 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Relighting against Face Recognition
Sep 01, 2021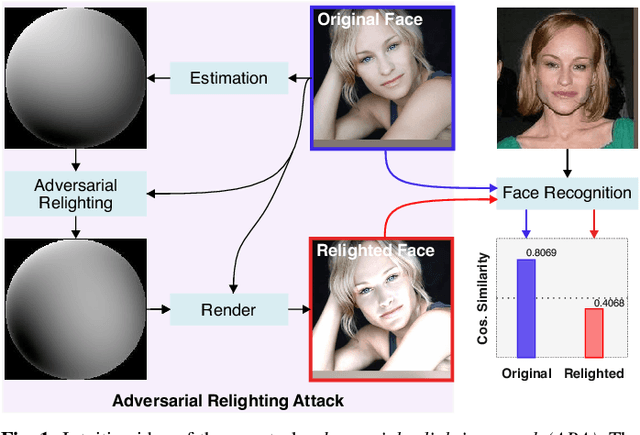

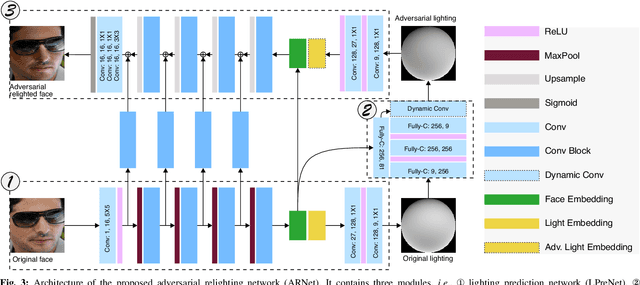
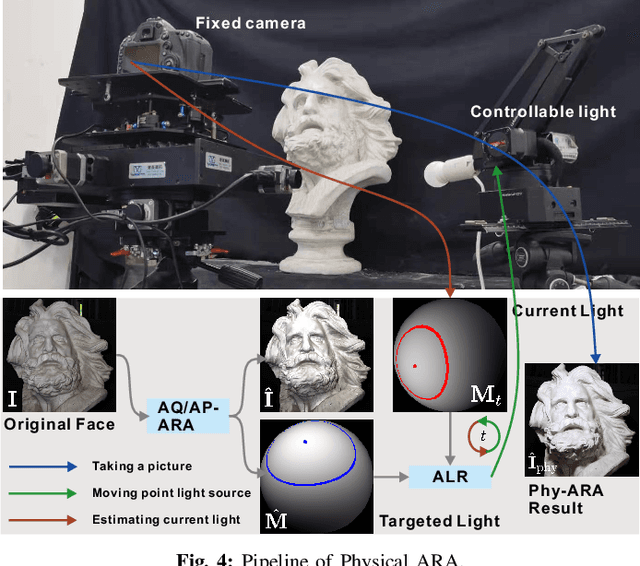
Deep face recognition (FR) has achieved significantly high accuracy on several challenging datasets and fosters successful real-world applications, even showing high robustness to the illumination variation that is usually regarded as a main threat to the FR system. However, in the real world, illumination variation caused by diverse lighting conditions cannot be fully covered by the limited face dataset. In this paper, we study the threat of lighting against FR from a new angle, i.e., adversarial attack, and identify a new task, i.e., adversarial relighting. Given a face image, adversarial relighting aims to produce a naturally relighted counterpart while fooling the state-of-the-art deep FR methods. To this end, we first propose the physical model-based adversarial relighting attack (ARA) denoted as albedo-quotient-based adversarial relighting attack (AQ-ARA). It generates natural adversarial light under the physical lighting model and guidance of FR systems and synthesizes adversarially relighted face images. Moreover, we propose the auto-predictive adversarial relighting attack (AP-ARA) by training an adversarial relighting network (ARNet) to automatically predict the adversarial light in a one-step manner according to different input faces, allowing efficiency-sensitive applications. More importantly, we propose to transfer the above digital attacks to physical ARA (Phy-ARA) through a precise relighting device, making the estimated adversarial lighting condition reproducible in the real world. We validate our methods on three state-of-the-art deep FR methods, i.e., FaceNet, ArcFace, and CosFace, on two public datasets. The extensive and insightful results demonstrate our work can generate realistic adversarial relighted face images fooling FR easily, revealing the threat of specific light directions and strengths.
