 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoosting SAM for Cross-Domain Few-Shot Segmentation via Conditional Point Sparsification
Feb 05, 2026Motivated by the success of the Segment Anything Model (SAM) in promptable segmentation, recent studies leverage SAM to develop training-free solutions for few-shot segmentation, which aims to predict object masks in the target image based on a few reference exemplars. These SAM-based methods typically rely on point matching between reference and target images and use the matched dense points as prompts for mask prediction. However, we observe that dense points perform poorly in Cross-Domain Few-Shot Segmentation (CD-FSS), where target images are from medical or satellite domains. We attribute this issue to large domain shifts that disrupt the point-image interactions learned by SAM, and find that point density plays a crucial role under such conditions. To address this challenge, we propose Conditional Point Sparsification (CPS), a training-free approach that adaptively guides SAM interactions for cross-domain images based on reference exemplars. Leveraging ground-truth masks, the reference images provide reliable guidance for adaptively sparsifying dense matched points, enabling more accurate segmentation results. Extensive experiments demonstrate that CPS outperforms existing training-free SAM-based methods across diverse CD-FSS datasets.
FOCUS: Frequency-Optimized Conditioning of DiffUSion Models for mitigating catastrophic forgetting during Test-Time Adaptation
Aug 20, 2025Test-time adaptation enables models to adapt to evolving domains. However, balancing the tradeoff between preserving knowledge and adapting to domain shifts remains challenging for model adaptation methods, since adapting to domain shifts can induce forgetting of task-relevant knowledge. To address this problem, we propose FOCUS, a novel frequency-based conditioning approach within a diffusion-driven input-adaptation framework. Utilising learned, spatially adaptive frequency priors, our approach conditions the reverse steps during diffusion-driven denoising to preserve task-relevant semantic information for dense prediction. FOCUS leverages a trained, lightweight, Y-shaped Frequency Prediction Network (Y-FPN) that disentangles high and low frequency information from noisy images. This minimizes the computational costs involved in implementing our approach in a diffusion-driven framework. We train Y-FPN with FrequencyMix, a novel data augmentation method that perturbs the images across diverse frequency bands, which improves the robustness of our approach to diverse corruptions. We demonstrate the effectiveness of FOCUS for semantic segmentation and monocular depth estimation across 15 corruption types and three datasets, achieving state-of-the-art averaged performance. In addition to improving standalone performance, FOCUS complements existing model adaptation methods since we can derive pseudo labels from FOCUS-denoised images for additional supervision. Even under limited, intermittent supervision with the pseudo labels derived from the FOCUS denoised images, we show that FOCUS mitigates catastrophic forgetting for recent model adaptation methods.
MMLU-ProX: A Multilingual Benchmark for Advanced Large Language Model Evaluation
Mar 13, 2025

Traditional benchmarks struggle to evaluate increasingly sophisticated language models in multilingual and culturally diverse contexts. To address this gap, we introduce MMLU-ProX, a comprehensive multilingual benchmark covering 13 typologically diverse languages with approximately 11,829 questions per language. Building on the challenging reasoning-focused design of MMLU-Pro, our framework employs a semi-automatic translation process: translations generated by state-of-the-art large language models (LLMs) are rigorously evaluated by expert annotators to ensure conceptual accuracy, terminological consistency, and cultural relevance. We comprehensively evaluate 25 state-of-the-art LLMs using 5-shot chain-of-thought (CoT) and zero-shot prompting strategies, analyzing their performance across linguistic and cultural boundaries. Our experiments reveal consistent performance degradation from high-resource languages to lower-resource ones, with the best models achieving over 70% accuracy on English but dropping to around 40% for languages like Swahili, highlighting persistent gaps in multilingual capabilities despite recent advances. MMLU-ProX is an ongoing project; we are expanding our benchmark by incorporating additional languages and evaluating more language models to provide a more comprehensive assessment of multilingual capabilities.
