 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoOVD: Novel Category Discovery and Embedding for Open-Vocabulary Object Detection
Mar 22, 2026Despite the remarkable progress in open-vocabulary object detection (OVD), a significant gap remains between the training and testing phases. During training, the RPN and RoI heads often misclassify unlabeled novel-category objects as background, causing some proposals to be prematurely filtered out by the RPN while others are further misclassified by the RoI head. During testing, these proposals again receive low scores and are removed in post-processing, leading to a significant drop in recall and ultimately weakening novel-category detection performance.To address these issues, we propose a novel training framework-NoOVD-which innovatively integrates a self-distillation mechanism grounded in the knowledge of frozen vision-language models (VLMs). Specifically, we design K-FPN, which leverages the pretrained knowledge of VLMs to guide the model in discovering novel-category objects and facilitates knowledge distillation-without requiring additional data-thus preventing forced alignment of novel objects with background.Additionally, we introduce R-RPN, which adjusts the confidence scores of proposals during inference to improve the recall of novel-category objects. Cross-dataset evaluations on OV-LVIS, OV-COCO, and Objects365 demonstrate that our approach consistently achieves superior performance across multiple metrics.
CFCML: A Coarse-to-Fine Crossmodal Learning Framework For Disease Diagnosis Using Multimodal Images and Tabular Data
Mar 20, 2026In clinical practice, crossmodal information including medical images and tabular data is essential for disease diagnosis. There exists a significant modality gap between these data types, which obstructs advancements in crossmodal diagnostic accuracy. Most existing crossmodal learning (CML) methods primarily focus on exploring relationships among high-level encoder outputs, leading to the neglect of local information in images. Additionally, these methods often overlook the extraction of task-relevant information. In this paper, we propose a novel coarse-to-fine crossmodal learning (CFCML) framework to progressively reduce the modality gap between multimodal images and tabular data, by thoroughly exploring inter-modal relationships. At the coarse stage, we explore the relationships between multi-granularity features from various image encoder stages and tabular information, facilitating a preliminary reduction of the modality gap. At the fine stage, we generate unimodal and crossmodal prototypes that incorporate class-aware information, and establish hierarchical anchor-based relationship mining (HRM) strategy to further diminish the modality gap and extract discriminative crossmodal information. This strategy utilize modality samples, unimodal prototypes, and crossmodal prototypes as anchors to develop contrastive learning approaches, effectively enhancing inter-class disparity while reducing intra-class disparity from multiple perspectives. Experimental results indicate that our method outperforms the state-of-the-art (SOTA) methods, achieving improvements of 1.53% and 0.91% in AUC metrics on the MEN and Derm7pt datasets, respectively. The code is available at https://github.com/IsDling/CFCML.
NUC-Net: Non-uniform Cylindrical Partition Network for Efficient LiDAR Semantic Segmentation
May 30, 2025LiDAR semantic segmentation plays a vital role in autonomous driving. Existing voxel-based methods for LiDAR semantic segmentation apply uniform partition to the 3D LiDAR point cloud to form a structured representation based on cartesian/cylindrical coordinates. Although these methods show impressive performance, the drawback of existing voxel-based methods remains in two aspects: (1) it requires a large enough input voxel resolution, which brings a large amount of computation cost and memory consumption. (2) it does not well handle the unbalanced point distribution of LiDAR point cloud. In this paper, we propose a non-uniform cylindrical partition network named NUC-Net to tackle the above challenges. Specifically, we propose the Arithmetic Progression of Interval (API) method to non-uniformly partition the radial axis and generate the voxel representation which is representative and efficient. Moreover, we propose a non-uniform multi-scale aggregation method to improve contextual information. Our method achieves state-of-the-art performance on SemanticKITTI and nuScenes datasets with much faster speed and much less training time. And our method can be a general component for LiDAR semantic segmentation, which significantly improves both the accuracy and efficiency of the uniform counterpart by $4 \times$ training faster and $2 \times$ GPU memory reduction and $3 \times$ inference speedup. We further provide theoretical analysis towards understanding why NUC is effective and how point distribution affects performance. Code is available at \href{https://github.com/alanWXZ/NUC-Net}{https://github.com/alanWXZ/NUC-Net}.