AdvHaze: Adversarial Haze Attack
Apr 28, 2021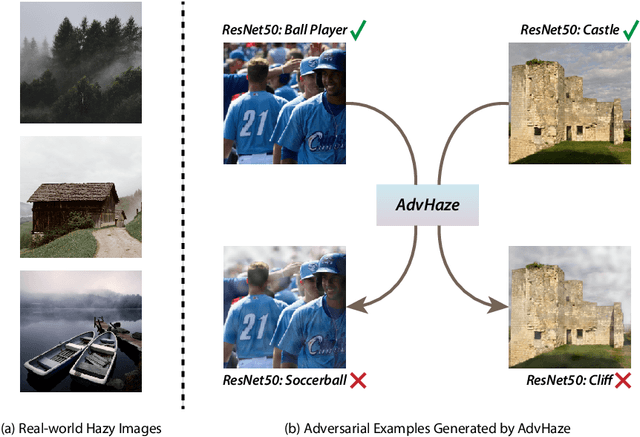
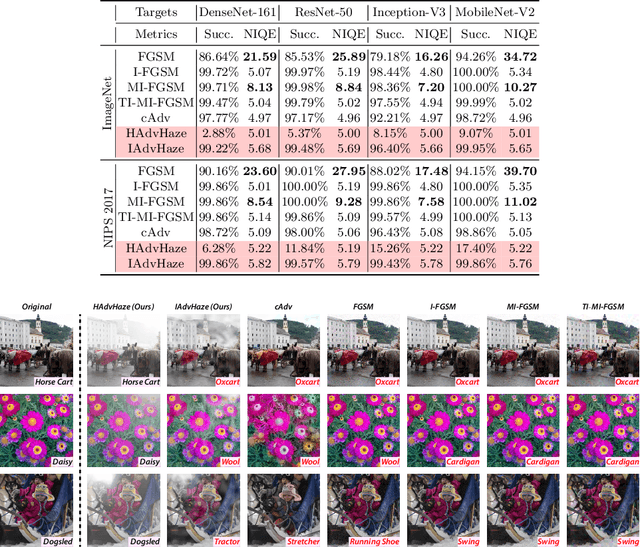

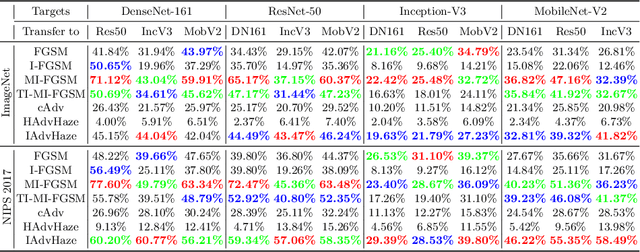
In recent years, adversarial attacks have drawn more attention for their value on evaluating and improving the robustness of machine learning models, especially, neural network models. However, previous attack methods have mainly focused on applying some $l^p$ norm-bounded noise perturbations. In this paper, we instead introduce a novel adversarial attack method based on haze, which is a common phenomenon in real-world scenery. Our method can synthesize potentially adversarial haze into an image based on the atmospheric scattering model with high realisticity and mislead classifiers to predict an incorrect class. We launch experiments on two popular datasets, i.e., ImageNet and NIPS~2017. We demonstrate that the proposed method achieves a high success rate, and holds better transferability across different classification models than the baselines. We also visualize the correlation matrices, which inspire us to jointly apply different perturbations to improve the success rate of the attack. We hope this work can boost the development of non-noise-based adversarial attacks and help evaluate and improve the robustness of DNNs.
Making Images Undiscoverable from Co-Saliency Detection
Sep 19, 2020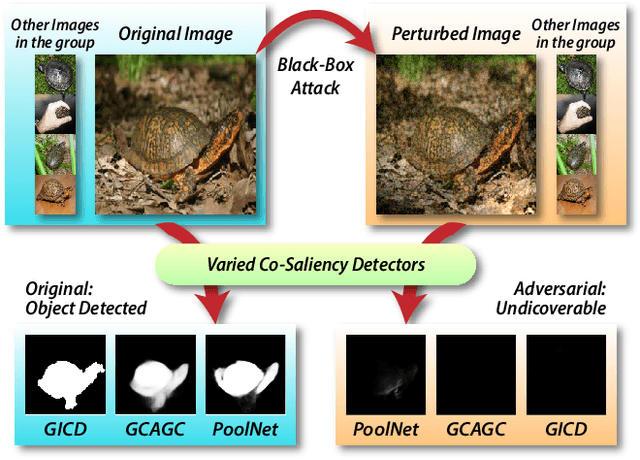

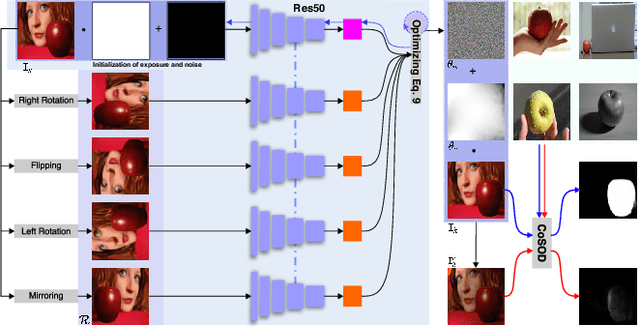
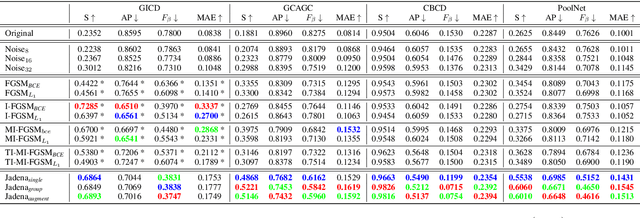
In recent years, co-saliency object detection (CoSOD) has achieved significant progress and played a key role in the retrieval-related tasks, e.g., image retrieval and video foreground detection. Nevertheless, it also inevitably posts a totally new safety and security problem, i.e., how to prevent high-profile and personal-sensitive contents from being extracted by the powerful CoSOD methods. In this paper, we address this problem from the perspective of adversarial attack and identify a novel task, i.e., adversarial co-saliency attack: given an image selected from an image group containing some common and salient objects, how to generate an adversarial version that can mislead CoSOD methods to predict incorrect co-salient regions. Note that, compared with general adversarial attacks for classification, this new task introduces two extra challenges for existing whitebox adversarial noise attacks: (1) low success rate due to the diverse appearance of images in the image group; (2) low transferability across CoSOD methods due to the considerable difference between CoSOD pipelines. To address these challenges, we propose the very first blackbox joint adversarial exposure & noise attack (Jadena) where we jointly and locally tune the exposure and additive perturbations of the image according to a newly designed high-feature-level contrast-sensitive loss function. Our method, without any information of the state-of-the-art CoSOD methods, leads to significant performance degradation on various co-saliency detection datasets and make the co-salient objects undetectable, which can be strongly practical in nowadays where large-scale personal photos are shared on the internet and should be properly and securely preserved.
