 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSentipolis: Emotion-Aware Agents for Social Simulations
Jan 25, 2026LLM agents are increasingly used for social simulation, yet emotion is often treated as a transient cue, causing emotional amnesia and weak long-horizon continuity. We present Sentipolis, a framework for emotionally stateful agents that integrates continuous Pleasure-Arousal-Dominance (PAD) representation, dual-speed emotion dynamics, and emotion--memory coupling. Across thousands of interactions over multiple base models and evaluators, Sentipolis improves emotionally grounded behavior, boosting communication, and emotional continuity. Gains are model-dependent: believability increases for higher-capacity models but can drop for smaller ones, and emotion-awareness can mildly reduce adherence to social norms, reflecting a human-like tension between emotion-driven behavior and rule compliance in social simulation. Network-level diagnostics show reciprocal, moderately clustered, and temporally stable relationship structures, supporting the study of cumulative social dynamics such as alliance formation and gradual relationship change.
A Visual Semantic Adaptive Watermark grounded by Prefix-Tuning for Large Vision-Language Model
Jan 12, 2026Watermarking has emerged as a pivotal solution for content traceability and intellectual property protection in Large Vision-Language Models (LVLMs). However, vision-agnostic watermarks introduce visually irrelevant tokens and disrupt visual grounding by enforcing indiscriminate pseudo-random biases, while some semantic-aware methods incur prohibitive inference latency due to rejection sampling. In this paper, we propose the VIsual Semantic Adaptive Watermark (VISA-Mark), a novel framework that embeds detectable signals while strictly preserving visual fidelity. Our approach employs a lightweight, efficiently trained prefix-tuner to extract dynamic Visual-Evidence Weights, which quantify the evidentiary support for candidate tokens based on the visual input. These weights guide an adaptive vocabulary partitioning and logits perturbation mechanism, concentrating watermark strength specifically on visually-supported tokens. By actively aligning the watermark with visual evidence, VISA-Mark effectively maintains visual fidelity. Empirical results confirm that VISA-Mark outperforms conventional methods with a 7.8% improvement in visual consistency (Chair-I) and superior semantic fidelity. The framework maintains highly competitive detection accuracy (96.88% AUC) and robust attack resilience (99.3%) without sacrificing inference efficiency, effectively establishing a new standard for reliability-preserving multimodal watermarking.
Table-R1: Inference-Time Scaling for Table Reasoning
May 29, 2025In this work, we present the first study to explore inference-time scaling on table reasoning tasks. We develop and evaluate two post-training strategies to enable inference-time scaling: distillation from frontier model reasoning traces and reinforcement learning with verifiable rewards (RLVR). For distillation, we introduce a large-scale dataset of reasoning traces generated by DeepSeek-R1, which we use to fine-tune LLMs into the Table-R1-SFT model. For RLVR, we propose task-specific verifiable reward functions and apply the GRPO algorithm to obtain the Table-R1-Zero model. We evaluate our Table-R1-series models across diverse table reasoning tasks, including short-form QA, fact verification, and free-form QA. Notably, the Table-R1-Zero model matches or exceeds the performance of GPT-4.1 and DeepSeek-R1, while using only a 7B-parameter LLM. It also demonstrates strong generalization to out-of-domain datasets. Extensive ablation and qualitative analyses reveal the benefits of instruction tuning, model architecture choices, and cross-task generalization, as well as emergence of essential table reasoning skills during RL training.
DocMath-Eval: Evaluating Numerical Reasoning Capabilities of LLMs in Understanding Long Documents with Tabular Data
Nov 16, 2023
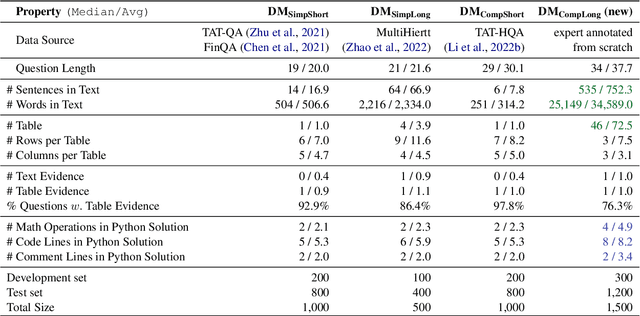

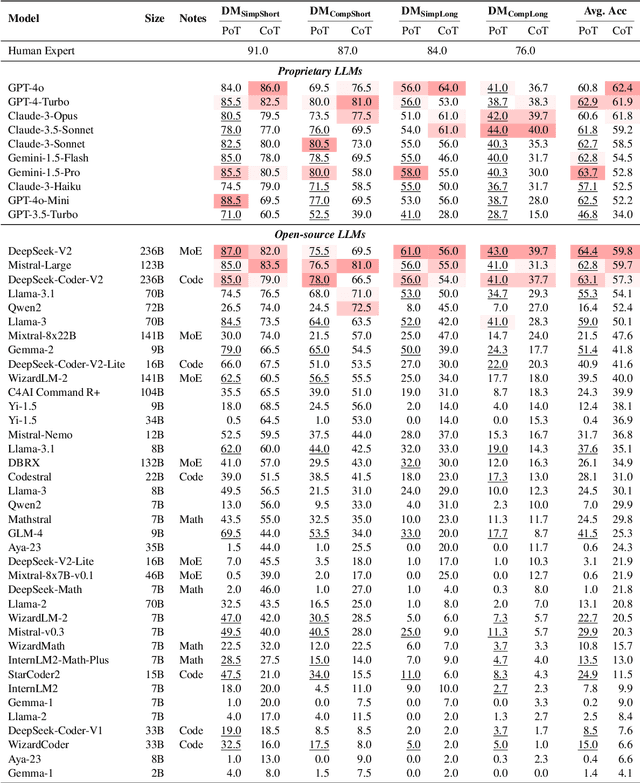
Recent LLMs have demonstrated remarkable performance in solving exam-like math word problems. However, the degree to which these numerical reasoning skills are effective in real-world scenarios, particularly in expert domains, is still largely unexplored. This paper introduces DocMath-Eval, a comprehensive benchmark specifically designed to evaluate the numerical reasoning and problem-solving capabilities of LLMs in the context of understanding and analyzing financial documents containing both text and tables. We evaluate a wide spectrum of 19 LLMs, including those specialized in coding and finance. We also incorporate different prompting strategies (i.e., Chain-of-Thoughts and Program-of-Thoughts) to comprehensively assess the capabilities and limitations of existing LLMs in DocMath-Eval. We found that, although the current best-performing system (i.e., GPT-4), can perform well on simple problems such as calculating the rate of increase in a financial metric within a short document context, it significantly lags behind human experts in more complex problems grounded in longer contexts. We believe DocMath-Eval can be used as a valuable benchmark to evaluate LLMs' capabilities to solve challenging numerical reasoning problems in expert domains. We will release the benchmark and code at https://github.com/yale-nlp/DocMath-Eval.