective and efficient updating methods while neglecting the training samples for learning discriminative object models, which is also a key part of a learning problem. In this paper, we propose the DeepMix that takes historical samples' embeddings as input and generates augmented embeddings online, enhancing the state-of-the-art online learning methods for visual object tracking. More specifically, we first propose the online data augmentation for tracking that online augments the historical samples through object-aware filtering. Then, we propose MixNet which is an offline trained network for performing online data augmentation within one-step, enhancing the tracking accuracy while preserving high speeds of the state-of-the-art online learning methods. The extensive experiments on three different tracking frameworks, i.e., DiMP, DSiam, and SiamRPN++, and three large-scale and challenging datasets, \ie, OTB-2015, LaSOT, and VOT, demonstrate the effectiveness and advantages of the proposed method.
Independent Reinforcement Learning for Weakly Cooperative Multiagent Traffic Control Problem
Apr 22, 2021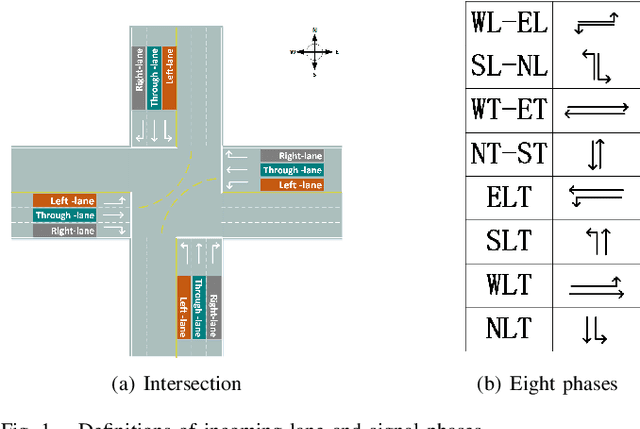

The adaptive traffic signal control (ATSC) problem can be modeled as a multiagent cooperative game among urban intersections, where intersections cooperate to optimize their common goal. Recently, reinforcement learning (RL) has achieved marked successes in managing sequential decision making problems, which motivates us to apply RL in the ASTC problem. Here we use independent reinforcement learning (IRL) to solve a complex traffic cooperative control problem in this study. One of the largest challenges of this problem is that the observation information of intersection is typically partially observable, which limits the learning performance of IRL algorithms. To this, we model the traffic control problem as a partially observable weak cooperative traffic model (PO-WCTM) to optimize the overall traffic situation of a group of intersections. Different from a traditional IRL task that averages the returns of all agents in fully cooperative games, the learning goal of each intersection in PO-WCTM is to reduce the cooperative difficulty of learning, which is also consistent with the traffic environment hypothesis. We also propose an IRL algorithm called Cooperative Important Lenient Double DQN (CIL-DDQN), which extends Double DQN (DDQN) algorithm using two mechanisms: the forgetful experience mechanism and the lenient weight training mechanism. The former mechanism decreases the importance of experiences stored in the experience reply buffer, which deals with the problem of experience failure caused by the strategy change of other agents. The latter mechanism increases the weight experiences with high estimation and `leniently' trains the DDQN neural network, which improves the probability of the selection of cooperative joint strategies. Experimental results show that CIL-DDQN outperforms other methods in almost all performance indicators of the traffic control problem.