Effects of Blur and Deblurring to Visual Object Tracking
Aug 21, 2019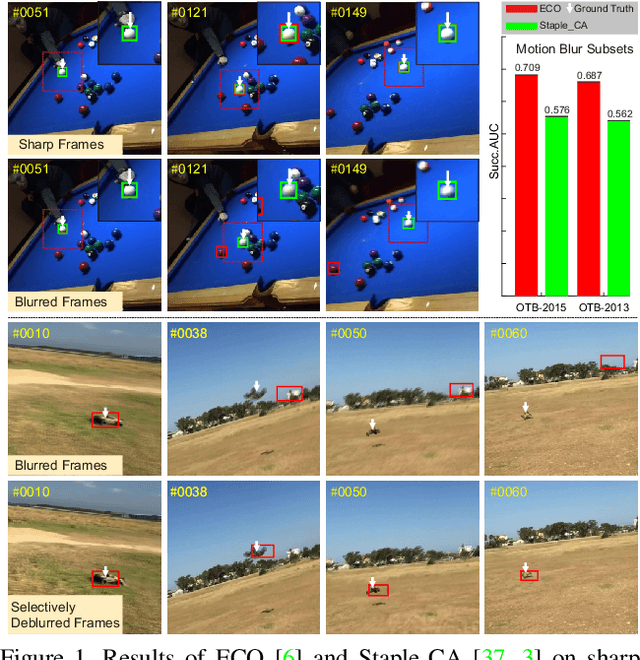

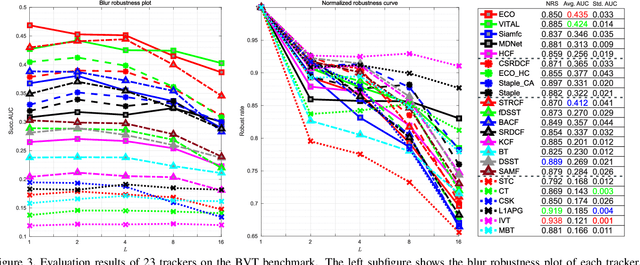
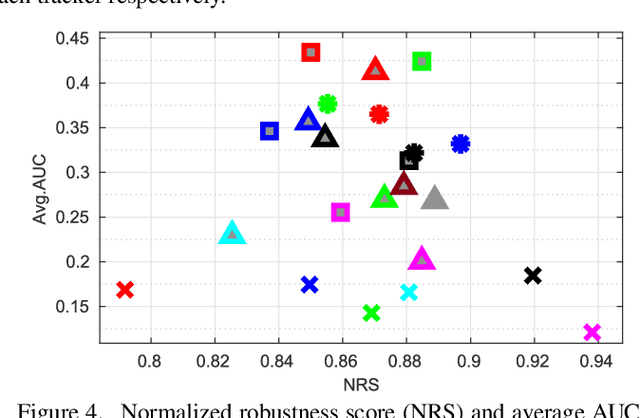
Intuitively, motion blur may hurt the performance of visual object tracking. However, we lack quantitative evaluation of tracker robustness to different levels of motion blur. Meanwhile, while image deblurring methods can produce visually clearer videos for pleasing human eyes, it is unknown whether visual object tracking can benefit from image deblurring or not. In this paper, we address these two problems by constructing a Blurred Video Tracking benchmark, which contains a variety of videos with different levels of motion blurs, as well as ground truth tracking results for evaluating trackers. We extensively evaluate 23 trackers on this benchmark and observe several new interesting results. Specifically, we find that light blur may improve the performance of many trackers, but heavy blur always hurts the tracking performance. We also find that image deblurring may help to improve tracking performance on heavily blurred videos but hurt the performance on lightly blurred videos. According to these observations, we propose a new GAN based scheme to improve the tracker robustness to motion blurs. In this scheme, a finetuned discriminator is used as an adaptive assessor to selectively deblur frames during the tracking process. We use this scheme to successfully improve the accuracy and robustness of 6 trackers.