 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExperience-Driven Multi-Agent Systems Are Training-free Context-aware Earth Observers
Jan 30, 2026Recent advances have enabled large language model (LLM) agents to solve complex tasks by orchestrating external tools. However, these agents often struggle in specialized, tool-intensive domains that demand long-horizon execution, tight coordination across modalities, and strict adherence to implicit tool constraints. Earth Observation (EO) tasks exemplify this challenge due to the multi-modal and multi-temporal data inputs, as well as the requirements of geo-knowledge constraints (spectrum library, spatial reasoning, etc): many high-level plans can be derailed by subtle execution errors that propagate through a pipeline and invalidate final results. A core difficulty is that existing agents lack a mechanism to learn fine-grained, tool-level expertise from interaction. Without such expertise, they cannot reliably configure tool parameters or recover from mid-execution failures, limiting their effectiveness in complex EO workflows. To address this, we introduce \textbf{GeoEvolver}, a self-evolving multi-agent system~(MAS) that enables LLM agents to acquire EO expertise through structured interaction without any parameter updates. GeoEvolver decomposes each query into independent sub-goals via a retrieval-augmented multi-agent orchestrator, then explores diverse tool-parameter configurations at the sub-goal level. Successful patterns and root-cause attribution from failures are then distilled in an evolving memory bank that provides in-context demonstrations for future queries. Experiments on three tool-integrated EO benchmarks show that GeoEvolver consistently improves end-to-end task success, with an average gain of 12\% across multiple LLM backbones, demonstrating that EO expertise can emerge progressively from efficient, fine-grained interactions with the environment.
Sentipolis: Emotion-Aware Agents for Social Simulations
Jan 25, 2026LLM agents are increasingly used for social simulation, yet emotion is often treated as a transient cue, causing emotional amnesia and weak long-horizon continuity. We present Sentipolis, a framework for emotionally stateful agents that integrates continuous Pleasure-Arousal-Dominance (PAD) representation, dual-speed emotion dynamics, and emotion--memory coupling. Across thousands of interactions over multiple base models and evaluators, Sentipolis improves emotionally grounded behavior, boosting communication, and emotional continuity. Gains are model-dependent: believability increases for higher-capacity models but can drop for smaller ones, and emotion-awareness can mildly reduce adherence to social norms, reflecting a human-like tension between emotion-driven behavior and rule compliance in social simulation. Network-level diagnostics show reciprocal, moderately clustered, and temporally stable relationship structures, supporting the study of cumulative social dynamics such as alliance formation and gradual relationship change.
The Confidence Dichotomy: Analyzing and Mitigating Miscalibration in Tool-Use Agents
Jan 12, 2026Autonomous agents based on large language models (LLMs) are rapidly evolving to handle multi-turn tasks, but ensuring their trustworthiness remains a critical challenge. A fundamental pillar of this trustworthiness is calibration, which refers to an agent's ability to express confidence that reliably reflects its actual performance. While calibration is well-established for static models, its dynamics in tool-integrated agentic workflows remain underexplored. In this work, we systematically investigate verbalized calibration in tool-use agents, revealing a fundamental confidence dichotomy driven by tool type. Specifically, our pilot study identifies that evidence tools (e.g., web search) systematically induce severe overconfidence due to inherent noise in retrieved information, while verification tools (e.g., code interpreters) can ground reasoning through deterministic feedback and mitigate miscalibration. To robustly improve calibration across tool types, we propose a reinforcement learning (RL) fine-tuning framework that jointly optimizes task accuracy and calibration, supported by a holistic benchmark of reward designs. We demonstrate that our trained agents not only achieve superior calibration but also exhibit robust generalization from local training environments to noisy web settings and to distinct domains such as mathematical reasoning. Our results highlight the necessity of domain-specific calibration strategies for tool-use agents. More broadly, this work establishes a foundation for building self-aware agents that can reliably communicate uncertainty in high-stakes, real-world deployments.
Toward Global Large Language Models in Medicine
Jan 05, 2026Despite continuous advances in medical technology, the global distribution of health care resources remains uneven. The development of large language models (LLMs) has transformed the landscape of medicine and holds promise for improving health care quality and expanding access to medical information globally. However, existing LLMs are primarily trained on high-resource languages, limiting their applicability in global medical scenarios. To address this gap, we constructed GlobMed, a large multilingual medical dataset, containing over 500,000 entries spanning 12 languages, including four low-resource languages. Building on this, we established GlobMed-Bench, which systematically assesses 56 state-of-the-art proprietary and open-weight LLMs across multiple multilingual medical tasks, revealing significant performance disparities across languages, particularly for low-resource languages. Additionally, we introduced GlobMed-LLMs, a suite of multilingual medical LLMs trained on GlobMed, with parameters ranging from 1.7B to 8B. GlobMed-LLMs achieved an average performance improvement of over 40% relative to baseline models, with a more than threefold increase in performance on low-resource languages. Together, these resources provide an important foundation for advancing the equitable development and application of LLMs globally, enabling broader language communities to benefit from technological advances.