Discriminative Segmentation Tracking Using Dual Memory Banks
Sep 29, 2020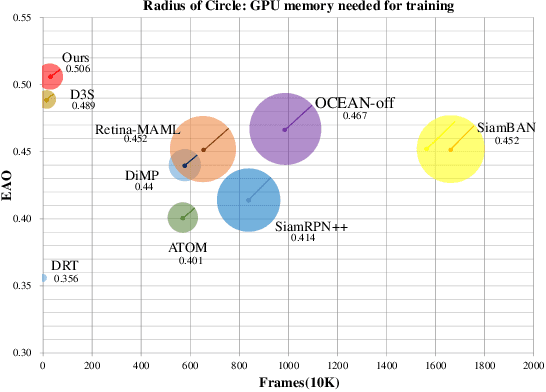
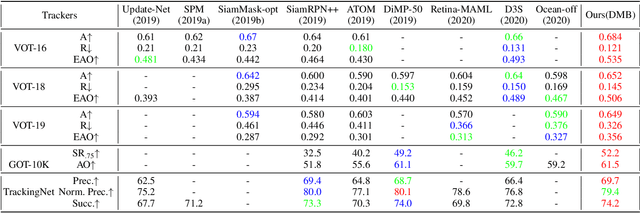
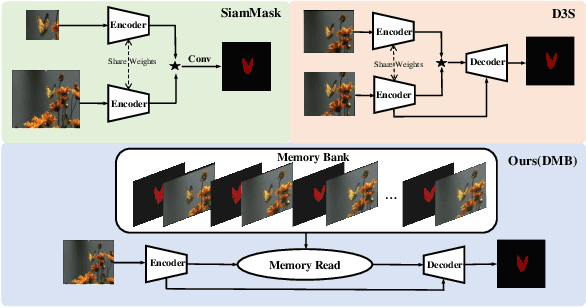
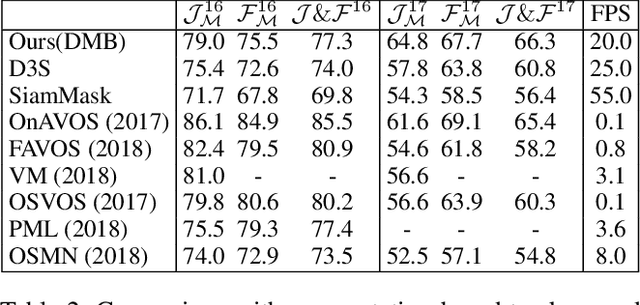
Existing template-based trackers usually localize the target in each frame with bounding box, thereby being limited in learning pixel-wise representation and handling complex and non-rigid transformation of the target. Further, existing segmentation tracking methods are still insufficient in modeling and exploiting dense correspondence of target pixels across frames. To overcome these limitations, this work presents a novel discriminative segmentation tracking architecture equipped with dual memory banks, i.e., appearance memory bank and spatial memory bank. In particular, the appearance memory bank utilizes spatial and temporal non-local similarity to propagate segmentation mask to the current frame, and we further treat discriminative correlation filter as spatial memory bank to store the mapping between feature map and spatial map. Without bells and whistles, our simple-yet-effective tracking architecture sets a new state-of-the-art on the VOT2016, VOT2018, VOT2019, GOT-10K and TrackingNet benchmarks, especially achieving the EAO of 0.535 and 0.506 respectively on VOT2016 and VOT2018. Moreover, our approach outperforms the leading segmentation tracker D3S on two video object segmentation benchmarks DAVIS16 and DAVIS17. The source code will be released at https://github.com/phiphiphi31/DMB.
A Multi-view CNN-based Acoustic Classification System for Automatic Animal Species Identification
Feb 23, 2020
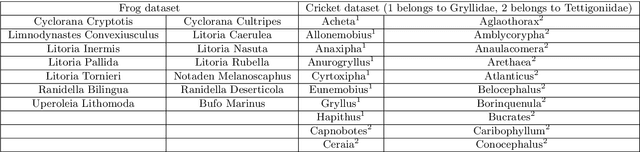
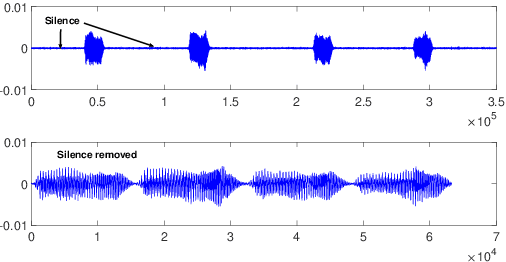

Automatic identification of animal species by their vocalization is an important and challenging task. Although many kinds of audio monitoring system have been proposed in the literature, they suffer from several disadvantages such as non-trivial feature selection, accuracy degradation because of environmental noise or intensive local computation. In this paper, we propose a deep learning based acoustic classification framework for Wireless Acoustic Sensor Network (WASN). The proposed framework is based on cloud architecture which relaxes the computational burden on the wireless sensor node. To improve the recognition accuracy, we design a multi-view Convolution Neural Network (CNN) to extract the short-, middle-, and long-term dependencies in parallel. The evaluation on two real datasets shows that the proposed architecture can achieve high accuracy and outperforms traditional classification systems significantly when the environmental noise dominate the audio signal (low SNR). Moreover, we implement and deploy the proposed system on a testbed and analyse the system performance in real-world environments. Both simulation and real-world evaluation demonstrate the accuracy and robustness of the proposed acoustic classification system in distinguishing species of animals.
