 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLRR: Language-Driven Resamplable Continuous Representation against Adversarial Tracking Attacks
Apr 09, 2024



Visual object tracking plays a critical role in visual-based autonomous systems, as it aims to estimate the position and size of the object of interest within a live video. Despite significant progress made in this field, state-of-the-art (SOTA) trackers often fail when faced with adversarial perturbations in the incoming frames. This can lead to significant robustness and security issues when these trackers are deployed in the real world. To achieve high accuracy on both clean and adversarial data, we propose building a spatial-temporal continuous representation using the semantic text guidance of the object of interest. This novel continuous representation enables us to reconstruct incoming frames to maintain semantic and appearance consistency with the object of interest and its clean counterparts. As a result, our proposed method successfully defends against different SOTA adversarial tracking attacks while maintaining high accuracy on clean data. In particular, our method significantly increases tracking accuracy under adversarial attacks with around 90% relative improvement on UAV123, which is even higher than the accuracy on clean data.
Boosting Transferability in Vision-Language Attacks via Diversification along the Intersection Region of Adversarial Trajectory
Mar 19, 2024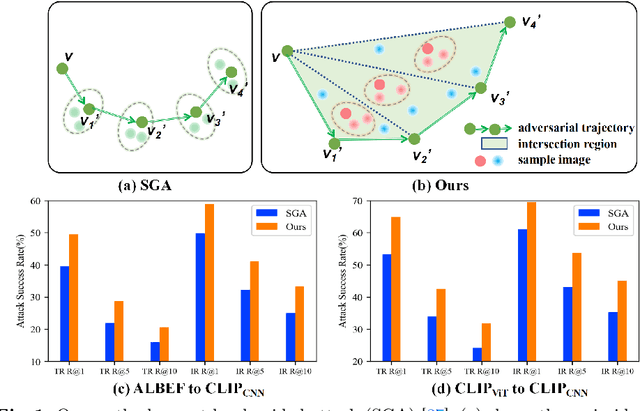



Vision-language pre-training (VLP) models exhibit remarkable capabilities in comprehending both images and text, yet they remain susceptible to multimodal adversarial examples (AEs). Strengthening adversarial attacks and uncovering vulnerabilities, especially common issues in VLP models (e.g., high transferable AEs), can stimulate further research on constructing reliable and practical VLP models. A recent work (i.e., Set-level guidance attack) indicates that augmenting image-text pairs to increase AE diversity along the optimization path enhances the transferability of adversarial examples significantly. However, this approach predominantly emphasizes diversity around the online adversarial examples (i.e., AEs in the optimization period), leading to the risk of overfitting the victim model and affecting the transferability. In this study, we posit that the diversity of adversarial examples towards the clean input and online AEs are both pivotal for enhancing transferability across VLP models. Consequently, we propose using diversification along the intersection region of adversarial trajectory to expand the diversity of AEs. To fully leverage the interaction between modalities, we introduce text-guided adversarial example selection during optimization. Furthermore, to further mitigate the potential overfitting, we direct the adversarial text deviating from the last intersection region along the optimization path, rather than adversarial images as in existing methods. Extensive experiments affirm the effectiveness of our method in improving transferability across various VLP models and downstream vision-and-language tasks (e.g., Image-Text Retrieval(ITR), Visual Grounding(VG), Image Captioning(IC)).
DARTSRepair: Core-failure-set Guided DARTS for Network Robustness to Common Corruptions