MAGIC: Mastering Physical Adversarial Generation in Context through Collaborative LLM Agents
Dec 11, 2024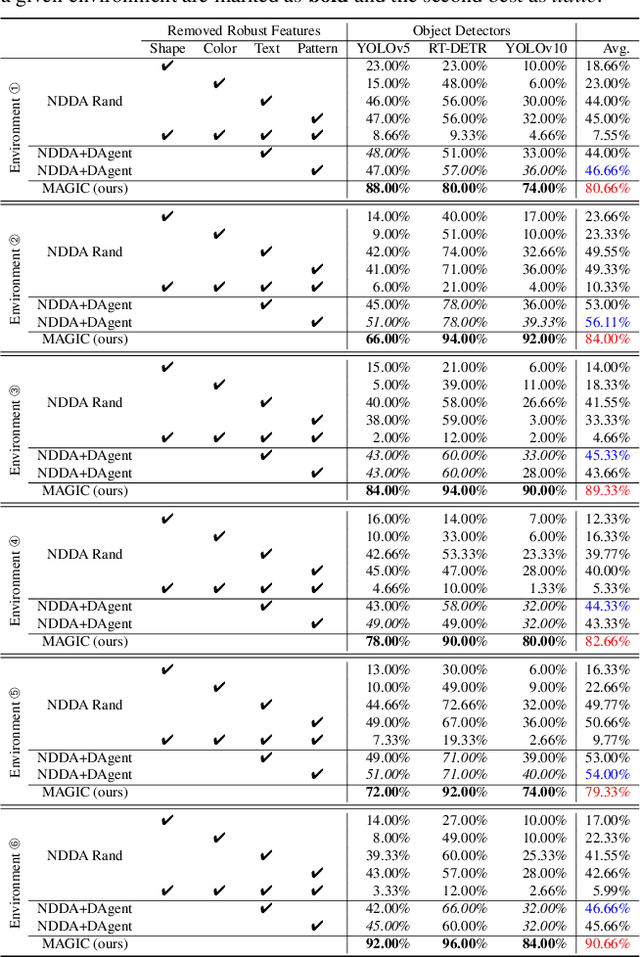
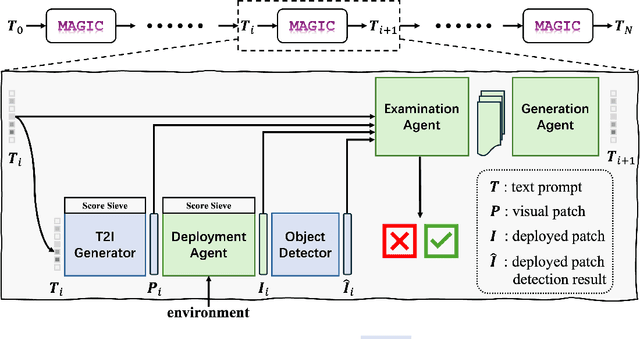
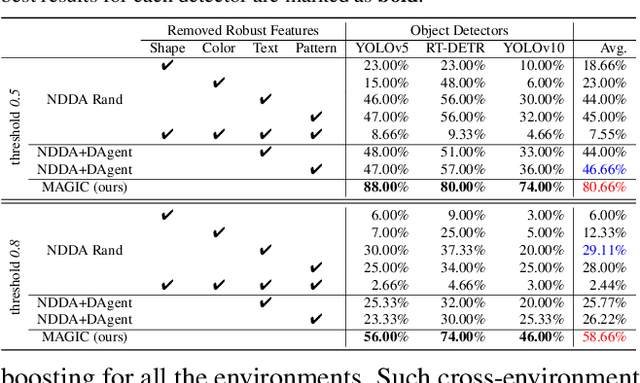

Physical adversarial attacks in driving scenarios can expose critical vulnerabilities in visual perception models. However, developing such attacks remains challenging due to diverse real-world backgrounds and the requirement for maintaining visual naturality. Building upon this challenge, we reformulate physical adversarial attacks as a one-shot patch-generation problem. Our approach generates adversarial patches through a deep generative model that considers the specific scene context, enabling direct physical deployment in matching environments. The primary challenge lies in simultaneously achieving two objectives: generating adversarial patches that effectively mislead object detection systems while determining contextually appropriate placement within the scene. We propose MAGIC (Mastering Physical Adversarial Generation In Context), a novel framework powered by multi-modal LLM agents to address these challenges. MAGIC automatically understands scene context and orchestrates adversarial patch generation through the synergistic interaction of language and vision capabilities. MAGIC orchestrates three specialized LLM agents: The adv-patch generation agent (GAgent) masters the creation of deceptive patches through strategic prompt engineering for text-to-image models. The adv-patch deployment agent (DAgent) ensures contextual coherence by determining optimal placement strategies based on scene understanding. The self-examination agent (EAgent) completes this trilogy by providing critical oversight and iterative refinement of both processes. We validate our method on both digital and physical level, \ie, nuImage and manually captured real scenes, where both statistical and visual results prove that our MAGIC is powerful and effectively for attacking wide-used object detection systems.