SPARK: Spatial-aware Online Incremental Attack Against Visual Tracking
Nov 26, 2019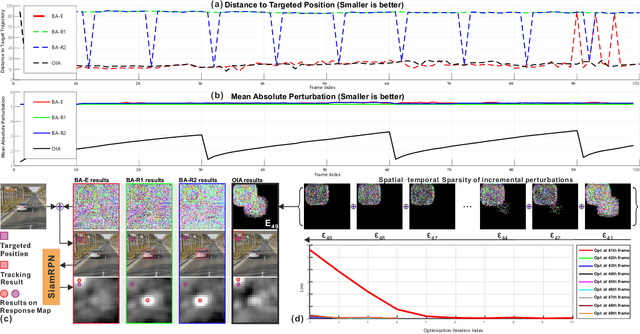

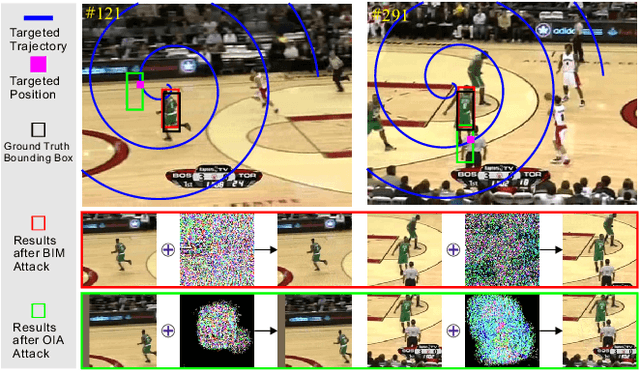

Adversarial attacks of deep neural networks have been intensively studied on image, audio, natural language, patch, and pixel classification tasks. Nevertheless, as a typical while important real-world application, the adversarial attacks of online video object tracking that traces an object's moving trajectory instead of its category are rarely explored. In this paper, we identify a new task for the adversarial attack to visual tracking: online generating imperceptible perturbations that mislead trackers along an incorrect~(Untargeted Attack, UA) or specified trajectory~(Targeted Attack, TA). To this end, we first propose a \textit{spatial-aware} basic attack by adapting existing attack methods, i.e., FGSM, BIM, and C\&W, and comprehensively analyze the attacking performance. We identify that online object tracking poses two new challenges: 1) it is difficult to generate imperceptible perturbations that can transfer across frames, and 2) real-time trackers require the attack to satisfy a certain level of efficiency. To address these challenges, we further propose the \textit{SPatial-Aware online incRemental attacK~(SPARK)} that performs spatial-temporal sparse incremental perturbations online and makes the adversarial attack less perceptible. In addition, as an optimization-based method, SPARK quickly converges to very small losses within several iterations by considering historical incremental perturbations, making it much more efficient than the basic attacks. The in-depth evaluation on state-of-the-art trackers (i.e., SiamRPN with Alex, MobileNetv2, and ResNet-50) on OTB100, VOT2018, UAV123, and LaSOT demonstrates the effectiveness and transferability of SPARK in misleading the trackers under both UA and TA with minor perturbations.
SCC-rFMQ Learning in Cooperative Markov Games with Continuous Actions
Sep 18, 2018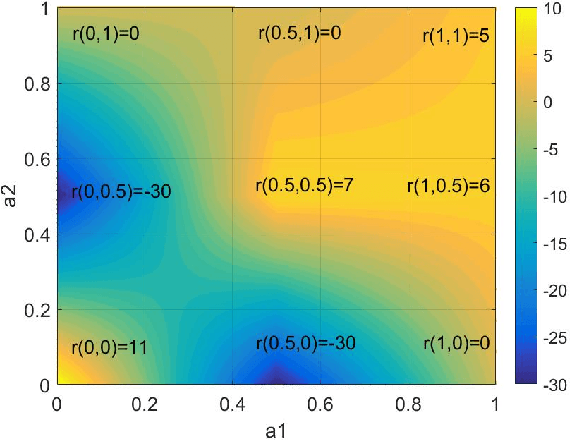
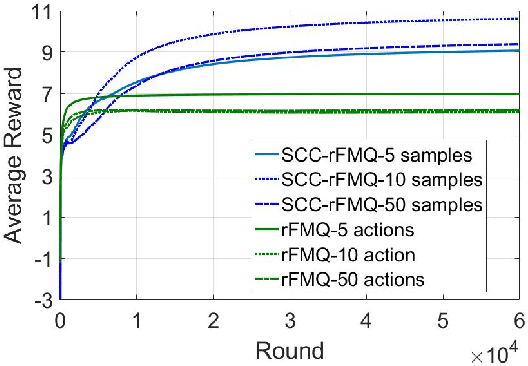
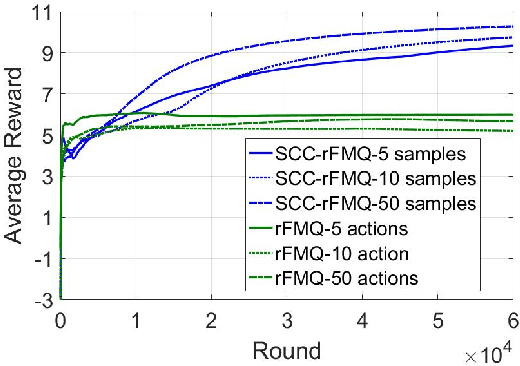
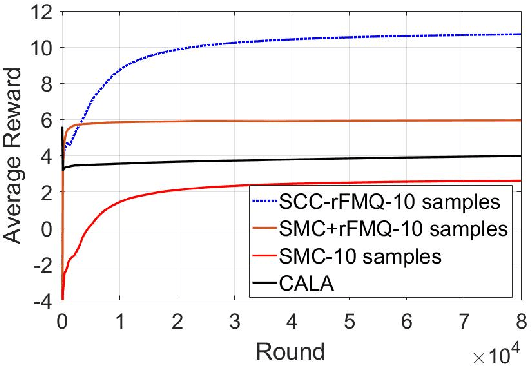