Sep 21, 2022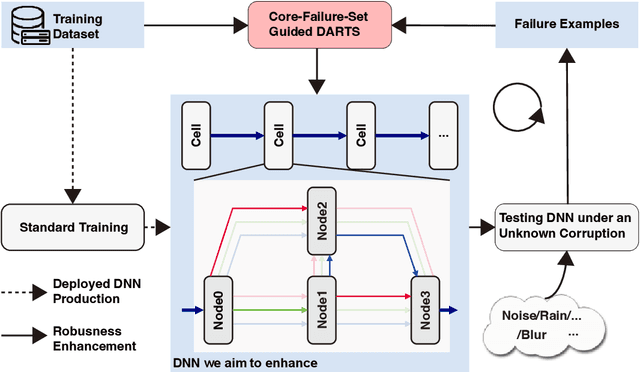

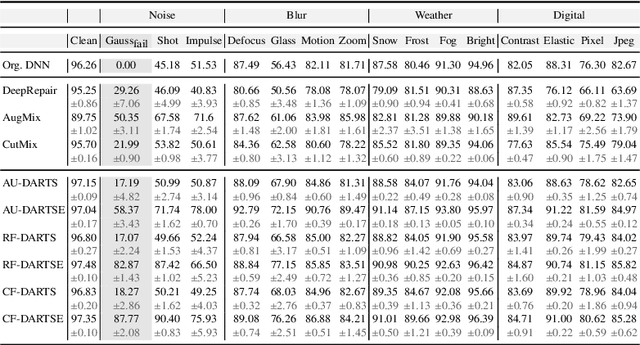
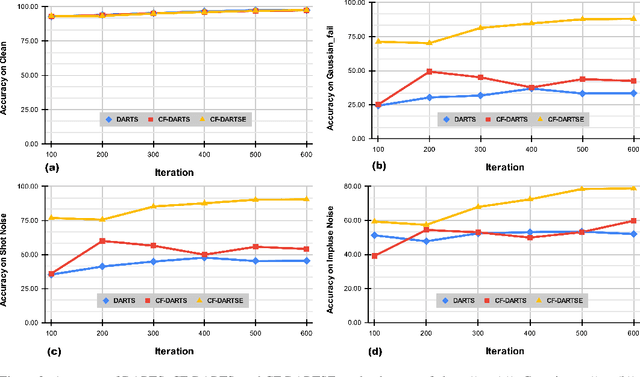
Network architecture search (NAS), in particular the differentiable architecture search (DARTS) method, has shown a great power to learn excellent model architectures on the specific dataset of interest. In contrast to using a fixed dataset, in this work, we focus on a different but important scenario for NAS: how to refine a deployed network's model architecture to enhance its robustness with the guidance of a few collected and misclassified examples that are degraded by some real-world unknown corruptions having a specific pattern (e.g., noise, blur, etc.). To this end, we first conduct an empirical study to validate that the model architectures can be definitely related to the corruption patterns. Surprisingly, by just adding a few corrupted and misclassified examples (e.g., $10^3$ examples) to the clean training dataset (e.g., $5.0 \times 10^4$ examples), we can refine the model architecture and enhance the robustness significantly. To make it more practical, the key problem, i.e., how to select the proper failure examples for the effective NAS guidance, should be carefully investigated. Then, we propose a novel core-failure-set guided DARTS that embeds a K-center-greedy algorithm for DARTS to select suitable corrupted failure examples to refine the model architecture. We use our method for DARTS-refined DNNs on the clean as well as 15 corruptions with the guidance of four specific real-world corruptions. Compared with the state-of-the-art NAS as well as data-augmentation-based enhancement methods, our final method can achieve higher accuracy on both corrupted datasets and the original clean dataset. On some of the corruption patterns, we can achieve as high as over 45% absolute accuracy improvements.
DeepMix: Online Auto Data Augmentation for Robust Visual Object Tracking
May 03, 2021
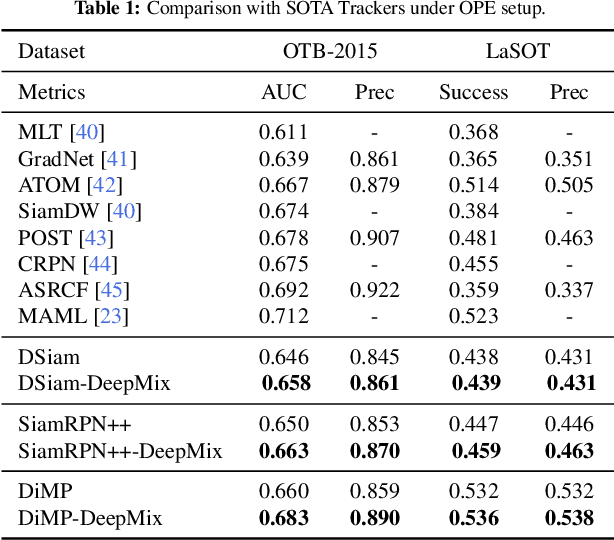
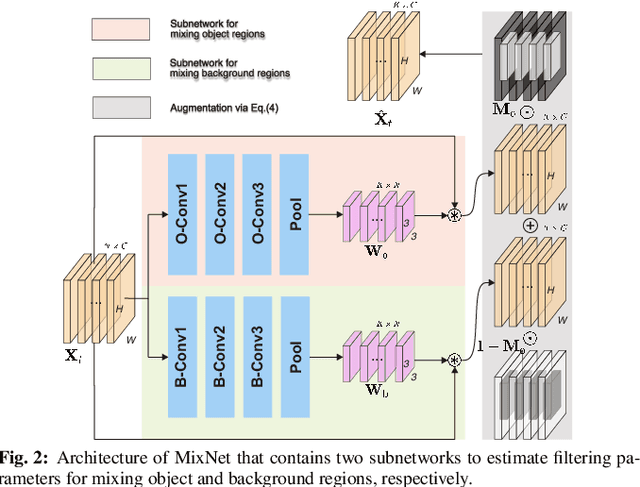
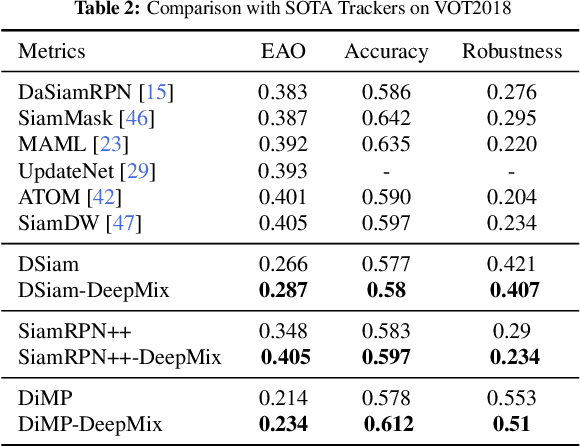
Online updating of the object model via samples from historical frames is of great importance for accurate visual object tracking. Recent works mainly focus on constructing effective and efficient updating methods while neglecting the training samples for learning discriminative object models, which is also a key part of a learning problem. In this paper, we propose the DeepMix that takes historical samples' embeddings as input and generates augmented embeddings online, enhancing the state-of-the-art online learning methods for visual object tracking. More specifically, we first propose the online data augmentation for tracking that online augments the historical samples through object-aware filtering. Then, we propose MixNet which is an offline trained network for performing online data augmentation within one-step, enhancing the tracking accuracy while preserving high speeds of the state-of-the-art online learning methods. The extensive experiments on three different tracking frameworks, i.e., DiMP, DSiam, and SiamRPN++, and three large-scale and challenging datasets, \ie, OTB-2015, LaSOT, and VOT, demonstrate the effectiveness and advantages of the proposed method.