Geo3DVQA: Evaluating Vision-Language Models for 3D Geospatial Reasoning from Aerial Imagery
Dec 21, 2025Three-dimensional geospatial analysis is critical for applications in urban planning, climate adaptation, and environmental assessment. However, current methodologies depend on costly, specialized sensors, such as LiDAR and multispectral sensors, which restrict global accessibility. Additionally, existing sensor-based and rule-driven methods struggle with tasks requiring the integration of multiple 3D cues, handling diverse queries, and providing interpretable reasoning. We present Geo3DVQA, a comprehensive benchmark that evaluates vision-language models (VLMs) in height-aware 3D geospatial reasoning from RGB imagery alone. Unlike conventional sensor-based frameworks, Geo3DVQA emphasizes realistic scenarios integrating elevation, sky view factors, and land cover patterns. The benchmark comprises 110k curated question-answer pairs across 16 task categories, including single-feature inference, multi-feature reasoning, and application-level analysis. Through a systematic evaluation of ten state-of-the-art VLMs, we reveal fundamental limitations in RGB-to-3D spatial reasoning. Our results further show that domain-specific instruction tuning consistently enhances model performance across all task categories, including height-aware and open-ended, application-oriented reasoning. Geo3DVQA provides a unified, interpretable framework for evaluating RGB-based 3D geospatial reasoning and identifies key challenges and opportunities for scalable 3D spatial analysis. The code and data are available at https://github.com/mm1129/Geo3DVQA.
Retrieval-Augmented Generation in Medicine: A Scoping Review of Technical Implementations, Clinical Applications, and Ethical Considerations
Nov 13, 2025The rapid growth of medical knowledge and increasing complexity of clinical practice pose challenges. In this context, large language models (LLMs) have demonstrated value; however, inherent limitations remain. Retrieval-augmented generation (RAG) technologies show potential to enhance their clinical applicability. This study reviewed RAG applications in medicine. We found that research primarily relied on publicly available data, with limited application in private data. For retrieval, approaches commonly relied on English-centric embedding models, while LLMs were mostly generic, with limited use of medical-specific LLMs. For evaluation, automated metrics evaluated generation quality and task performance, whereas human evaluation focused on accuracy, completeness, relevance, and fluency, with insufficient attention to bias and safety. RAG applications were concentrated on question answering, report generation, text summarization, and information extraction. Overall, medical RAG remains at an early stage, requiring advances in clinical validation, cross-linguistic adaptation, and support for low-resource settings to enable trustworthy and responsible global use.
Taming Object Hallucinations with Verified Atomic Confidence Estimation
Nov 12, 2025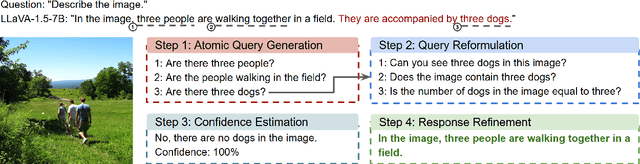

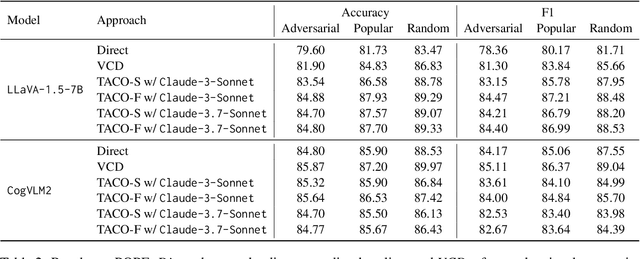
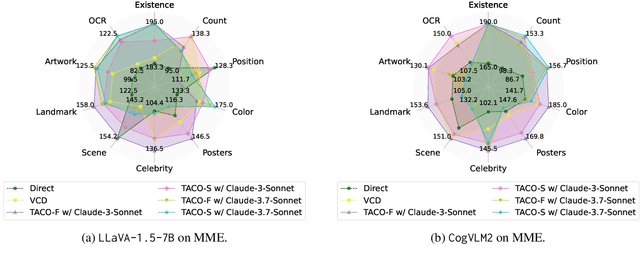
Multimodal Large Language Models (MLLMs) often suffer from hallucinations, particularly errors in object existence, attributes, or relations, which undermine their reliability. We introduce TACO (Verified Atomic Confidence Estimation), a simple framework that mitigates hallucinations through self-verification and confidence calibration without relying on external vision experts. TACO decomposes responses into atomic queries, paraphrases them to reduce sensitivity to wording, and estimates confidence using self-consistency (black-box) or self-confidence (gray-box) aggregation, before refining answers with a language model. Experiments on five benchmarks (POPE, MME, HallusionBench, AMBER, and MM-Hal Bench) with two MLLMs (\texttt{LLaVA-1.5-7B} and \texttt{CogVLM2}) show that TACO consistently outperforms direct prompting and Visual Contrastive Decoding, reduces systematic biases, and improves confidence calibration, demonstrating its effectiveness in enhancing the faithfulness of MLLMs.