On Path to Multimodal Historical Reasoning: HistBench and HistAgent
May 26, 2025Recent advances in large language models (LLMs) have led to remarkable progress across domains, yet their capabilities in the humanities, particularly history, remain underexplored. Historical reasoning poses unique challenges for AI, involving multimodal source interpretation, temporal inference, and cross-linguistic analysis. While general-purpose agents perform well on many existing benchmarks, they lack the domain-specific expertise required to engage with historical materials and questions. To address this gap, we introduce HistBench, a new benchmark of 414 high-quality questions designed to evaluate AI's capacity for historical reasoning and authored by more than 40 expert contributors. The tasks span a wide range of historical problems-from factual retrieval based on primary sources to interpretive analysis of manuscripts and images, to interdisciplinary challenges involving archaeology, linguistics, or cultural history. Furthermore, the benchmark dataset spans 29 ancient and modern languages and covers a wide range of historical periods and world regions. Finding the poor performance of LLMs and other agents on HistBench, we further present HistAgent, a history-specific agent equipped with carefully designed tools for OCR, translation, archival search, and image understanding in History. On HistBench, HistAgent based on GPT-4o achieves an accuracy of 27.54% pass@1 and 36.47% pass@2, significantly outperforming LLMs with online search and generalist agents, including GPT-4o (18.60%), DeepSeek-R1(14.49%) and Open Deep Research-smolagents(20.29% pass@1 and 25.12% pass@2). These results highlight the limitations of existing LLMs and generalist agents and demonstrate the advantages of HistAgent for historical reasoning.
Beyond Background Shift: Rethinking Instance Replay in Continual Semantic Segmentation
Mar 28, 2025



In this work, we focus on continual semantic segmentation (CSS), where segmentation networks are required to continuously learn new classes without erasing knowledge of previously learned ones. Although storing images of old classes and directly incorporating them into the training of new models has proven effective in mitigating catastrophic forgetting in classification tasks, this strategy presents notable limitations in CSS. Specifically, the stored and new images with partial category annotations leads to confusion between unannotated categories and the background, complicating model fitting. To tackle this issue, this paper proposes a novel Enhanced Instance Replay (EIR) method, which not only preserves knowledge of old classes while simultaneously eliminating background confusion by instance storage of old classes, but also mitigates background shifts in the new images by integrating stored instances with new images. By effectively resolving background shifts in both stored and new images, EIR alleviates catastrophic forgetting in the CSS task, thereby enhancing the model's capacity for CSS. Experimental results validate the efficacy of our approach, which significantly outperforms state-of-the-art CSS methods.
Casual Inference via Style Bias Deconfounding for Domain Generalization
Mar 21, 2025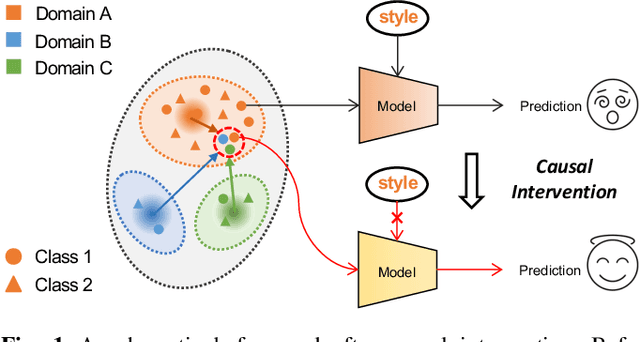
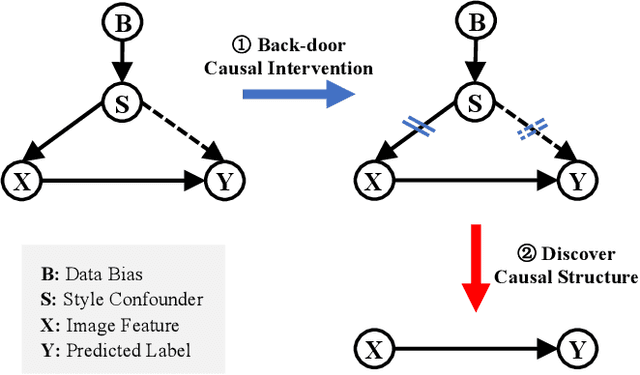
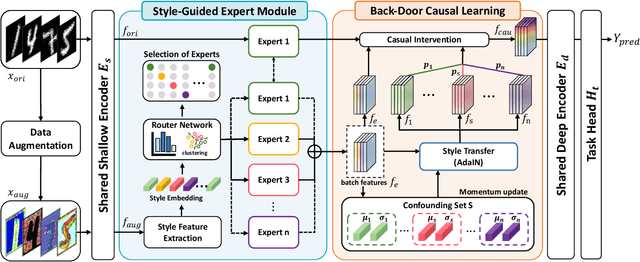
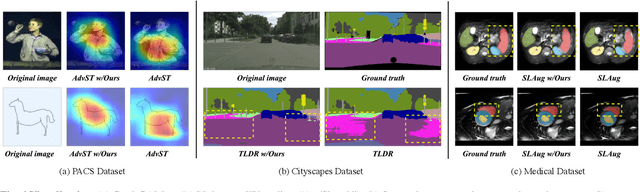