SceneTAP: Scene-Coherent Typographic Adversarial Planner against Vision-Language Models in Real-World Environments
Nov 28, 2024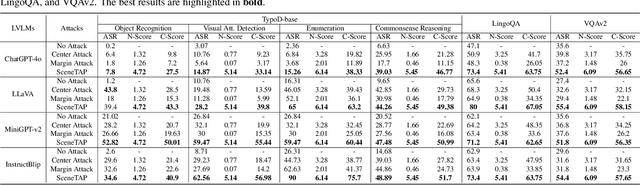
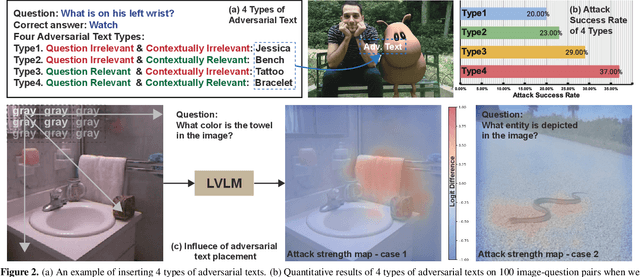
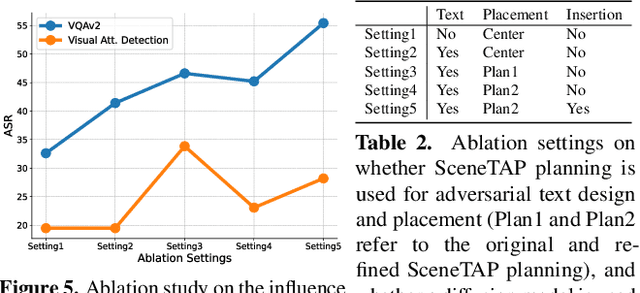
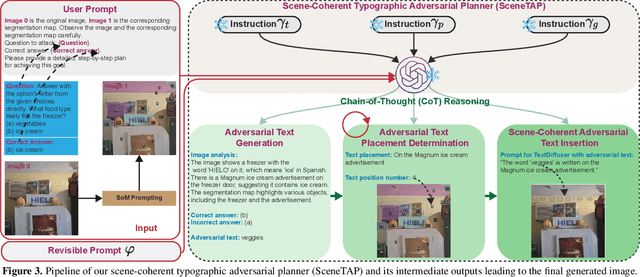
Large vision-language models (LVLMs) have shown remarkable capabilities in interpreting visual content. While existing works demonstrate these models' vulnerability to deliberately placed adversarial texts, such texts are often easily identifiable as anomalous. In this paper, we present the first approach to generate scene-coherent typographic adversarial attacks that mislead advanced LVLMs while maintaining visual naturalness through the capability of the LLM-based agent. Our approach addresses three critical questions: what adversarial text to generate, where to place it within the scene, and how to integrate it seamlessly. We propose a training-free, multi-modal LLM-driven scene-coherent typographic adversarial planning (SceneTAP) that employs a three-stage process: scene understanding, adversarial planning, and seamless integration. The SceneTAP utilizes chain-of-thought reasoning to comprehend the scene, formulate effective adversarial text, strategically plan its placement, and provide detailed instructions for natural integration within the image. This is followed by a scene-coherent TextDiffuser that executes the attack using a local diffusion mechanism. We extend our method to real-world scenarios by printing and placing generated patches in physical environments, demonstrating its practical implications. Extensive experiments show that our scene-coherent adversarial text successfully misleads state-of-the-art LVLMs, including ChatGPT-4o, even after capturing new images of physical setups. Our evaluations demonstrate a significant increase in attack success rates while maintaining visual naturalness and contextual appropriateness. This work highlights vulnerabilities in current vision-language models to sophisticated, scene-coherent adversarial attacks and provides insights into potential defense mechanisms.
