 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIViT: A Novel Interpretable Visual Transformer for Skin Disease Detection
Jun 22, 2026The clinical diagnosis of skin diseases is susceptible to interference from inter-class similarity of skin lesions, and over-reliance on clinicians'experience easily leads to subjective bias. Although existing deep learning aided diagnosis methods achieve competitive accuracy, they suffer from the black-box opacity of Vision Transformer (ViT) and poor adaptability to medical few-shot scenarios. Moreover, mainstream explainable algorithms generally face the bottleneck of significant accuracy degradation when improving interpretability. This paper proposes an interpretable ViT (IViT) constrained by Quadratic Programming (QP). The introduced pre-trained transfer learning adapts to few-shot feature extraction. A discrete QP feature selection framework is constructed to screen generic and discriminative features consistent with clinical diagnostic logic. A multi-objective loss function is designed to reduce feature redundancy and optimize activation distribution while preserving classification performance. Experimental results on six standard skin disease datasets show that IViT achieves an accuracy of 93.80%, only 0.21% lower than the baseline, with feature redundancy reduced by 29.5%. Its core activation regions are consistent with clinically concerned lesion areas. The proposed model balances accuracy and interpretability, providing a reliable solution for the clinical deployment of few-shot intelligent skin disease diagnosis.
Explanation-Guided Medical Named Entity Recognition with Stability and Boundary Awareness for Atopic Dermatitis
Jun 22, 2026Objective: This study aims to improve the reliability and robustness of medical named entity recognition (NER) in Chinese atopic dermatitis (AD) clinical texts through explanation-guided learning. Methods: We propose a stability and boundary-aware explanation-guided NER framework. Perturbation-based analysis is used to evaluate explanation stability and entity boundary sensitivity. An adaptive fusion strategy dynamically combines local and global explanation to generate more reliable token-level explanations. The fused explanation signals are further incorporated into model training through stability, boundary-aware, and consistency constraints. Results: Experiments on Chinese AD NER datasets show that the proposed framework improves explanation robustness and achieves consistent performance gains across multiple NER models. The adaptive fusion strategy also provides more stable explanations and stronger boundary perception than individual explanation methods. Conclusion: The proposed method effectively integrates reliable explanation signals into medical NER training, improving both recognition performance and explanation reliability. The framework provides a practical and generalizable solution for explainable medical NER and offers reliable support for downstream clinical decision-making and medical knowledge applications.
AdaCultureSafe: Adaptive Cultural Safety Grounded by Cultural Knowledge in Large Language Models
Mar 09, 2026With the widespread adoption of Large Language Models (LLMs), respecting indigenous cultures becomes essential for models' culturally safety and responsible global applications. Existing studies separately consider cultural safety and cultural knowledge and neglect that the former should be grounded by the latter. This severely prevents LLMs from yielding culture-specific respectful responses. Consequently, adaptive cultural safety remains a formidable task. In this work, we propose to jointly model cultural safety and knowledge. First and foremost, cultural-safety and knowledge-paired data serve as the key prerequisite to conduct this research. However, the cultural diversity across regions and the subtlety of cultural differences pose significant challenges to the creation of such paired evaluation data. To address this issue, we propose a novel framework that integrates authoritative cultural knowledge descriptions curation, LLM-automated query generation, and heavy manual verification. Accordingly, we obtain a dataset named AdaCultureSafe containing 4.8K manually decomposed fine-grained cultural descriptions and the corresponding 48K manually verified safety- and knowledge-oriented queries. Upon the constructed dataset, we evaluate three families of popular LLMs on their cultural safety and knowledge proficiency, via which we make a critical discovery: no significant correlation exists between their cultural safety and knowledge proficiency. We then delve into the utility-related neuron activations within LLMs to investigate the potential cause of the absence of correlation, which can be attributed to the difference of the objectives of pre-training and post-alignment. We finally present a knowledge-grounded method, which significantly enhances cultural safety by enforcing the integration of knowledge into the LLM response generation process.
