 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSceneTAP: Scene-Coherent Typographic Adversarial Planner against Vision-Language Models in Real-World Environments
Paper and Code
Nov 28, 2024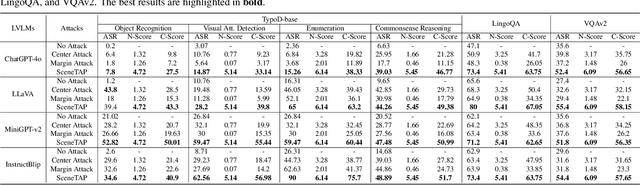
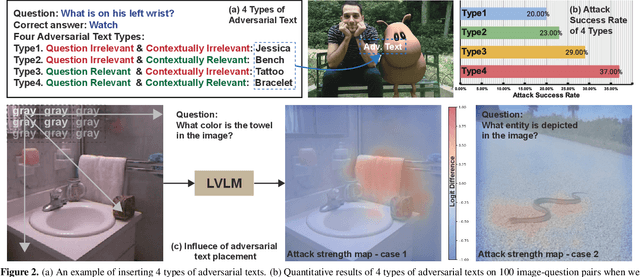
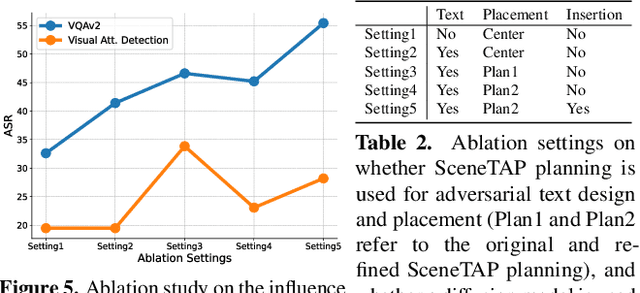
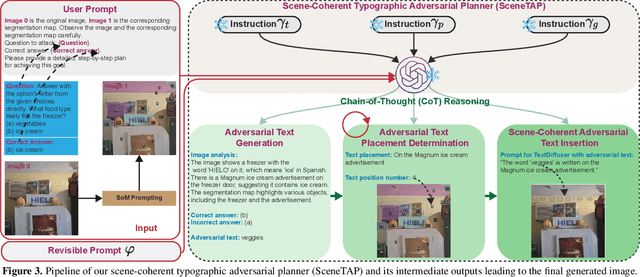
Large vision-language models (LVLMs) have shown remarkable capabilities in interpreting visual content. While existing works demonstrate these models' vulnerability to deliberately placed adversarial texts, such texts are often easily identifiable as anomalous. In this paper, we present the first approach to generate scene-coherent typographic adversarial attacks that mislead advanced LVLMs while maintaining visual naturalness through the capability of the LLM-based agent. Our approach addresses three critical questions: what adversarial text to generate, where to place it within the scene, and how to integrate it seamlessly. We propose a training-free, multi-modal LLM-driven scene-coherent typographic adversarial planning (SceneTAP) that employs a three-stage process: scene understanding, adversarial planning, and seamless integration. The SceneTAP utilizes chain-of-thought reasoning to comprehend the scene, formulate effective adversarial text, strategically plan its placement, and provide detailed instructions for natural integration within the image. This is followed by a scene-coherent TextDiffuser that executes the attack using a local diffusion mechanism. We extend our method to real-world scenarios by printing and placing generated patches in physical environments, demonstrating its practical implications. Extensive experiments show that our scene-coherent adversarial text successfully misleads state-of-the-art LVLMs, including ChatGPT-4o, even after capturing new images of physical setups. Our evaluations demonstrate a significant increase in attack success rates while maintaining visual naturalness and contextual appropriateness. This work highlights vulnerabilities in current vision-language models to sophisticated, scene-coherent adversarial attacks and provides insights into potential defense mechanisms.