Although many reinforcement learning methods have been proposed for learning the optimal solutions in single-agent continuous-action domains, multiagent coordination domains with continuous actions have received relatively few investigations. In this paper, we propose an independent learner hierarchical method, named Sample Continuous Coordination with recursive Frequency Maximum Q-Value (SCC-rFMQ), which divides the cooperative problem with continuous actions into two layers. The first layer samples a finite set of actions from the continuous action spaces by a re-sampling mechanism with variable exploratory rates, and the second layer evaluates the actions in the sampled action set and updates the policy using a reinforcement learning cooperative method. By constructing cooperative mechanisms at both levels, SCC-rFMQ can handle cooperative problems in continuous action cooperative Markov games effectively. The effectiveness of SCC-rFMQ is experimentally demonstrated on two well-designed games, i.e., a continuous version of the climbing game and a cooperative version of the boat problem. Experimental results show that SCC-rFMQ outperforms other reinforcement learning algorithms.
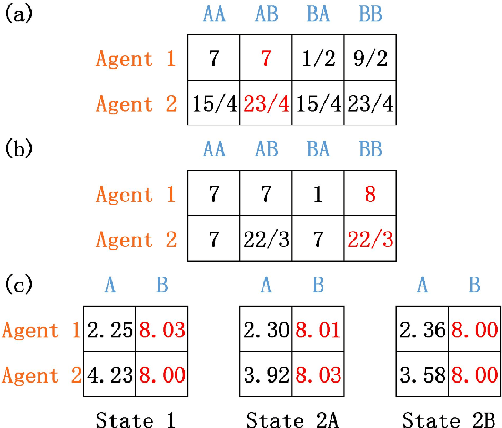
SA-IGA: A Multiagent Reinforcement Learning Method Towards Socially Optimal Outcomes
Mar 08, 2018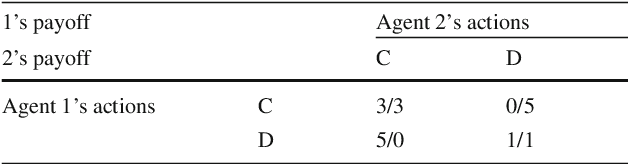


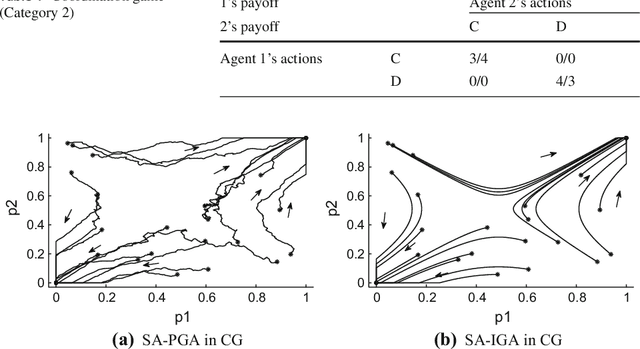
In multiagent environments, the capability of learning is important for an agent to behave appropriately in face of unknown opponents and dynamic environment. From the system designer's perspective, it is desirable if the agents can learn to coordinate towards socially optimal outcomes, while also avoiding being exploited by selfish opponents. To this end, we propose a novel gradient ascent based algorithm (SA-IGA) which augments the basic gradient-ascent algorithm by incorporating social awareness into the policy update process. We theoretically analyze the learning dynamics of SA-IGA using dynamical system theory and SA-IGA is shown to have linear dynamics for a wide range of games including symmetric games. The learning dynamics of two representative games (the prisoner's dilemma game and the coordination game) are analyzed in details. Based on the idea of SA-IGA, we further propose a practical multiagent learning algorithm, called SA-PGA, based on Q-learning update rule. Simulation results show that SA-PGA agent can achieve higher social welfare than previous social-optimality oriented Conditional Joint Action Learner (CJAL) and also is robust against individually rational opponents by reaching Nash equilibrium solutions.