DrivePI: Spatial-aware 4D MLLM for Unified Autonomous Driving Understanding, Perception, Prediction and Planning
Dec 14, 2025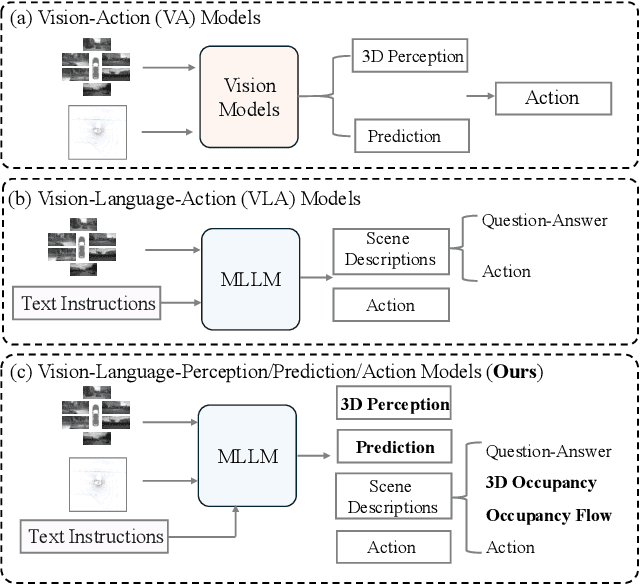
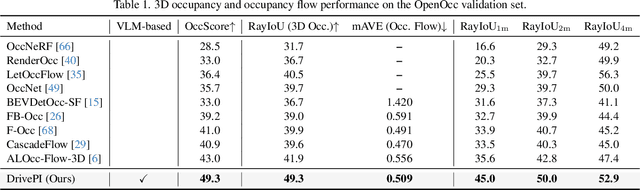
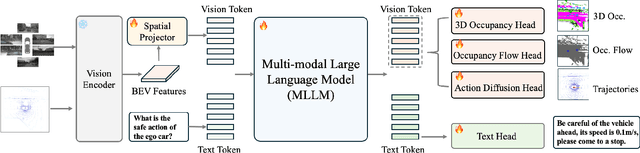
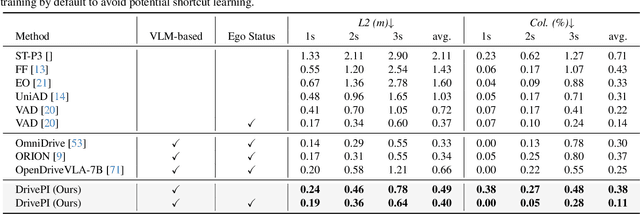
Although multi-modal large language models (MLLMs) have shown strong capabilities across diverse domains, their application in generating fine-grained 3D perception and prediction outputs in autonomous driving remains underexplored. In this paper, we propose DrivePI, a novel spatial-aware 4D MLLM that serves as a unified Vision-Language-Action (VLA) framework that is also compatible with vision-action (VA) models. Our method jointly performs spatial understanding, 3D perception (i.e., 3D occupancy), prediction (i.e., occupancy flow), and planning (i.e., action outputs) in parallel through end-to-end optimization. To obtain both precise geometric information and rich visual appearance, our approach integrates point clouds, multi-view images, and language instructions within a unified MLLM architecture. We further develop a data engine to generate text-occupancy and text-flow QA pairs for 4D spatial understanding. Remarkably, with only a 0.5B Qwen2.5 model as MLLM backbone, DrivePI as a single unified model matches or exceeds both existing VLA models and specialized VA models. Specifically, compared to VLA models, DrivePI outperforms OpenDriveVLA-7B by 2.5% mean accuracy on nuScenes-QA and reduces collision rate by 70% over ORION (from 0.37% to 0.11%) on nuScenes. Against specialized VA models, DrivePI surpasses FB-OCC by 10.3 RayIoU for 3D occupancy on OpenOcc, reduces the mAVE from 0.591 to 0.509 for occupancy flow on OpenOcc, and achieves 32% lower L2 error than VAD (from 0.72m to 0.49m) for planning on nuScenes. Code will be available at https://github.com/happinesslz/DrivePI
CorrectAD: A Self-Correcting Agentic System to Improve End-to-end Planning in Autonomous Driving
Nov 17, 2025End-to-end planning methods are the de facto standard of the current autonomous driving system, while the robustness of the data-driven approaches suffers due to the notorious long-tail problem (i.e., rare but safety-critical failure cases). In this work, we explore whether recent diffusion-based video generation methods (a.k.a. world models), paired with structured 3D layouts, can enable a fully automated pipeline to self-correct such failure cases. We first introduce an agent to simulate the role of product manager, dubbed PM-Agent, which formulates data requirements to collect data similar to the failure cases. Then, we use a generative model that can simulate both data collection and annotation. However, existing generative models struggle to generate high-fidelity data conditioned on 3D layouts. To address this, we propose DriveSora, which can generate spatiotemporally consistent videos aligned with the 3D annotations requested by PM-Agent. We integrate these components into our self-correcting agentic system, CorrectAD. Importantly, our pipeline is an end-to-end model-agnostic and can be applied to improve any end-to-end planner. Evaluated on both nuScenes and a more challenging in-house dataset across multiple end-to-end planners, CorrectAD corrects 62.5% and 49.8% of failure cases, reducing collision rates by 39% and 27%, respectively.