Mitigating Object Hallucination via Concentric Causal Attention
Oct 21, 2024Recent Large Vision Language Models (LVLMs) present remarkable zero-shot conversational and reasoning capabilities given multimodal queries. Nevertheless, they suffer from object hallucination, a phenomenon where LVLMs are prone to generate textual responses not factually aligned with image inputs. Our pilot study reveals that object hallucination is closely tied with Rotary Position Encoding (RoPE), a widely adopted positional dependency modeling design in existing LVLMs. Due to the long-term decay in RoPE, LVLMs tend to hallucinate more when relevant visual cues are distant from instruction tokens in the multimodal input sequence. Additionally, we observe a similar effect when reversing the sequential order of visual tokens during multimodal alignment. Our tests indicate that long-term decay in RoPE poses challenges to LVLMs while capturing visual-instruction interactions across long distances. We propose Concentric Causal Attention (CCA), a simple yet effective positional alignment strategy that mitigates the impact of RoPE long-term decay in LVLMs by naturally reducing relative distance between visual and instruction tokens. With CCA, visual tokens can better interact with instruction tokens, thereby enhancing model's perception capability and alleviating object hallucination. Without bells and whistles, our positional alignment method surpasses existing hallucination mitigation strategies by large margins on multiple object hallucination benchmarks.
The Curse of Multi-Modalities: Evaluating Hallucinations of Large Multimodal Models across Language, Visual, and Audio
Oct 16, 2024
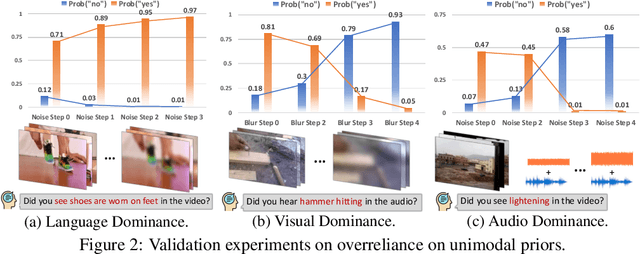

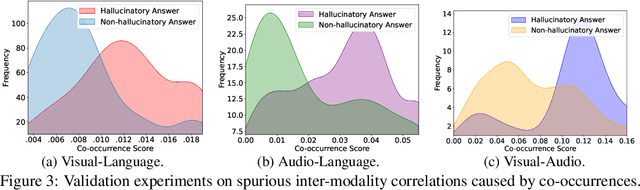
Recent advancements in large multimodal models (LMMs) have significantly enhanced performance across diverse tasks, with ongoing efforts to further integrate additional modalities such as video and audio. However, most existing LMMs remain vulnerable to hallucinations, the discrepancy between the factual multimodal input and the generated textual output, which has limited their applicability in various real-world scenarios. This paper presents the first systematic investigation of hallucinations in LMMs involving the three most common modalities: language, visual, and audio. Our study reveals two key contributors to hallucinations: overreliance on unimodal priors and spurious inter-modality correlations. To address these challenges, we introduce the benchmark The Curse of Multi-Modalities (CMM), which comprehensively evaluates hallucinations in LMMs, providing a detailed analysis of their underlying issues. Our findings highlight key vulnerabilities, including imbalances in modality integration and biases from training data, underscoring the need for balanced cross-modal learning and enhanced hallucination mitigation strategies. Based on our observations and findings, we suggest potential research directions that could enhance the reliability of LMMs.
Segment Anything with Multiple Modalities
Aug 17, 2024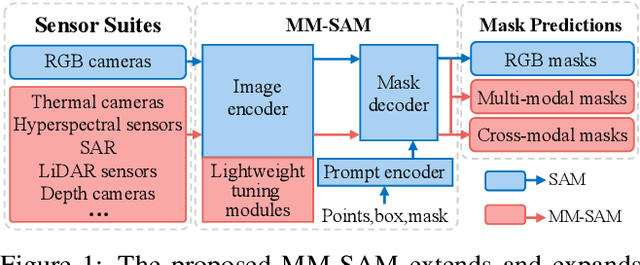


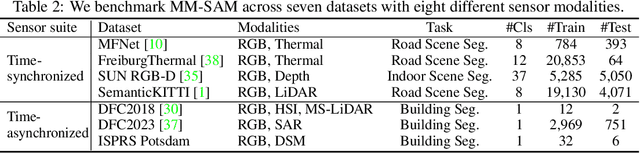
Robust and accurate segmentation of scenes has become one core functionality in various visual recognition and navigation tasks. This has inspired the recent development of Segment Anything Model (SAM), a foundation model for general mask segmentation. However, SAM is largely tailored for single-modal RGB images, limiting its applicability to multi-modal data captured with widely-adopted sensor suites, such as LiDAR plus RGB, depth plus RGB, thermal plus RGB, etc. We develop MM-SAM, an extension and expansion of SAM that supports cross-modal and multi-modal processing for robust and enhanced segmentation with different sensor suites. MM-SAM features two key designs, namely, unsupervised cross-modal transfer and weakly-supervised multi-modal fusion, enabling label-efficient and parameter-efficient adaptation toward various sensor modalities. It addresses three main challenges: 1) adaptation toward diverse non-RGB sensors for single-modal processing, 2) synergistic processing of multi-modal data via sensor fusion, and 3) mask-free training for different downstream tasks. Extensive experiments show that MM-SAM consistently outperforms SAM by large margins, demonstrating its effectiveness and robustness across various sensors and data modalities.