Deep neural networks (DNNs) often struggle with out-of-distribution data, limiting their reliability in diverse realworld applications. To address this issue, domain generalization methods have been developed to learn domain-invariant features from single or multiple training domains, enabling generalization to unseen testing domains. However, existing approaches usually overlook the impact of style frequency within the training set. This oversight predisposes models to capture spurious visual correlations caused by style confounding factors, rather than learning truly causal representations, thereby undermining inference reliability. In this work, we introduce Style Deconfounding Causal Learning (SDCL), a novel causal inference-based framework designed to explicitly address style as a confounding factor. Our approaches begins with constructing a structural causal model (SCM) tailored to the domain generalization problem and applies a backdoor adjustment strategy to account for style influence. Building on this foundation, we design a style-guided expert module (SGEM) to adaptively clusters style distributions during training, capturing the global confounding style. Additionally, a back-door causal learning module (BDCL) performs causal interventions during feature extraction, ensuring fair integration of global confounding styles into sample predictions, effectively reducing style bias. The SDCL framework is highly versatile and can be seamlessly integrated with state-of-the-art data augmentation techniques. Extensive experiments across diverse natural and medical image recognition tasks validate its efficacy, demonstrating superior performance in both multi-domain and the more challenging single-domain generalization scenarios.
iLLaVA: An Image is Worth Fewer Than 1/3 Input Tokens in Large Multimodal Models
Dec 09, 2024



In this paper, we introduce iLLaVA, a simple method that can be seamlessly deployed upon current Large Vision-Language Models (LVLMs) to greatly increase the throughput with nearly lossless model performance, without a further requirement to train. iLLaVA achieves this by finding and gradually merging the redundant tokens with an accurate and fast algorithm, which can merge hundreds of tokens within only one step. While some previous methods have explored directly pruning or merging tokens in the inference stage to accelerate models, our method excels in both performance and throughput by two key designs. First, while most previous methods only try to save the computations of Large Language Models (LLMs), our method accelerates the forward pass of both image encoders and LLMs in LVLMs, which both occupy a significant part of time during inference. Second, our method recycles the beneficial information from the pruned tokens into existing tokens, which avoids directly dropping context tokens like previous methods to cause performance loss. iLLaVA can nearly 2$\times$ the throughput, and reduce the memory costs by half with only a 0.2\% - 0.5\% performance drop across models of different scales including 7B, 13B and 34B. On tasks across different domains including single-image, multi-images and videos, iLLaVA demonstrates strong generalizability with consistently promising efficiency. We finally offer abundant visualizations to show the merging processes of iLLaVA in each step, which show insights into the distribution of computing resources in LVLMs. Code is available at https://github.com/hulianyuyy/iLLaVA.