DynamicVL: Benchmarking Multimodal Large Language Models for Dynamic City Understanding
May 27, 2025Multimodal large language models have demonstrated remarkable capabilities in visual understanding, but their application to long-term Earth observation analysis remains limited, primarily focusing on single-temporal or bi-temporal imagery. To address this gap, we introduce DVL-Suite, a comprehensive framework for analyzing long-term urban dynamics through remote sensing imagery. Our suite comprises 15,063 high-resolution (1.0m) multi-temporal images spanning 42 megacities in the U.S. from 2005 to 2023, organized into two components: DVL-Bench and DVL-Instruct. The DVL-Bench includes seven urban understanding tasks, from fundamental change detection (pixel-level) to quantitative analyses (regional-level) and comprehensive urban narratives (scene-level), capturing diverse urban dynamics including expansion/transformation patterns, disaster assessment, and environmental challenges. We evaluate 17 state-of-the-art multimodal large language models and reveal their limitations in long-term temporal understanding and quantitative analysis. These challenges motivate the creation of DVL-Instruct, a specialized instruction-tuning dataset designed to enhance models' capabilities in multi-temporal Earth observation. Building upon this dataset, we develop DVLChat, a baseline model capable of both image-level question-answering and pixel-level segmentation, facilitating a comprehensive understanding of city dynamics through language interactions.
DisasterM3: A Remote Sensing Vision-Language Dataset for Disaster Damage Assessment and Response
May 27, 2025Large vision-language models (VLMs) have made great achievements in Earth vision. However, complex disaster scenes with diverse disaster types, geographic regions, and satellite sensors have posed new challenges for VLM applications. To fill this gap, we curate a remote sensing vision-language dataset (DisasterM3) for global-scale disaster assessment and response. DisasterM3 includes 26,988 bi-temporal satellite images and 123k instruction pairs across 5 continents, with three characteristics: 1) Multi-hazard: DisasterM3 involves 36 historical disaster events with significant impacts, which are categorized into 10 common natural and man-made disasters. 2)Multi-sensor: Extreme weather during disasters often hinders optical sensor imaging, making it necessary to combine Synthetic Aperture Radar (SAR) imagery for post-disaster scenes. 3) Multi-task: Based on real-world scenarios, DisasterM3 includes 9 disaster-related visual perception and reasoning tasks, harnessing the full potential of VLM's reasoning ability with progressing from disaster-bearing body recognition to structural damage assessment and object relational reasoning, culminating in the generation of long-form disaster reports. We extensively evaluated 14 generic and remote sensing VLMs on our benchmark, revealing that state-of-the-art models struggle with the disaster tasks, largely due to the lack of a disaster-specific corpus, cross-sensor gap, and damage object counting insensitivity. Focusing on these issues, we fine-tune four VLMs using our dataset and achieve stable improvements across all tasks, with robust cross-sensor and cross-disaster generalization capabilities.
Seeing is Believing, but How Much? A Comprehensive Analysis of Verbalized Calibration in Vision-Language Models
May 26, 2025Uncertainty quantification is essential for assessing the reliability and trustworthiness of modern AI systems. Among existing approaches, verbalized uncertainty, where models express their confidence through natural language, has emerged as a lightweight and interpretable solution in large language models (LLMs). However, its effectiveness in vision-language models (VLMs) remains insufficiently studied. In this work, we conduct a comprehensive evaluation of verbalized confidence in VLMs, spanning three model categories, four task domains, and three evaluation scenarios. Our results show that current VLMs often display notable miscalibration across diverse tasks and settings. Notably, visual reasoning models (i.e., thinking with images) consistently exhibit better calibration, suggesting that modality-specific reasoning is critical for reliable uncertainty estimation. To further address calibration challenges, we introduce Visual Confidence-Aware Prompting, a two-stage prompting strategy that improves confidence alignment in multimodal settings. Overall, our study highlights the inherent miscalibration in VLMs across modalities. More broadly, our findings underscore the fundamental importance of modality alignment and model faithfulness in advancing reliable multimodal systems.