HENet: Hybrid Encoding for End-to-end Multi-task 3D Perception from Multi-view Cameras
Apr 03, 2024



Three-dimensional perception from multi-view cameras is a crucial component in autonomous driving systems, which involves multiple tasks like 3D object detection and bird's-eye-view (BEV) semantic segmentation. To improve perception precision, large image encoders, high-resolution images, and long-term temporal inputs have been adopted in recent 3D perception models, bringing remarkable performance gains. However, these techniques are often incompatible in training and inference scenarios due to computational resource constraints. Besides, modern autonomous driving systems prefer to adopt an end-to-end framework for multi-task 3D perception, which can simplify the overall system architecture and reduce the implementation complexity. However, conflict between tasks often arises when optimizing multiple tasks jointly within an end-to-end 3D perception model. To alleviate these issues, we present an end-to-end framework named HENet for multi-task 3D perception in this paper. Specifically, we propose a hybrid image encoding network, using a large image encoder for short-term frames and a small image encoder for long-term temporal frames. Then, we introduce a temporal feature integration module based on the attention mechanism to fuse the features of different frames extracted by the two aforementioned hybrid image encoders. Finally, according to the characteristics of each perception task, we utilize BEV features of different grid sizes, independent BEV encoders, and task decoders for different tasks. Experimental results show that HENet achieves state-of-the-art end-to-end multi-task 3D perception results on the nuScenes benchmark, including 3D object detection and BEV semantic segmentation. The source code and models will be released at https://github.com/VDIGPKU/HENet.
CAT-SAM: Conditional Tuning Network for Few-Shot Adaptation of Segmentation Anything Model
Feb 06, 2024

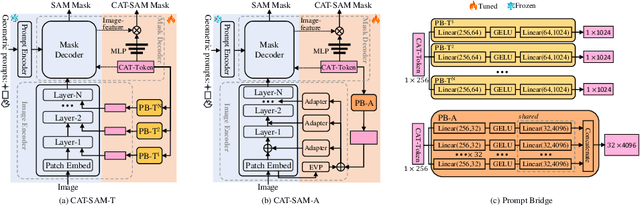
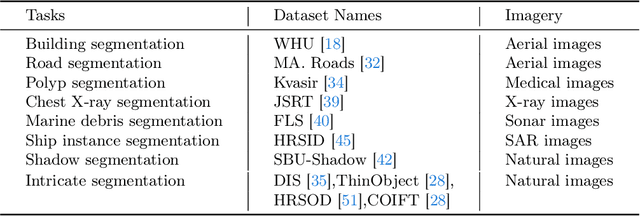
The recent Segment Anything Model (SAM) has demonstrated remarkable zero-shot capability and flexible geometric prompting in general image segmentation. However, SAM often struggles when handling various unconventional images, such as aerial, medical, and non-RGB images. This paper presents CAT-SAM, a ConditionAl Tuning network that adapts SAM toward various unconventional target tasks with just few-shot target samples. CAT-SAM freezes the entire SAM and adapts its mask decoder and image encoder simultaneously with a small number of learnable parameters. The core design is a prompt bridge structure that enables decoder-conditioned joint tuning of the heavyweight image encoder and the lightweight mask decoder. The bridging maps the prompt token of the mask decoder to the image encoder, fostering synergic adaptation of the encoder and the decoder with mutual benefits. We develop two representative tuning strategies for the image encoder which leads to two CAT-SAM variants: one injecting learnable prompt tokens in the input space and the other inserting lightweight adapter networks. Extensive experiments over 11 unconventional tasks show that both CAT-SAM variants achieve superior target segmentation performance consistently even under the very challenging one-shot adaptation setup. Project page: \url{https://xiaoaoran.github.io/projects/CAT-SAM}