Zero-Shot Learning with Subsequence Reordering Pretraining for Compound-Protein Interaction
Jul 28, 2025Given the vastness of chemical space and the ongoing emergence of previously uncharacterized proteins, zero-shot compound-protein interaction (CPI) prediction better reflects the practical challenges and requirements of real-world drug development. Although existing methods perform adequately during certain CPI tasks, they still face the following challenges: (1) Representation learning from local or complete protein sequences often overlooks the complex interdependencies between subsequences, which are essential for predicting spatial structures and binding properties. (2) Dependence on large-scale or scarce multimodal protein datasets demands significant training data and computational resources, limiting scalability and efficiency. To address these challenges, we propose a novel approach that pretrains protein representations for CPI prediction tasks using subsequence reordering, explicitly capturing the dependencies between protein subsequences. Furthermore, we apply length-variable protein augmentation to ensure excellent pretraining performance on small training datasets. To evaluate the model's effectiveness and zero-shot learning ability, we combine it with various baseline methods. The results demonstrate that our approach can improve the baseline model's performance on the CPI task, especially in the challenging zero-shot scenario. Compared to existing pre-training models, our model demonstrates superior performance, particularly in data-scarce scenarios where training samples are limited. Our implementation is available at https://github.com/Hoch-Zhang/PSRP-CPI.
IMPA-HGAE:Intra-Meta-Path Augmented Heterogeneous Graph Autoencoder
Jun 07, 2025



Self-supervised learning (SSL) methods have been increasingly applied to diverse downstream tasks due to their superior generalization capabilities and low annotation costs. However, most existing heterogeneous graph SSL models convert heterogeneous graphs into homogeneous ones via meta-paths for training, which only leverage information from nodes at both ends of meta-paths while underutilizing the heterogeneous node information along the meta-paths. To address this limitation, this paper proposes a novel framework named IMPA-HGAE to enhance target node embeddings by fully exploiting internal node information along meta-paths. Experimental results validate that IMPA-HGAE achieves superior performance on heterogeneous datasets. Furthermore, this paper introduce innovative masking strategies to strengthen the representational capacity of generative SSL models on heterogeneous graph data. Additionally, this paper discuss the interpretability of the proposed method and potential future directions for generative self-supervised learning in heterogeneous graphs. This work provides insights into leveraging meta-path-guided structural semantics for robust representation learning in complex graph scenarios.