Deep Correlated Prompting for Visual Recognition with Missing Modalities
Oct 10, 2024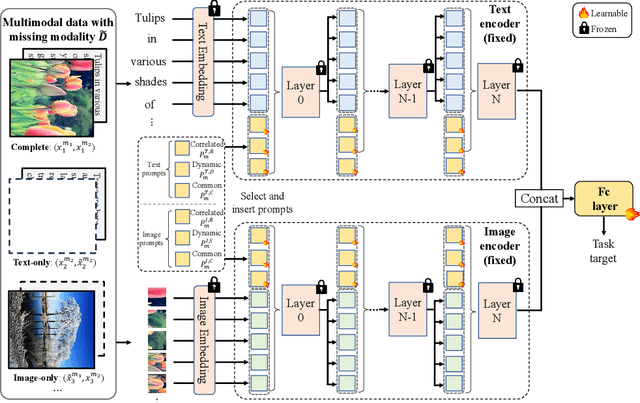
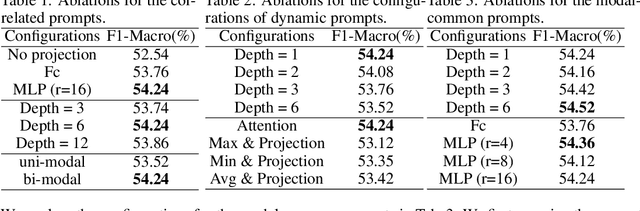
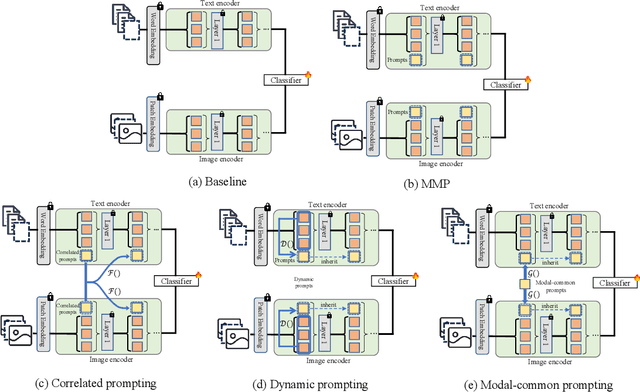
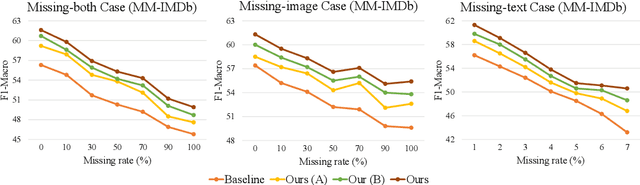
Large-scale multimodal models have shown excellent performance over a series of tasks powered by the large corpus of paired multimodal training data. Generally, they are always assumed to receive modality-complete inputs. However, this simple assumption may not always hold in the real world due to privacy constraints or collection difficulty, where models pretrained on modality-complete data easily demonstrate degraded performance on missing-modality cases. To handle this issue, we refer to prompt learning to adapt large pretrained multimodal models to handle missing-modality scenarios by regarding different missing cases as different types of input. Instead of only prepending independent prompts to the intermediate layers, we present to leverage the correlations between prompts and input features and excavate the relationships between different layers of prompts to carefully design the instructions. We also incorporate the complementary semantics of different modalities to guide the prompting design for each modality. Extensive experiments on three commonly-used datasets consistently demonstrate the superiority of our method compared to the previous approaches upon different missing scenarios. Plentiful ablations are further given to show the generalizability and reliability of our method upon different modality-missing ratios and types.
Completed Feature Disentanglement Learning for Multimodal MRIs Analysis
Jul 06, 2024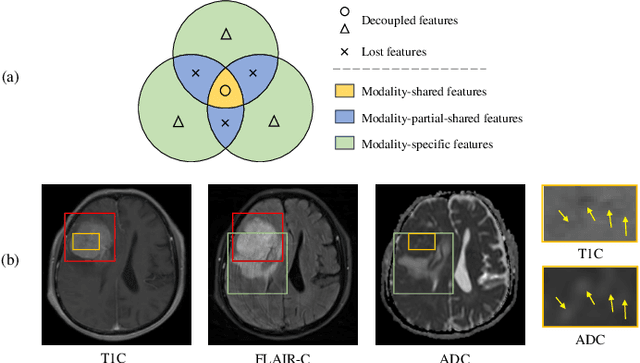
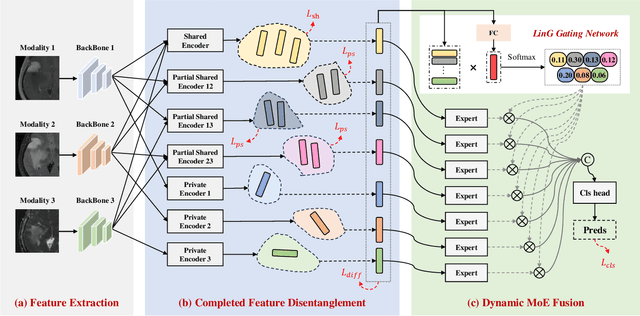
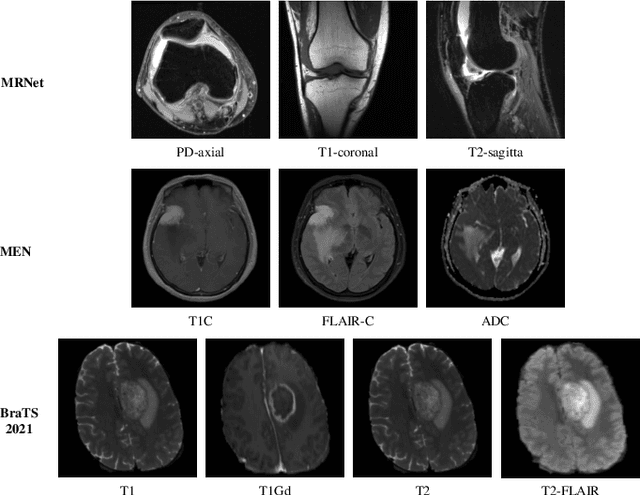
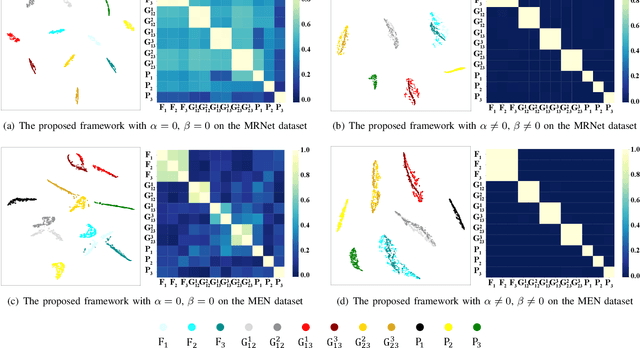
Multimodal MRIs play a crucial role in clinical diagnosis and treatment. Feature disentanglement (FD)-based methods, aiming at learning superior feature representations for multimodal data analysis, have achieved significant success in multimodal learning (MML). Typically, existing FD-based methods separate multimodal data into modality-shared and modality-specific features, and employ concatenation or attention mechanisms to integrate these features. However, our preliminary experiments indicate that these methods could lead to a loss of shared information among subsets of modalities when the inputs contain more than two modalities, and such information is critical