 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMAGIC: Mastering Physical Adversarial Generation in Context through Collaborative LLM Agents
Paper and Code
Dec 11, 2024
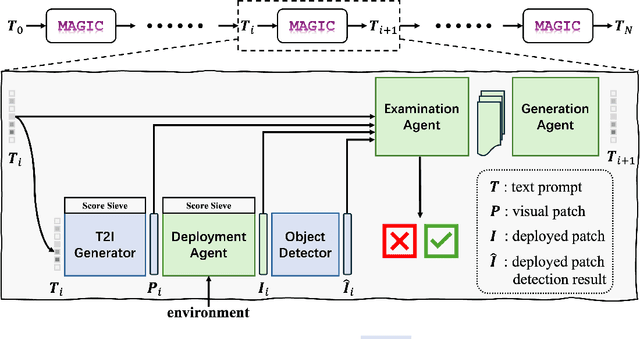

Physical adversarial attacks in driving scenarios can expose critical vulnerabilities in visual perception models. However, developing such attacks remains challenging due to diverse real-world backgrounds and the requirement for maintaining visual naturality. Building upon this challenge, we reformulate physical adversarial attacks as a one-shot patch-generation problem. Our approach generates adversarial patches through a deep generative model that considers the specific scene context, enabling direct physical deployment in matching environments. The primary challenge lies in simultaneously achieving two objectives: generating adversarial patches that effectively mislead object detection systems while determining contextually appropriate placement within the scene. We propose MAGIC (Mastering Physical Adversarial Generation In Context), a novel framework powered by multi-modal LLM agents to address these challenges. MAGIC automatically understands scene context and orchestrates adversarial patch generation through the synergistic interaction of language and vision capabilities. MAGIC orchestrates three specialized LLM agents: The adv-patch generation agent (GAgent) masters the creation of deceptive patches through strategic prompt engineering for text-to-image models. The adv-patch deployment agent (DAgent) ensures contextual coherence by determining optimal placement strategies based on scene understanding. The self-examination agent (EAgent) completes this trilogy by providing critical oversight and iterative refinement of both processes. We validate our method on both digital and physical level, \ie, nuImage and manually captured real scenes, where both statistical and visual results prove that our MAGIC is powerful and effectively for attacking wide-used object detection systems.