Learning Robust Heterogeneous Graph Representations via Contrastive-Reconstruction under Sparse Semantics
Jun 07, 2025



In graph self-supervised learning, masked autoencoders (MAE) and contrastive learning (CL) are two prominent paradigms. MAE focuses on reconstructing masked elements, while CL maximizes similarity between augmented graph views. Recent studies highlight their complementarity: MAE excels at local feature capture, and CL at global information extraction. Hybrid frameworks for homogeneous graphs have been proposed, but face challenges in designing shared encoders to meet the semantic requirements of both tasks. In semantically sparse scenarios, CL struggles with view construction, and gradient imbalance between positive and negative samples persists. This paper introduces HetCRF, a novel dual-channel self-supervised learning framework for heterogeneous graphs. HetCRF uses a two-stage aggregation strategy to adapt embedding semantics, making it compatible with both MAE and CL. To address semantic sparsity, it enhances encoder output for view construction instead of relying on raw features, improving efficiency. Two positive sample augmentation strategies are also proposed to balance gradient contributions. Node classification experiments on four real-world heterogeneous graph datasets demonstrate that HetCRF outperforms state-of-the-art baselines. On datasets with missing node features, such as Aminer and Freebase, at a 40% label rate in node classification, HetCRF improves the Macro-F1 score by 2.75% and 2.2% respectively compared to the second-best baseline, validating its effectiveness and superiority.
Light as Deception: GPT-driven Natural Relighting Against Vision-Language Pre-training Models
May 30, 2025While adversarial attacks on vision-and-language pretraining (VLP) models have been explored, generating natural adversarial samples crafted through realistic and semantically meaningful perturbations remains an open challenge. Existing methods, primarily designed for classification tasks, struggle when adapted to VLP models due to their restricted optimization spaces, leading to ineffective attacks or unnatural artifacts. To address this, we propose \textbf{LightD}, a novel framework that generates natural adversarial samples for VLP models via semantically guided relighting. Specifically, LightD leverages ChatGPT to propose context-aware initial lighting parameters and integrates a pretrained relighting model (IC-light) to enable diverse lighting adjustments. LightD expands the optimization space while ensuring perturbations align with scene semantics. Additionally, gradient-based optimization is applied to the reference lighting image to further enhance attack effectiveness while maintaining visual naturalness. The effectiveness and superiority of the proposed LightD have been demonstrated across various VLP models in tasks such as image captioning and visual question answering.
NoiseController: Towards Consistent Multi-view Video Generation via Noise Decomposition and Collaboration
Apr 25, 2025High-quality video generation is crucial for many fields, including the film industry and autonomous driving. However, generating videos with spatiotemporal consistencies remains challenging. Current methods typically utilize attention mechanisms or modify noise to achieve consistent videos, neglecting global spatiotemporal information that could help ensure spatial and temporal consistency during video generation. In this paper, we propose the NoiseController, consisting of Multi-Level Noise Decomposition, Multi-Frame Noise Collaboration, and Joint Denoising, to enhance spatiotemporal consistencies in video generation. In multi-level noise decomposition, we first decompose initial noises into scene-level foreground/background noises, capturing distinct motion properties to model multi-view foreground/background variations. Furthermore, each scene-level noise is further decomposed into individual-level shared and residual components. The shared noise preserves consistency, while the residual component maintains diversity. In multi-frame noise collaboration, we introduce an inter-view spatiotemporal collaboration matrix and an intra-view impact collaboration matrix , which captures mutual cross-view effects and historical cross-frame impacts to enhance video quality. The joint denoising contains two parallel denoising U-Nets to remove each scene-level noise, mutually enhancing video generation. We evaluate our NoiseController on public datasets focusing on video generation and downstream tasks, demonstrating its state-of-the-art performance.