for prediction accuracy. Furthermore, these methods do not adequately interpret the relationships between the decoupled features at the fusion stage. To address these limitations, we propose a novel Complete Feature Disentanglement (CFD) strategy that recovers the lost information during feature decoupling. Specifically, the CFD strategy not only identifies modality-shared and modality-specific features, but also decouples shared features among subsets of multimodal inputs, termed as modality-partial-shared features. We further introduce a new Dynamic Mixture-of-Experts Fusion (DMF) module that dynamically integrates these decoupled features, by explicitly learning the local-global relationships among the features. The effectiveness of our approach is validated through classification tasks on three multimodal MRI datasets. Extensive experimental results demonstrate that our approach outperforms other state-of-the-art MML methods with obvious margins, showcasing its superior performance.
Topicwise Separable Sentence Retrieval for Medical Report Generation
May 07, 2024



Automated radiology reporting holds immense clinical potential in alleviating the burdensome workload of radiologists and mitigating diagnostic bias. Recently, retrieval-based report generation methods have garnered increasing attention due to their inherent advantages in terms of the quality and consistency of generated reports. However, due to the long-tail distribution of the training data, these models tend to learn frequently occurring sentences and topics, overlooking the rare topics. Regrettably, in many cases, the descriptions of rare topics often indicate critical findings that should be mentioned in the report. To address this problem, we introduce a Topicwise Separable Sentence Retrieval (Teaser) for medical report generation. To ensure comprehensive learning of both common and rare topics, we categorize queries into common and rare types to learn differentiated topics, and then propose Topic Contrastive Loss to effectively align topics and queries in the latent space. Moreover, we integrate an Abstractor module following the extraction of visual features, which aids the topic decoder in gaining a deeper understanding of the visual observational intent. Experiments on the MIMIC-CXR and IU X-ray datasets demonstrate that Teaser surpasses state-of-the-art models, while also validating its capability to effectively represent rare topics and establish more dependable correspondences between queries and topics.