Making Images Undiscoverable from Co-Saliency Detection
Sep 19, 2020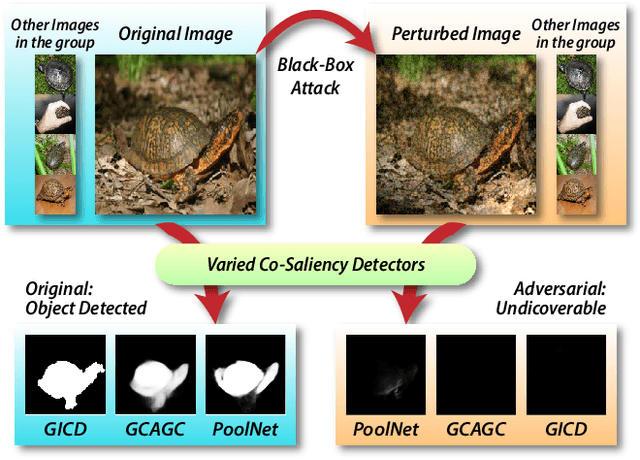

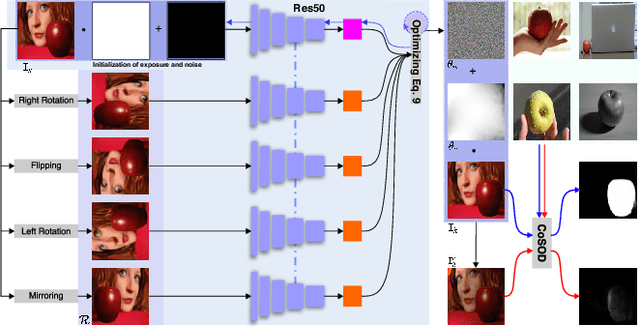
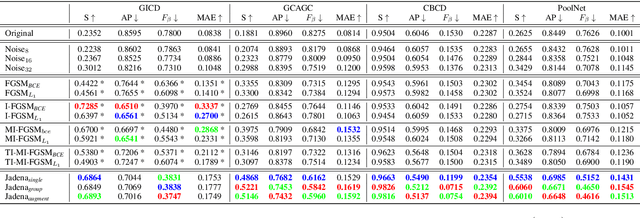
In recent years, co-saliency object detection (CoSOD) has achieved significant progress and played a key role in the retrieval-related tasks, e.g., image retrieval and video foreground detection. Nevertheless, it also inevitably posts a totally new safety and security problem, i.e., how to prevent high-profile and personal-sensitive contents from being extracted by the powerful CoSOD methods. In this paper, we address this problem from the perspective of adversarial attack and identify a novel task, i.e., adversarial co-saliency attack: given an image selected from an image group containing some common and salient objects, how to generate an adversarial version that can mislead CoSOD methods to predict incorrect co-salient regions. Note that, compared with general adversarial attacks for classification, this new task introduces two extra challenges for existing whitebox adversarial noise attacks: (1) low success rate due to the diverse appearance of images in the image group; (2) low transferability across CoSOD methods due to the considerable difference between CoSOD pipelines. To address these challenges, we propose the very first blackbox joint adversarial exposure & noise attack (Jadena) where we jointly and locally tune the exposure and additive perturbations of the image according to a newly designed high-feature-level contrast-sensitive loss function. Our method, without any information of the state-of-the-art CoSOD methods, leads to significant performance degradation on various co-saliency detection datasets and make the co-salient objects undetectable, which can be strongly practical in nowadays where large-scale personal photos are shared on the internet and should be properly and securely preserved.